luffy搭建深度学习环境可谓一波三折, 最后终于搭建成功了, 原来用cpu跑30分钟的代码, gpu上1分30秒就跑完了(感动哭).
另外两篇博客可作为参考, 毕竟踩了许多坑:
深度学习之路–环境篇(使用docker搭建tensorflow_gpu开发环境)
深度学习之路–环境篇(TensorFlow_GPU+CUDA)
基本步骤
1 安装NVIDIA驱动
luffy这里是在服务器上进行搭建环境的, 驱动已经安装好了, 但是安装驱动很关键, 务必要匹配自己的显卡型号和后面准备安装的cuda版本. 网上有很多教程, luffy就不赘述了(主要是自己也不太熟>_<).

2 安装anaconda3
由于luffy使用使用指令安装几次不成功, 所以采用下载sh文件手动安装的办法;
- 去官网下载anaconda3, 或者去清华开源软件镜像下载更快一点.
- 转到安装文件所在目录, 使用以下指令进行安装, 一路默认即可, 或者自己指定安装目录.
$sh Anaconda3-2018.12-Linux-x86_64.sh
3 创建tensorflow-gpu + cuda + cudnn环境
接下来就是体现anaconda3的强大之处了, 一步到位
- 首先选定要安装那个版本的cuda, 具体参考Tensorflow不同版本要求与CUDA及CUDNN版本对应关系
- 创建conda环境(anaconda可以创建任意环境, 每个环境里面可安装任意版本Python/tensorflow/cuda等, 就像一个个不同的虚拟机一样, 太方便了)
$conda create -n tensorflow_gpu python=3.6 tensorflow=1.4.1
以上指令可同时完成安装Python3.6/ tensorflow-gpu1.4.1/cuda8.0/cudnn7.1.3
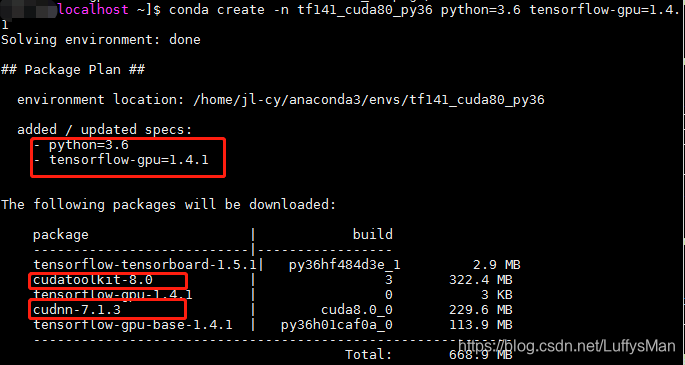
以上就基本搭建完成了, 但是在实际运行代码时, 可能会遇到下面的小问题.
遇到的问题
- luffy安装完成后, 赶紧测试下, 用的是tensorflow官网Mnist手写数字识别问题的多层卷积神经网络模型, 但是在成功下载完数据集后提下下面的错误:
E tensorflow/stream_executor/cuda/cuda_dnn.cc:378] Loaded runtime CuDNN library: 7103 (compatibility version 7100) but source was compiled with 7005 (compatibility version 7000). If using a binary install, upgrade your CuDNN library to match. If building from sources, make sure the library loaded at runtime matches a compatible version specified during compile configuration.
2019-01-23 18:14:30.459465: F tensorflow/core/kernels/conv_ops.cc:667] Check failed: stream->parent()->GetConvolveAlgorithms( conv_parameters.ShouldIncludeWinogradNonfusedAlgo<T>(), &algorithms)
Aborted (core dumped)
原因: 大概意思是cudnn运行时环境版本为7103(自动安装的), 但是源的编译版本为7005(我也不明白什么是缘~, 是开发环境?), 二者不兼容.
解决: 把cudnn7103降级为7005
#可先搜索cudnn有哪些可用包
$conda search cudnn
#然后安装目标包
conda install cudnn=7.0.5
- 有些同学可能会问, 为什么安装的是tensorflow1.4.1-gpu呢?
因为anaconda3的包里面只有1.4.1啊因为anaconda3的包里面只有1.4.1啊
