scrapy框架流程
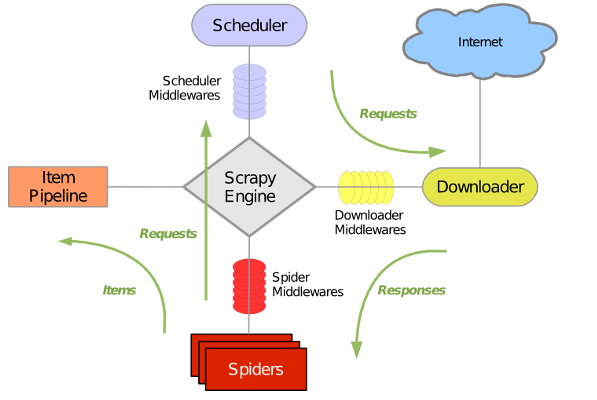
其流程可以描述如下:
-
调度器把requests–>引擎–>下载中间件—>下载器
-
下载器发送请求,获取响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
-
爬虫提取数据,分为两类:
-
提取的是url地址,组装成request对象---->爬虫中间件—>引擎—>调度器
-
提取数据—>引擎—>管道
-
-
管道进行数据的处理和保存
注意:
- 图中绿色线条的表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
scrapy的入门使用
-
创建工程
scrapy startproject pro_name(工程名称)
-
创建爬虫文件
cd pro_name
srcapy genspider spider_name allowed_domain
-
找spdier_name.py文中完成爬虫代码
class ItcastSpider(scrapy.Spider): name = 'itcast' # 爬虫名 allowed_domains = ['itcast.cn'] # 允许爬去的域名范围 start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] # 起始的url def parse(self, response): # start_url发请求后的响应的处理函数 li_list = response.xpath("//div[@class='tea_con']/div/ul/li") for li in li_list: item = {} item['name'] = li.xpath(".//h3/text()").extract_first() item['title'] = li.xpath(".//h3/text()").extract_first() item['desc'] = li.xpath(".//p/text()").extract_first() print(item) # none,request,item ,dict如果parse函数不存在,会触发父类scrapy.Spider中的parse函数,抛出异常
def parse(self, response): raise NotImplementedError('{}.parse callback is not defined'.format(self.__class__.__name__))关于
extract()和extract_first()的使用-
response.xpath() 返回的是一个特殊列表,该列表具有extract()和extract_first()方法
# 特殊列表返回的元素项是 Selector对象 <Selector xpath="//div[@class='tea_con']/div/ul/li//h3/text()" data='朱老师'> ret = response.xpath("//div[@class='tea_con']/div/ul/li//h3/text()") # 如果要提取想要的数据 ret.extract() # 从ret特殊列表中出去每个selector的data值,放入新列表 -
如果由于xpath写的有问题,导致返回的列表为空,从中获取字符串数据时,可以使用 extract_first()
ret.extract_first() # 判断ret列表的长度,如果长度为0,返回None,否则取出列表第0项的元素selector中的data属性值并返回
-
-
启动爬虫
scrapy crawl spider_name
yield作用
yield出现在函数中,将函数提升为一个生成器,调用test()会返回一个生成器对象(不会执行函数代码),当调用生成器的next时候,函数会在执行遇到yield的时候返回,再次调用next的时候,会从上次yield的位置继续执行,直到遇到下一次的yield
def test():
print("***************")
for i in range(10):
print("-------------")
yield i
print("++++++++++++++")
a = test()
x = next(a)
print(x)
y = next(a)
print(y)
** 生成器是一种特殊的迭代器 **
管道 PIpline
-
创建管道对象,在piplines.py中
class MyspiderPipeline(object): def process_item(self, item, spider): # 被引擎调用,传递数据item和爬虫对象 if spider.name == "itcast": print(item) return item # 如果存在多个管道的情况下,必须有,否则下一个管道接不到数据item -
开启管道,在配置文件中开启管道
ITEM_PIPELINES = { 'myspider.pipelines.MyspiderPipeline': 300, # 300表示当前管道处理数据优先级,数字越小,优先级越高 } -
将爬虫的数据通过yield的方式交给引擎,引擎再交给管道
class ItcastSpider(scrapy.Spider): name = 'itcast' allowed_domains = ['itcast.cn'] start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] def parse(self, response): li_list = response.xpath("//div[@class='tea_con']/div/ul/li//h3/text()") for li in li_list: item = {} item['name'] = li.xpath(".//h3/text()").extract_first() item['title'] = li.xpath(".//h3/text()").extract_first() item['desc'] = li.xpath(".//p/text()").extract_first() yield item # none,request,item ,dict
配置文件基本使用
设置日志等级
LOG_LEVEL = "WARNING"
# 一般情况下,不建议设置“Waring”,很多造成爬虫抓取数据失败的原因都是在DEBUG等级显示的,设置为WARNING就不会显示了
设置UA
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
构造请求
-
scrapy.Request(url,callback,meta,dont_filter)- url:请求地址,必须是完整的url地址
- callback:该请求对应的响应的处理函数
- meta:在不同的解析函数中进行数据传递
- dont_filter:默认时False,即过滤请求,scrapy框架默认会过滤重复的请求,相同url的请求只进行一次,第二次会被调度器拦截过滤掉
-
response.follow(url,callback)- url:请求地址,可以不完整,该方法会自动补充完整