———————————————————————————————————————————————————————
Urllib库是Python中的一个功能强大、用于操作,组装URL,并在做爬虫的时候经常要用到的库。在python3环境下,爬虫工作主要用到urllib.requset,urllib.error和urllib.parse。
———————————————————————————————————————————————————————
Urllib.request模块常用的函数
基本是先使用Request生产请求,在使用urlopen打开url。在Request部分添加http的报头信息和data信息,然后使用用urlopen打开url返回一个文件对象
1.urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- 此函数用于打开一个url,并返回一个文件对象,同时提供:geturl(),getinfo(),getcode()的方法
| 函数方法 | 解释 |
|---|---|
| read() , readline() ,readlines() , fileno() , close() | 对HTTPResponse类型数据进行操作 |
| info() | 返回HTTPMessage对象,表示远程服务器返回的头信息 |
| getcode() | 返回Http状态码。如果是http请求,200请求成功完成;404网址未找到 |
| geturl() | 返回请求的url,用于重定向 |
- data参数是用于发送post的请求(具体内容在下文讲解)
- timeout参数用于超时设置
2.urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
- 此函数用于包装URl,放回一个带有headers信息的请求
- headers是一个字典类型
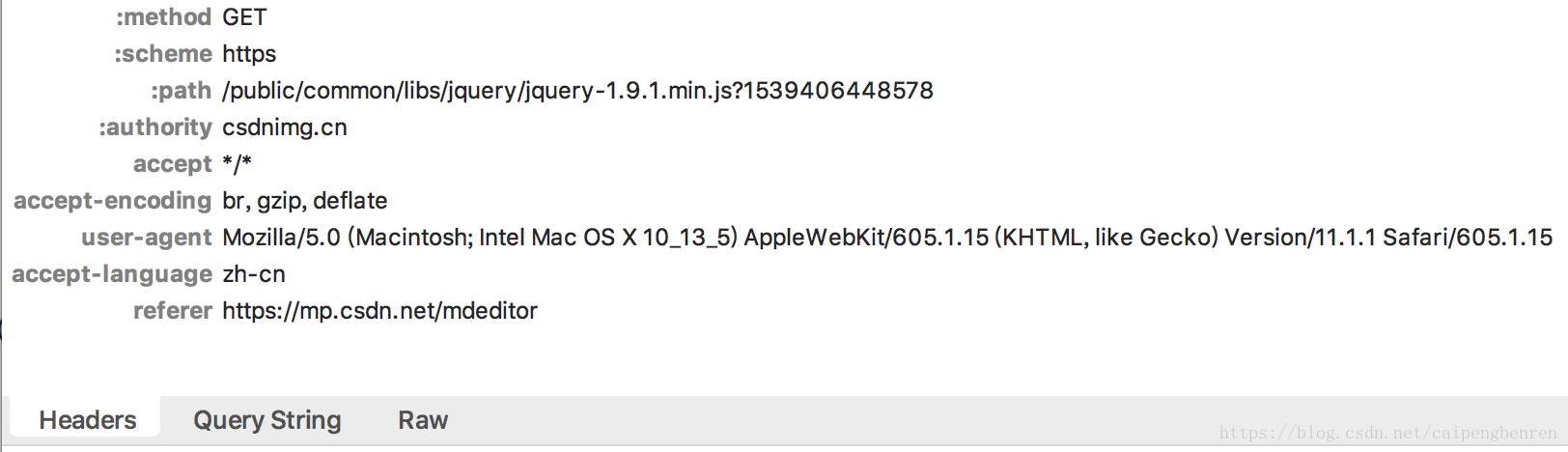
url = http;//mp.csdn.net/
headers = {
'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ',
'Connection': 'keep-alive' }
req = request.Request(url, headers=headers)
- add_header()和get_header()函数用于请求类的添加http报头
req.add_header("User-Agent",user-agent) #t添加一个http报头
req.get_header("User-agent") #返回一个已有的http报头信息,注意第一个字母大写,其他都小写
3. urllib.request.quote(key)
- 此函数用于拼接url时对中文字符进行编码
- 返回一个处理后的字符串
———————————————————————————————————————————————————————
urllib.parse模块常用的函数
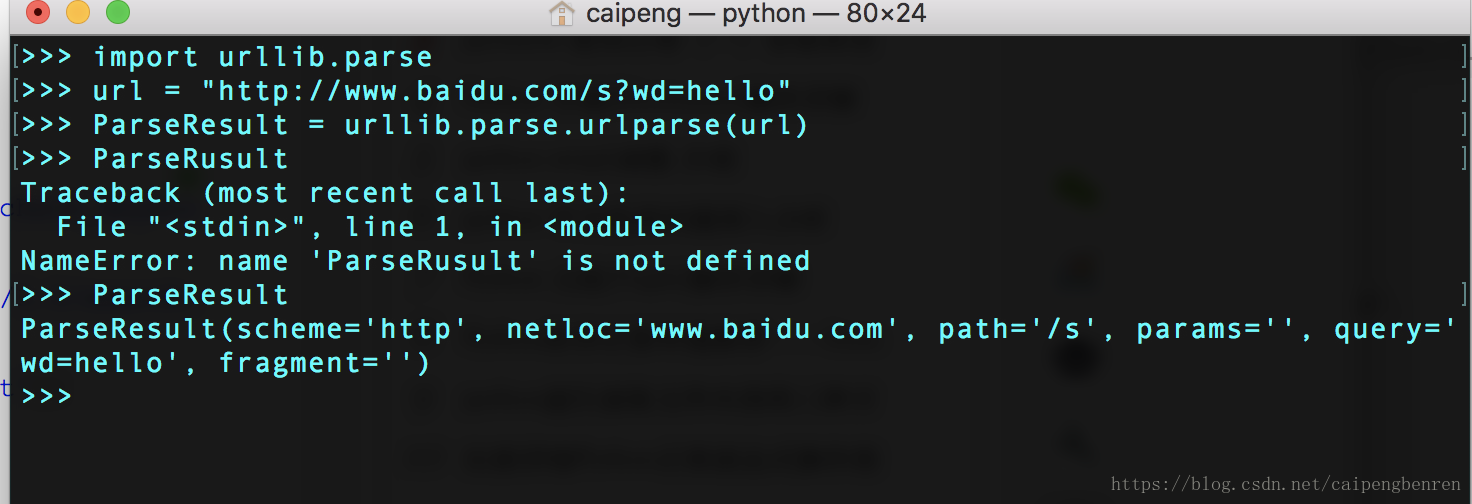
1.urllib.parse.urlparse(url)
- 此函数用于获得url参数
2urllib.parse.urlencode(query)
- 此函数将字典型的data进行编码,用于处理post请求中的data参数
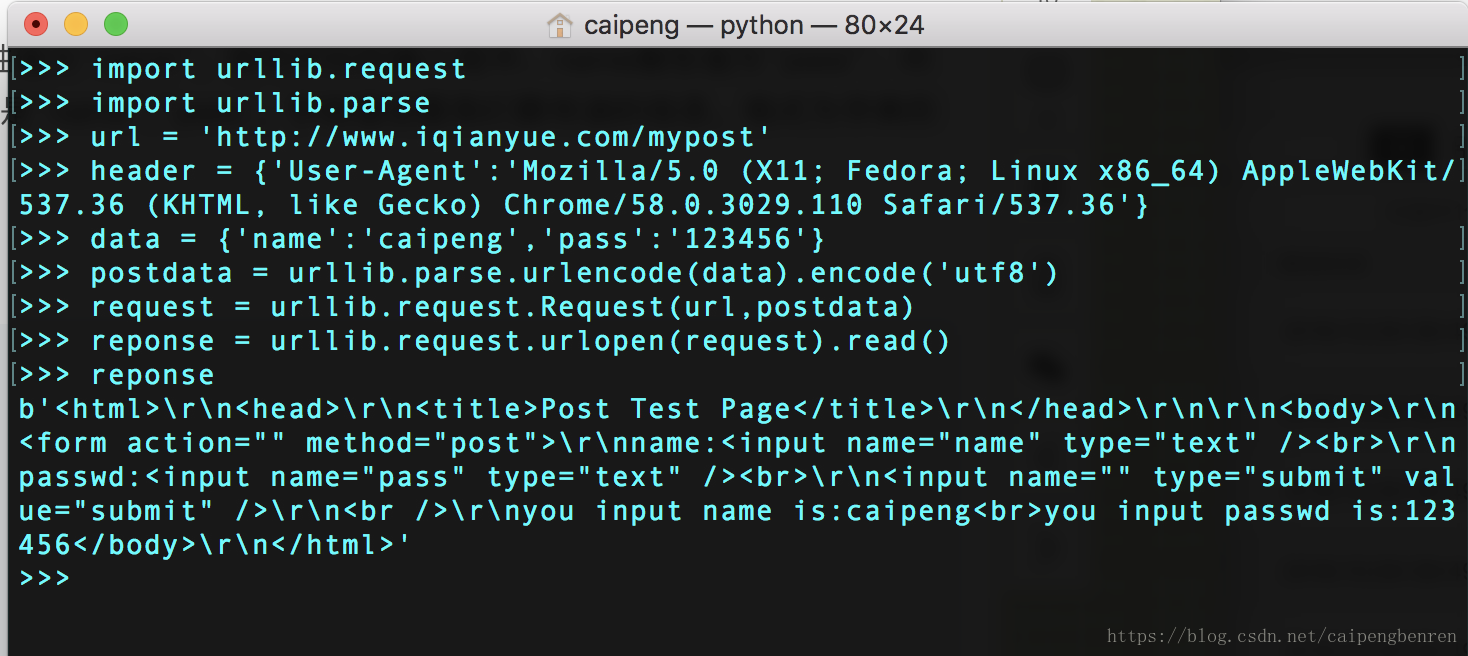
以http://www.iqianyue.com/mypost网站为例
——————————————————————————————————————————
有其他疑问可以直接点击官方文档解释
官方解释较为全面