用numpy求解方程组
线性代数中比较常见的问题之一是求解矩阵向量方程。 这是一个例子。 我们寻找解决方程的向量x
A x = b
当
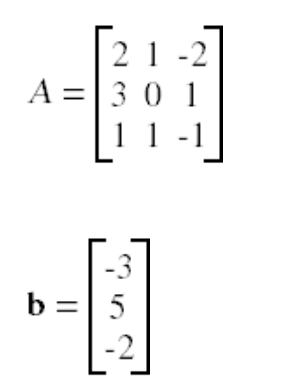
我们首先构建A和b的数组
A = np.array([[2,1,-2],[3,0,1],[1,1,-1]])
b = np.transpose(np.array([[-3,5,-2]])
为了解决这个系统
x = np.linalg.solve(A,b)
应用:多元线性回归
在多元回归问题中,我们寻找一种能够将输入数据点映射到结果值的函数。 每个数据点是特征向量(x1,x2,…,xm),由两个或多个捕获输入的各种特征的数据值组成。为了表示所有输入数据以及输出值的向量,我们设置了输入矩阵X和输出向量 y:

在简单的最小二乘线性回归模型中,我们寻找向量β,使得乘积Xβ最接近结果向量 y。
一旦我们构建了β向量,我们就可以使用它将输入数据映射到预测结果。 给定表单中的输入向量

我们可以计算预测结果值
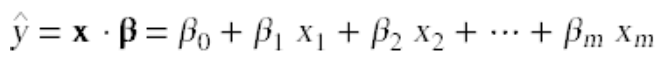
计算β向量的公式是
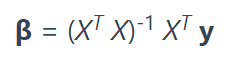
在我们的下一个示例程序中,我将使用numpy构造适当的矩阵和向量并求解β向量。一旦我们解决了β,我们将使用它来预测我们最初从输入数据集中遗漏的一些测试数据点。
假设我们在numpy中构造了输入矩阵X和结果向量y,下面的代码将计算β向量:
Xt = np.transpose(X)
XtX = np.dot(Xt,X)
Xty = np.dot(Xt,y)
beta = np.linalg.solve(XtX,Xty)
最后一行使用 np.linalg.solve计算β,因为等式是:
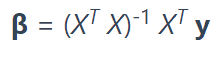
在数学上等价于方程组:
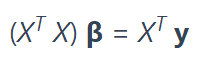
具体实例应用
我将用于此示例的数据集是Windsor房价数据集,其中包含有关安大略省温莎市区房屋销售的信息。 输入变量涵盖了可能对房价产生影响的一系列因素,例如批量大小,卧室数量以及各种设施的存在。此处提供具有完整数据集的CSV文件。我从这个网站下载了数据集,该网站提供了大量涵盖大量主题的数据集。
具有完整数据集的CSV文件:http://www2.lawrence.edu/fast/GREGGJ/Python/numpy/Housing.csv
数据集:https://vincentarelbundock.github.io/Rdatasets/datasets.html
这里现在是示例程序的源代码。
import csv
import numpy as np
def readData():
X = []
y = []
with open('Housing.csv') as f:
rdr = csv.reader(f)
# Skip the header row
next(rdr)
# Read X and y
for line in rdr:
xline = [1.0]
for s in line[:-1]:
xline.append(float(s))
X.append(xline)
y.append(float(line[-1]))
return (X,y)
X0,y0 = readData()
# Convert all but the last 10 rows of the raw data to numpy arrays
d = len(X0)-10
X = np.array(X0[:d])
y = np.transpose(np.array([y0[:d]]))
# Compute beta`在这里插入代码片`
Xt = np.transpose(X)
XtX = np.dot(Xt,X)
Xty = np.dot(Xt,y)
beta = np.linalg.solve(XtX,Xty)
print(beta)
# Make predictions for the last 10 rows in the data set
for data,actual in zip(X0[d:],y0[d:]):
x = np.array([data])
prediction = np.dot(x,beta)
print('prediction = '+str(prediction[0,0])+' actual = '+str(actual))
原始数据集包含500多个条目 为了测试线性回归模型所做预测的准确性,我们使用除最后10个数据条目之外的所有数据条目来构建回归模型并计算β。一旦我们构建了β向量,我们就用它来预测最后10个输入值,然后将预测的房价与数据集中的实际房价进行比较。
以下是该计划产生的产出:
[[ -4.14106096e+03]
[ 3.55197583e+00]
[ 1.66328263e+03]
[ 1.45465644e+04]
[ 6.77755381e+03]
[ 6.58750520e+03]
[ 4.44683380e+03]
[ 5.60834856e+03]
[ 1.27979572e+04]
[ 1.24091640e+04]
[ 4.19931185e+03]
[ 9.42215457e+03]]
prediction = 97360.6550969 actual = 82500.0
prediction = 71774.1659014 actual = 83000.0
prediction = 92359.0891976 actual = 84000.0
prediction = 77748.2742379 actual = 85000.0
prediction = 91015.5903066 actual = 85000.0
prediction = 97545.1179047 actual = 91500.0
prediction = 97360.6550969 actual = 94000.0
prediction = 106006.800756 actual = 103000.0
prediction = 92451.6931269 actual = 105000.0
prediction = 73458.2949381 actual = 105000.0
总体而言,预测并不是非常好,但是一些预测有点接近正确。