临近学期末,我们最后一个比较重要的任务就是做数据结构课设,我对于这戏课设还是比较重视的,因为这是对本学期我所学数据结构中算法一次的应用机会。本来想着挺难的,但做了之后吗,觉得没想像的那么难。做完之后就是一堆报告还有期末考,没机会总结。今天是放假第一天,我下午一点才起来,为了弥补内心的愧疚之感,做点事情吧!就总结下数据结构课设!
我主要想总结的东西列在下面了。就照这个写吧!
- 【1】
必选建立哈夫曼树,并能实现对文本数据的压缩与解压。- 文件中中文频率的统计。
- 应用编码压缩源文件。
- 解压时读取压缩文件,并将压缩文件中的信息还原为源文件中的信息。
- 【2】产生随机迷宫,并找到从入口到出口的最短通路。
- 关于BFS那些事(随机迷宫的产生是套网上的算法)。
- 【3】实现一个学校的导航系统。
- 边集和地点的存储管理。
- 最短路径再探索。
- 【4】实现效果演示。
文件压缩与解压
在这一部分,我主要说一下往文本中压缩信息和解压信息的一些关键解决策略。不会再说建立哈夫曼树的算法了。
- 中文(包括标点符号)的统计
我所用的系统是ubuntu18.10,在这个系统里面utf-8编码一个汉字是3个字节,每个字节对应一个Ascll码。因为在读取源文件时是一个字节一个字节读的所以,所以得有个判断读的字符是否是构成汉字的字符的标准,而我们知道组成汉字的Ascll码要是转换成unsigned char型就都是大于等于128的,所以我们记录字符频率时只要读到Ascll码为128及以上的字符,就设置一个长度为3的字符数组存接下来连续读三次的字符,当然要是英文字符的话还是用这个数组存。读完一个汉字或英文之后,将数组转化成一个string对象,检查这汉字是否已经统计,就只能遍历已经统计过所有的字符,不存在的话加入容器,给该字符串频率自增1;否则就给相应的字符串频率自增1。
- 应用编码压缩源文件
编码源文件还是要一个个读取源文件的字符,创建压缩文件,以二进制写的形式每次写一个字符长度的数据。
如上所示,因为我们的目的是要按照编码把文件中的字符装换成二进制字节位,然后将这个字节存到文件中,所以我们需要一个长度为8的字符数组arr来存储这些编码,然后将数组中的01编码转换成位中的01。我们得在需要一个字符ch,存储arr中的01转化成位中的二进制01的结果,不如读到A将编码存在第数组中,发现数组只存了5个元素,没满?则读取下一个字符“畅”,提取前三个到数组中,再将数组转换成二进制位中的01,就是以上表达式,转换后,将字符ch以二进制的形式写入到二进制文件中,再清空arr并初始化ch继续读写。(
最后一个字节可能不是所有编码都是有效的,要将有效的长度记录下来,解压时才能准确解出来。同时再压缩时记录文件中的有效字节数)
- 解压时读取压缩文件
解压文件当然还是看你原来是怎么压得,现在就怎么解,创建文本文件,没翻译出来一个汉字或英文,就写入文件。
以二进制形式读取压缩文件,每次一个字节长度,并与ch1中的元素做与运算,根据每次返回的0或1决定走哈夫曼树的左或者右。直到走到叶子节点,将数据写到解压文件中,要是一个字节没与运算完,就从当前的数组下标继续与,与完一个字节后,再从压缩文件中读取一个字节,从数组下标为0的地方作与运算。就此不断重复,直到将所有有效字节与完,在与最后一个字节时,根据之前记录的长度与即可!最后整个压缩文件将被解压完成啦。
随机迷宫
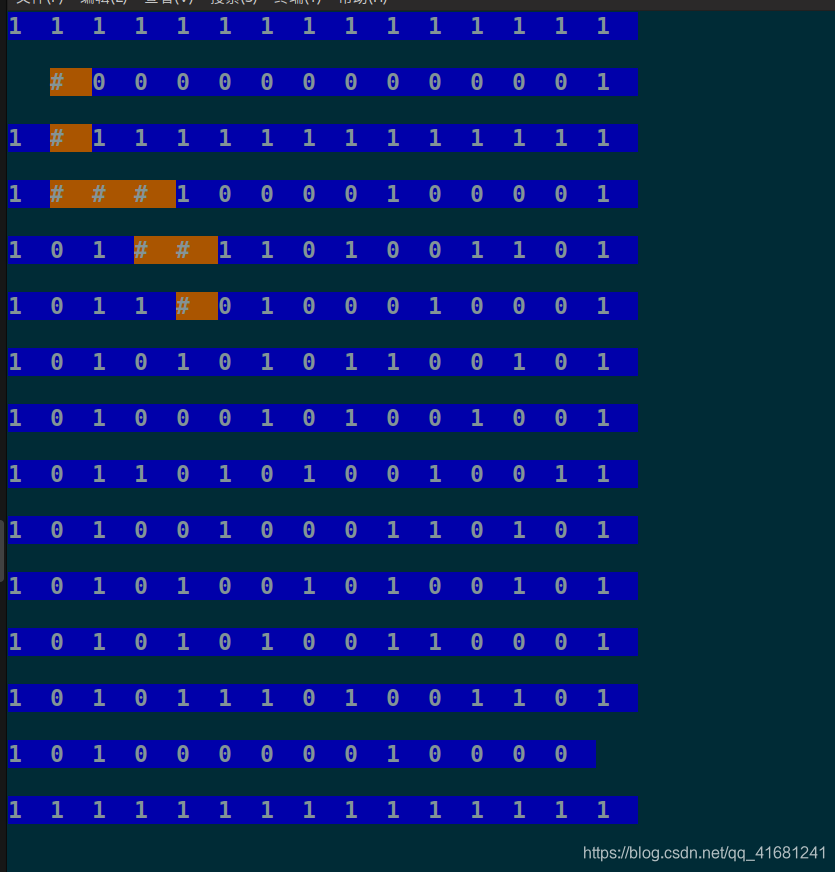
走迷宫就是BFS算法的典型应用,主要实现统计路径的过程,BFS算法应用队列,从起点出发,查询与其相邻的节点是否满足指定条件,满足就加入到队列中,然后弹出和访问队头元素,每次与到满足要求的节点就将该节点的上一个节点记录到该节点中。之后的工作就这样不断重复,直到判断走到终点,然后又从终点出发,不断找他的上一个节点,找到起点即可,这个过程应该用链表的头插法记录下来,则链表中最终存的就是从迷宫起点到终点的最短路径。最后设置sleep 函数和clear系统调用显示最短路径走的过程。
刚开始产生迷宫使用随机数产生的,但是当迷宫规模很大时,就不行了,大部分情况下是没有通路的,老师提示我在网上有相关算法,然后就做”搬砖“的动作套用了网上的算法,没有深入研究就直接修改了网上的代码让它按要求产生有通路的迷宫,这个算是搬砖吧!
校园导航
- 边集和地点集的存储和管理
地点集
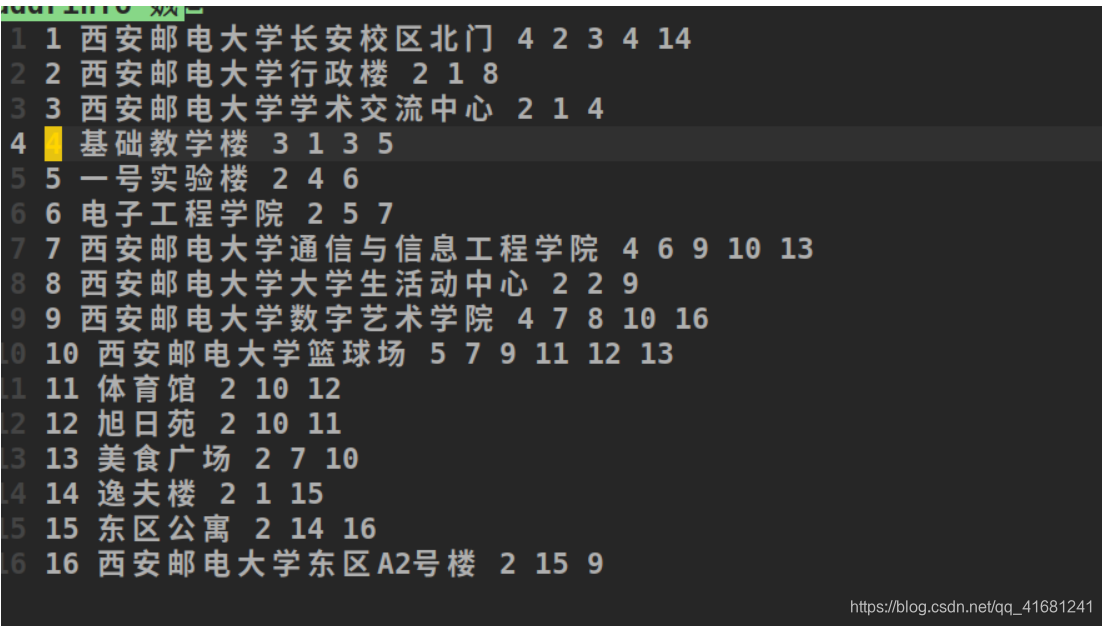
地点集第一列存的是各个地点的id,第二列是名称,第三列是与其相邻的地点的个数,紧接着后面的是相邻的地点的id。每次进入程序都要将这些信息存到容器中。然后提供一些服务。
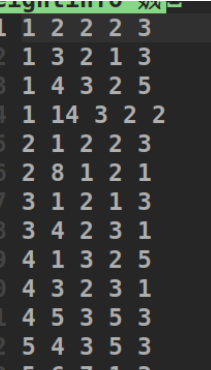
边集
这个就是模拟临界矩阵来存储边集,分别是行列坐标,一些可有可无的权值。进入程序初始化时要将这些信息录入到容器中。
- 最短路径再探究
迪杰斯特拉算法主要需要以下数据:
tag标记:标记该节点最短路径是否已经确定。
邻接矩阵map(可由邻接表转化):根据节点id存数据,即就是如果节点位于第n行则id就是n,id不能是0。
previous数组:记录当前的节点的上一个节点,若为id1的起点可设置precious[id1]=-1,在之后作为判断起点的条件。
dist数组:存各个节点到起点的最短距离。
算法实现步骤,要是讲的话,说的太罗嗦就毁博客了,我推荐一个视频,老师讲的很清楚,是人都能听懂的迪杰斯特拉算法,这不是做广告哈!我和这个老师不是亲戚!纯粹推技术的。
实现效果演示
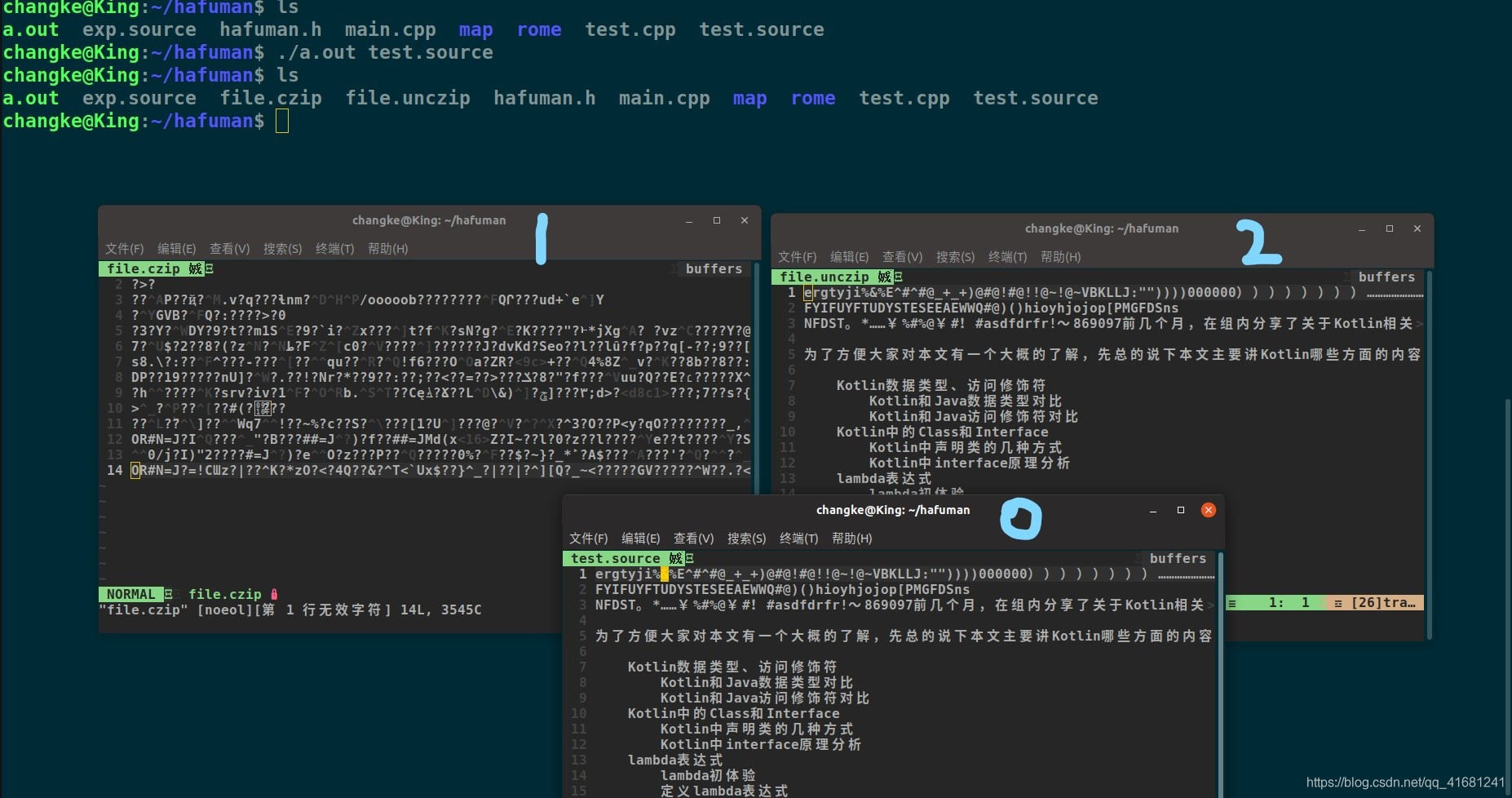
文件压缩与解压:
.source后缀时源文件,.czip是压缩文件,.unczip是解压文件,文件大小可以进行对比,确实实现了压缩的效果
下面是分别是1.压缩文件,2.解压文件,0.源文件文件中的内容
迷宫
迷宫的存储首行存的是迷宫规模信息
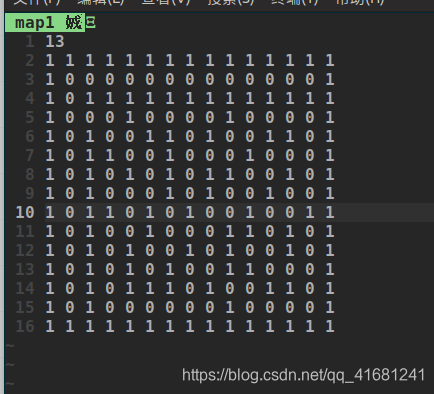
走迷宫(图太丑)
校园导航
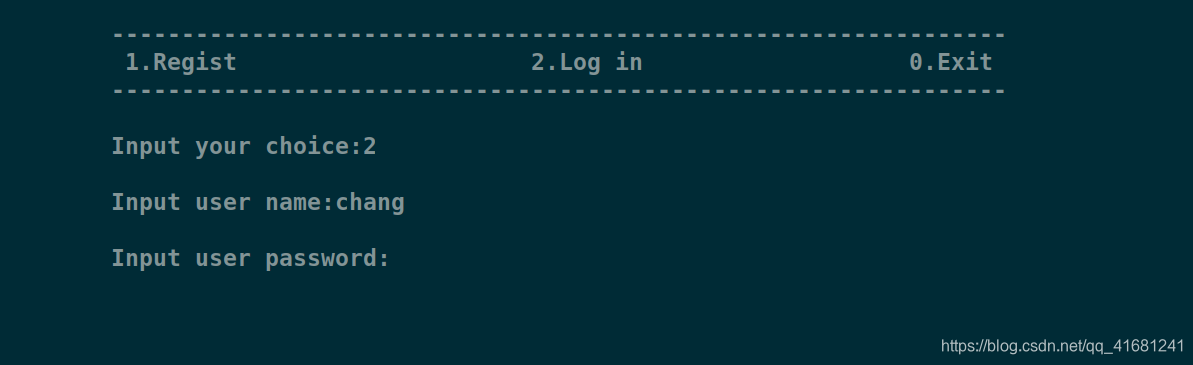
地点信息查询

最短路径查找(中间的数字是previous里面的值,不必在意)

本次数据结构课设完了,这是所有源代码