一、存储过程
存储过程的基本格式如下:
-- 声明结束符 -- 创建存储过程 DELIMITER $ -- 声明存储过程的结束符 CREATE PROCEDURE pro_test() --存储过程名称(参数列表) BEGIN -- 可以写多个sql语句; -- sql语句+流程控制 SELECT * FROM employee; END $ -- 结束 结束符 -- 执行存储过程 CALL pro_test(); -- CALL 存储过程名称(参数); -- 删除存储过程 DROP PROCEDURE pro_test; 参数: IN: 表示输入参数,可以携带数据带存储过程中 OUT: 表示输出参数,可以从存储过程中返回结果 INOUT: 表示输入输出参数,既可以输入功能,也可以输出功能
1. 带有输入参数的存储过程
需求:传入一个员工的id,查询员工信息
DELIMITER $ CREATE PROCEDURE pro_findById(IN eid INT) -- IN: 输入参数 BEGIN SELECT * FROM employee WHERE id=eid; END $ -- 调用 CALL pro_findById(4);
2. 带有输出参数的存储过程
DELIMITER $ CREATE PROCEDURE pro_testOut(OUT str VARCHAR(20)) -- OUT:输出参数 BEGIN -- 给参数赋值 SET str='hellojava'; END $
如何接受返回参数的值呢?这里涉及到MySQL的变量
MySQL变量一共有三种:
全局变量
全局变量又叫内置变量,是mysql数据库内置的变量 ,对所有连接都起作用。
查看所有全局变量: show variables
查看某个全局变量: select @@变量名
修改全局变量: set 变量名=新值
character_set_client: mysql服务器的接收数据的编码
character_set_results:mysql服务器输出数据的编码
会话变量
只存在于当前客户端与数据库服务器端的一次连接当中。如果连接断开,那么会话变量全部丢失!
定义会话变量: set @变量=值
查看会话变量: select @变量
局部变量
在存储过程中使用的变量就叫局部变量。只要存储过程执行完毕,局部变量就丢失。
回到上面这个存储过程,如何接受返回参数的值呢?
定义一个会话变量name, 使用name会话变量接收存储过程的返回值
CALL pro_testOut(@NAME);
查看变量值
SELECT @NAME;
3. 带有输入输出参数的存储过程
DELIMITER $ CREATE PROCEDURE pro_testInOut(INOUT n INT) -- INOUT: 输入输出参数 BEGIN -- 查看变量 SELECT n; SET n =500; END $ -- 调用 SET @n=10; CALL pro_testInOut(@n); SELECT @n;
4. 带有条件判断的存储过程
需求:输入一个整数,如果1,则返回“星期一”,如果2,返回“星期二”,如果3,返回“星期三”。其他数字,返回“错误输入”;
DELIMITER $ CREATE PROCEDURE pro_testIf(IN num INT,OUT str VARCHAR(20)) BEGIN IF num=1 THEN SET str='星期一'; ELSEIF num=2 THEN SET str='星期二'; ELSEIF num=3 THEN SET str='星期三'; ELSE SET str='输入错误'; END IF; END $ --调用 CALL pro_testIf(4,@str); SELECT @str;
5. 带有循环功能的存储过程
需求: 输入一个整数,求和。例如,输入100,统计1-100的和
DELIMITER $ CREATE PROCEDURE pro_testWhile(IN num INT,OUT result INT) BEGIN -- 定义一个局部变量 DECLARE i INT DEFAULT 1; DECLARE vsum INT DEFAULT 0; WHILE i<=num DO SET vsum = vsum+i; SET i=i+1; END WHILE; SET result=vsum; END $ --调用 CALL pro_testWhile(100,@result); SELECT @result;
6. 使用查询的结果赋值给变量(INTO)
DELIMITER $ CREATE PROCEDURE pro_findById2(IN eid INT,OUT vname VARCHAR(20) ) BEGIN SELECT empName INTO vname FROM employee WHERE id=eid; END $ --调用 CALL pro_findById2(1,@NAME); SELECT @NAME;
二、 触发器
触发器作用:当操作了某张表时,希望同时触发一些动作/行为,可以使用触发器完成。
~~语法~~
CREATE TRIGGER <触发器名称> --触发器必须有名字,最多64个字符,可能后面会附有分隔符.它和MySQL中其他对象的命名方式基本相象.
{ BEFORE | AFTER } --触发器有执行的时间设置:可以设置为事件发生前或后。
{ INSERT | UPDATE | DELETE } --同样也能设定触发的事件:它们可以在执行insert、update或delete的过程中触发。
ON <表名称> --触发器是属于某一个表的:当在这个表上执行插入、 更新或删除操作的时候就导致触发器的激活. 我们不能给同一张表的同一个事件安排两个触发器。
FOR EACH ROW --触发器的执行间隔:FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次。
<触发器SQL语句> --触发器包含所要触发的SQL语句:这里的语句可以是任何合法的语句, 包括复合语句,但是这里的语句受的限制和函数的一样。
需求: 当向员工表插入一条记录时,希望mysql自动同时往日志表插入数据
CREATE TRIGGER tri_empAdd AFTER INSERT ON employee FOR EACH ROW -- 当往员工表插入一条记录时 INSERT INTO test_log(content) VALUES('员工表插入了一条记录');
以上触发器是基于insert的,以下两个是基于update和delete的。
-- 创建触发器(修改) CREATE TRIGGER tri_empUpd AFTER UPDATE ON employee FOR EACH ROW -- 当往员工表修改一条记录时 INSERT INTO test_log(content) VALUES('员工表修改了一条记录'); -- 创建触发器(删除) CREATE TRIGGER tri_empDel AFTER DELETE ON employee FOR EACH ROW -- 当往员工表删除一条记录时 INSERT INTO test_log(content) VALUES('员工表删除了一条记录');
使用触发器深层理解
下面为了更深刻的理解触发器的作用和用法,以一个实例来演示,现在有下面这样一个需求:
需求:有两张表,一张订单表,一张商品表,每生成一个订单,意味着商品的库存要减少。
-- 创建表
create table goods(
id int primary key auto_increment,
name varchar(20) not null,
price decimal(10,2) default 1,
inv int comment '库存数量'
) charset utf8;
insert into goods values(null,'荣耀3c',999,100),
(null,'魅族3c',1299,50),
(null,'iphone6s',5999,200),
(null,'荣耀6',1999,250),
(null,'iphonese',2999,300);
create table orders(
id int primary key auto_increment,
o_id int not null comment '商品id',
o_number int comment '商品数量'
) charset utf8;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
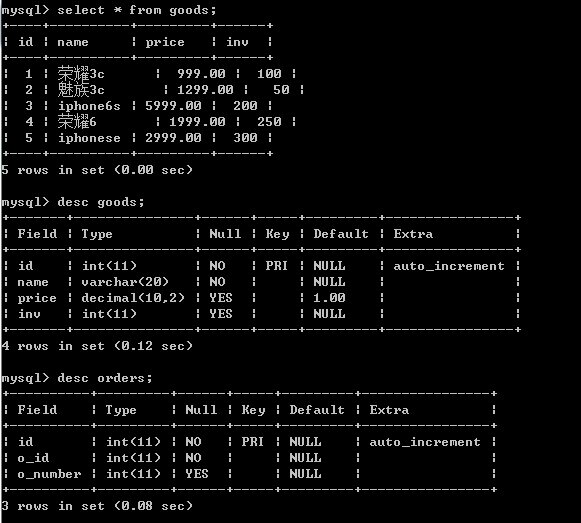
创建触发器
-- 临时修改语句结束符
delimiter $$
create trigger after_order after insert on orders for each row
begin
-- 触发器内容开始
update goods set inv = inv - new.o_number where id = new.id;
end
-- 结束触发器
$$
-- 修改临时语句结束符
delimiter ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

下面,根据生成一个指定商品的订单号,看下goods表中的对应商品的数量是否会减少,即触发器是否真正工作
-- 生成订单
insert into orders values(null,1,3);- 1
- 2
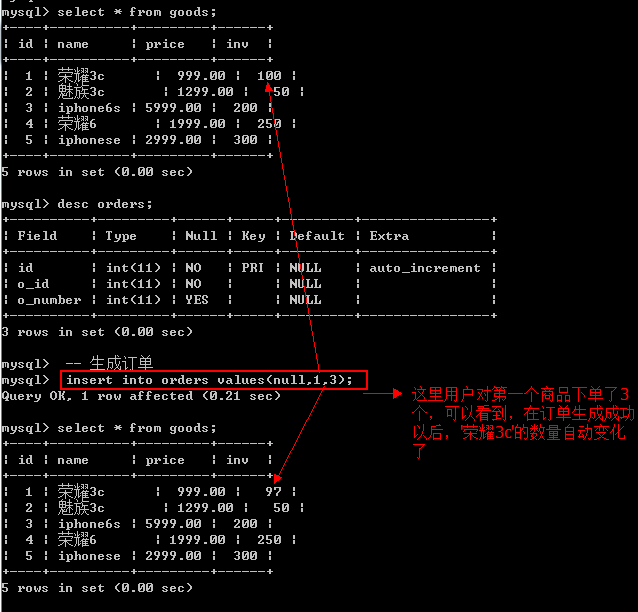
查看触发器
-- 查看所有触发器或者模糊匹配
show triggers [like pattern]
-- 查看所有触发器
show triggers\G- 1
- 2
- 3
- 4
- 5
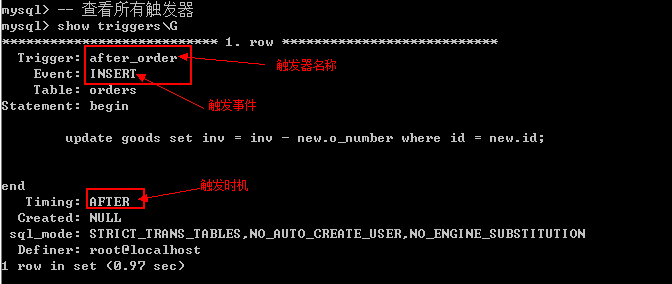
-- 所有的触发器都会保存在一张表中,information_schema.triggers
select * from information_schema.triggers\G- 1
- 2
删除触发器
drop trigger 触发器名称
-- 删除触发器
drop trigger after_order;- 1
- 2
- 3
复制相关:
1触发器在MySQL复制环境中也是可以工作的
在MySQL5.0的版本和其他大多数数据库系统一样,触发器和复制都能工作。在主库上,通过触发器承载的操作,不会复制到从库上。但是,如果主库上存在的触发器,如果在从库上的相关表中也创建的话,在从库上的触发器就能和主库一样被激活、触发。
2.在主库上的操作是怎样被复制到从库上去的?
首先要确定一件事:主从库都有同样的触发器,在主库上创建的触发器也要在从库上重新创建一遍。这样DML语句在复制中就能在从库上激活触发器。例如:还是a表,我们在a表中创建了一个after insert 触发器,复制过程如下:
1).一条insert语句插入a表
2).after insert 激活触发器,也插入到b表
3).insert语句写入到bin log中
4).复制线程获得并执行insert语句
5).after insert 激活触发器,也插入到b表
- 1
- 2
- 3
- 4
- 5
- 1