NVIDIA CUDA初级教程视频--(一)
其他
2019-01-25 17:50:05
阅读次数: 0
第一章CPU体系架构概述:
- CPU:执行指令(算术,访存,控制),处理数据的器件:完成基本的逻辑和算术指令
现在增加了复杂功能:内存接口,外部设备接口
包含大量晶体管
- 最优化目标:CPI:每条指令的时钟数 时钟周期 要两个都比较小,但是两个指标不独立
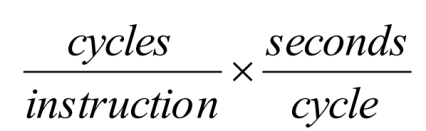
- 桌面应用Desktop Programs
轻量级进程,少量线程 Lightly threaded
大量分支和交互操作 Lots of branches
大量的存储器访问 Lots of memory accesses
真正用于数值运算的指令很少
4.CPU: 数据通道+控制逻辑
取址,译码,执行,访存,写回
5.流水线:利用指令集并行,极大的减少了时钟周期,增加了延迟和芯片面积
如何处理具有依赖关系的指令,分支应该怎么处理,?
6.旁路:可以不用等待所有依赖指令的全部执行完,节省时间
停滞:前面的访存没有完成,后面的肯定不行,
分支:做一些分支预测,猜测下一条指令,基于过去的分支记录,
能提升性能以及能量效率,但是面积增加,可能会增加延迟
分支断定:用条件语句替换分支,不是用分支预测器,所有的全部都运行
- IPC :一个时钟周期可以处理的指令数 超标量:增加流水线宽度
分支和调度需要产生额外开销,需要 一些技巧来逼近峰值,增加来面积,需要更多寄存器和存储器带宽
8.指令调度:依赖关系 替换寄存器:可以并行执行
9.乱序执行:重排指令,获得最大的吞吐率,重排缓冲区,发射队列/调度器
可以使IPC接近理想状态,面积增加,功耗增加
10.存储器架构/层次:很多时间在访问存储器 安排数据怎么去读写放
- 缓存:把数据放在尽可能接近的位置 利用:时间临近性,空间临近性
缓存层级:硬件管理:L1,L2,L3 级数越小,速度越快,但是容量越小 软件:主存,磁盘
另外设计考虑;分区,一致性,控制器
12CPU内部并行性:指令集并行,数据级并行(单指令多数据SIMD),线程级并行
多核:将流水线完整复制,完整的核,除了最后一级缓存,不共享其他资源,
带来了多核程序和利用率问题
13.多线程读写同一块数据:锁存
一致性:谁的数据是正确的?解决方法:缓存一致性协议coherence
同一性:什么样的数据是正确的?解决方案:存储器同一性模型
14.能量墙:芯片的主频增加,功耗的增加 时钟频率无法保持线性增长
处理器的存储器带宽无法满足处理能力的提升
转载自blog.csdn.net/qq_37481260/article/details/86617652