1. 数据标准化:
求均值标准差:
(python) sklearn.preprocessing.scale(X)
(scala) import org.apache.spark.ml.feature.StandardScaler
均值标准差 = (X - mean)/std 得到的结果是,对于每个属性/每列来说所有数据都聚集在0附近,方差为1。
>>> 计算时对每个属性/每列分别进行
2. 极大似然估计:
参考链接:https://www.cnblogs.com/xing901022/p/8418894.html
参数theta对于某一类样本组成的数据集D的似然函数:
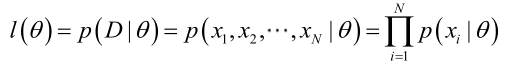
极大似然估计:用于求其中的参数theta值。就是试图在参数theta的所有可能取值中,找到一个能使数据出现的“可能性”最大的值。
3. 交叉验证(CV):
参考链接:https://blog.csdn.net/dream_angel_z/article/details/47110077
交叉验证(Cross Validation)是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(training set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),求这小部分样本的预测误差或者预测精度【把每个样本的预测误差平方加和,称为PRESS(predicted Error Sum of Squares)】,以此来做为评价分类器的性能指标。这个过程迭代K次,即K折交叉。
目的:
用cross validation校验每个主成分下的PRESS值,选择PRESS值小的主成分数或PRESS值不再变小时对应的模型。
3.1 常见的交叉验证形式:
1、Hold-Out Method
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。此种方法的好处的处理简单,只需随机把原始数据分为两组即可,其实严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性。
2、Double Cross Validation(2-fold Cross Validation,记为2-CV)
做法是将数据集分成两个相等大小的子集,进行两回合的分类器训练。在第一回合中,一个子集作为training set,另一个便作为testing set;在第二回合中,则将training set与testing set对换后,再次训练分类器,而其中我们比较关心的是两次testing sets的辨识率。不过在实务上2-CV并不常用,主要原因是training set样本数太少,通常不足以代表母体样本的分布,导致testing阶段辨识率容易出现明显落差。此外,2-CV中分子集的变异度大,往往无法达到“实验过程必须可以被复制”的要求。
3、K-fold Cross Validation(K-折交叉验证,记为K-CV)
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。
4、Leave-One-Out Cross Validation(记为LOO-CV)
如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。相比于前面的K-CV,LOO-CV有两个明显的优点:
(1)每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
(2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间。
在scikit-learn中有CrossValidation的实现代码,地址: scikit-learn官网crossvalidation文档
使用方法: 调用cross_val_score进行5折交叉验证来估计线性内核支持向量机在虹膜数据集上的准确性,默认的分值是“F1值”:
>>> from sklearn.model_selection import cross_val_score
>>> clf = svm.SVC(kernel='linear', C=1)
>>> scores = cross_val_score(clf, iris.data, iris.target, cv=5)
>>> scores
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
因此,得分估计的平均得分 + 0.2%的上下浮动误差:
>>> print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
Accuracy: 0.98 (+/- 0.03)
cross_validate函数在两个方面与cross_val_score不同 -
1)它允许指定多个评估指标。
2)除了测试分数之外,它还返回包含拟合时间,分数时间(以及可选的训练分数以及拟合估计值)的字典。
>>> from sklearn.model_selection import cross_validate
>>> from sklearn.metrics import recall_score
>>> scoring = ['precision_macro', 'recall_macro']
>>> clf = svm.SVC(kernel='linear', C=1, random_state=0)
>>> scores = cross_validate(clf, iris.data, iris.target, scoring=scoring,
... cv=5)
>>> sorted(scores.keys())
['fit_time', 'score_time', 'test_precision_macro', 'test_recall_macro']
>>> scores['test_recall_macro']
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
4. 监督学习的基础知识
参考链接:https://www.jianshu.com/p/7467e616f227
4.1 损失函数
对于回归问题,我们常用的损失函数是MSE,即:

对于分类问题,使用了Sigmoid函数表示预测概率时,我们常用的损失函数是对数损失函数:

5. NP完全问题
参考链接:https://www.jianshu.com/p/dcb0b52f4935
在学习决策树的时候,我们知道,其一大特点是:寻找最佳的决策树是NP完成问题。什么是NP完全问题呢?—— 这里的NP其实是Non-deterministic Polynomial的缩写,即多项式复杂程度的非确定性问题
多项式时间则是指O(1)、O(logN)、O(N^2)等这类可用多项式表示的时间复杂度,通常我们认为计算机可解决的问题只限于多项式时间内。而O(2^N)、O(N!)这类非多项式级别的问题,其复杂度往往已经到了计算机都接受不了的程度。
所有非确定性多项式时间内可解的判定问题构成NP类问题
NP类问题将问题分为求解和验证两个阶段,问题的求解是非确定性的,无法在多项式时间内得到答案,而问题的验证却是确定的,能够在多项式时间里确定结果.。
比如:是否存在一个公式可以计算下一个质数是多少?这个问题的答案目前是无法直接计算出来的,但是如果某人给出了一个公式,我们却可以在多项式时间里对这个公式进行验证。
NP中的一类比较特殊的问题,这类问题中每个问题的复杂度与整个类的复杂度有关联性,假如其中任意一个问题在多项式时间内可解的,则这一类问题都是多项式时间可解。这些问题被称为NP完全问题。
决策树的NP完全问题
在决策树算法中,寻找最优决策树是一个NP完全问题。决策树的这一特点,说明我们无法利用计算机在多项式时间内,找出全局最优的解。
也正因为如此,大多数决策树算法都采用启发式的算法,如贪心算法,来指导对假设空间的搜索。可以说,决策树最后的结果,是在每一步、每一个节点上做的局部最优选择。决策树得到的结果,是没法保证为全局最优的。
6. 生成模型和判别模型
▶ 生成方法:由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。
典型的生成模型有 朴素贝叶斯法、隐马尔可夫模型。
▶ 判别方法:由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。
典型的判别模型有 k近邻法、感知机、决策树、逻辑回归、最大熵模型、支持向量机、提升方法和条件随机场
▶ 区别:
生成方法的特点:
1. 可以还原出联合概率分布P(X,Y),而判别方法不行
2. 生成方法的学习收敛速度更快,即当样本容量增加时,学习的模型可以更快地收敛于真实模型
3. 当存在隐变量时,仍可以用生成方法,此时判别方法不能用
判别方法的特点:
1. 直接学习的是条件概率分布P(Y|X)或决策函数f(X),直接面对预测,往往学习准确率高
2. 由于直接学习P(Y|X)或f(X),可以对数据进行各种抽象、定义特征并使用特征,因此可以简化学习问题