写在前面
因为工作上的需要,记录下spring-data-elasticsearch与spring的配置,以及对应的海量数据全量拉取的过程。
es中的分页拉取数据
有两种分页形式,各适用于不同的场景
1. From + Size
在Kibana中,使用的查询的DSL如下
GET /{index_name}/_search
{
"from":10,
"size":20,
"query":{
"term":{
"key":"value"
}
}
}
写成SQL类似于
SELECT * FROM {index_name} where 'key'='value' limit 20 offset 10;
即返回第10-30条的数据,。
es在执行这样的分页时候,会从分片里取到前30个结果,然后舍弃前10个结果,把剩余的20个结果返回。
这样带来了几个问题:
-
随着分页不断增加,比如"from":1000, “size”:20 ,这代表着es要查询出1020个结果,然后舍弃前1000个结果,非常浪费。
-
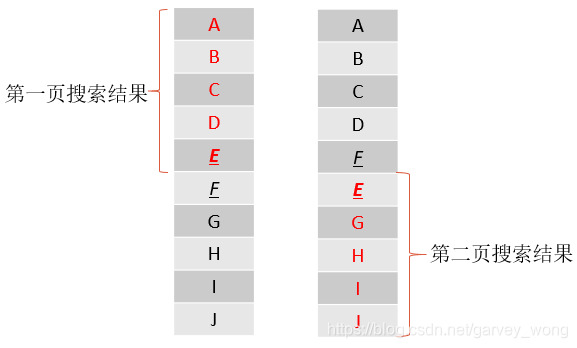
搜索的震荡问题:如果es是多分片多副本的状态,不设置preference参数的话,每次query是轮询主分片和副本分片。这样在多次搜索结果的队列里,内部顺序可能会发生不一致。这就导致在使用FROM+SIZE切分的时候,有些result item会重复显示,有些则会丢失
如下图,第一页搜索时返回了A-J的顺序结果,但查询下一页时,队列E和F发生了错位,则E被重复返回,F则丢失。要避免这样的结果的话还需要加上preference参数,确保针对某个用户时,多页查询时使用的分片一样,保证分片的查询与排序行为一致。
所以这种From + Size的分页适合的业务场景就像搜索引擎这样的。除了爬虫脚本之类的,正常用户一般在浏览前几个搜索结果页面后,就不会再往下翻了。
2. Scroll游标查询
工作中遇到了一个业务场景,需要从elasticSearch取回大量数据。全量取回短时间消化不了,占用资源也过大。所以需要分页取回。而经过以上分析,From和Size会给es服务器造成巨大压力。所以这时候需要使用Scroll查询.。初次查询时,Scroll会在es服务器上生成一个快照,保存一定的时间,然后客户端可以在此时间内重复从这个快照中拉取数据,而不用重复进行query操作。
scroll查询 可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价。游标查询允许我们 先做查询初始化,然后再批量地拉取结果。 这有点儿像传统数据库中的 cursor 。
游标查询会取某个时间点的快照数据。 查询初始化之后索引上的任何变化会被它忽略。 它通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引 视图 一样。
—— https://www.elastic.co/guide/cn/elasticsearch/guide/cn/scroll.html
版本说明
| item | version |
|---|---|
| elasticSearch | 6.2.4 |
| spring-data-elasticsearch | 3.1.0.RELEASE |
| spring | 5.0.8.RELEASE |
spring-data-elasticsearch对应的 Github链接:https://github.com/spring-projects/spring-data-elasticsearch
注意spring-data-elasticsearch与elasticSearch,以及spring有版本依赖的关系
对应关系摘录自github,如下
| spring data elasticsearch | elasticsearch |
|---|---|
| 3.2.x | 6.5.0 |
| 3.1.x | 6.2.2 |
| 3.0.x | 5.5.0 |
| 2.1.x | 2.4.0 |
| 2.0.x | 2.2.0 |
| 1.3.x | 1.5.2 |
我这的es版本较新,6.2.4对应的3.1.x。同时spring版本需要5.0以上
同时建议再下一个对应版本的kibana,便于操作elasticSearch。下载地址:https://www.elastic.co/cn/downloads/kibana
高版本的kibana已经集成了Sense插件,低版本的需要额外安装。
POM依赖
<!-- spring整合es -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>3.1.0.RELEASE</version>
</dependency>
<!-- es包 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.2.4</version>
</dependency>
Spring配置文件
在resources下的spring相关的配置文件子目录中,添加application-context-es.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<elasticsearch:transport-client id="client" cluster-nodes="${es.cluster.nodes}" cluster-name="${es.cluster.name}" client-transport-ignore-cluster-name="true"/>
<bean name="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client" />
</bean>
<elasticsearch:repositories base-package="org.springframework.data.elasticsearch.repository"></elasticsearch:repositories>
</beans>
-
其中${es.cluster.nodes}为es的节点ip,如127.0.0.1:9300 多个节点使用逗号分隔
-
${es.cluster.name}为要连接的es集群名称。可以登录kibana平台(默认5601端口)的Dev Tools中运行
GET /_cat/health?v
查看cluster列
-
创建elasticsearchTemplate的bean,用于之后的自动依赖注入
Java代码中使用elasticsearchTemplate进行游标查询
核心是两个方法:elasticsearchTemplate.startScroll() 与 elasticsearchTemplate.continueScroll()
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.ScrolledPage;
import org.springframework.data.elasticsearch.core.SearchResultMapper;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.aggregation.impl.AggregatedPageImpl;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.stereotype.Service;
import java.util.*;
@Service
public class ScrollDemo {
/**
* 索引名
*/
private static final String INDEX_NAME = "index_name";
/**
* 类型名,高版本es已经逐渐废弃类型概念,默认为_doc
*/
private static final String TYPE_NAME = "_doc";
/**
* scroll游标快照超时时间,单位ms
*/
private static final long SCROLL_TIMEOUT = 3000;
@Autowired
private ElasticsearchTemplate esTemplate;
/**
* 用于将Scroll获取到的结果,处理成dto列表,做复杂映射
*/
private final SearchResultMapper searchResultMapper = new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
List<ResultDto> result = new ArrayList<>();
for (SearchHit hit : response.getHits()) {
if (response.getHits().getHits().length <= 0) {
return new AggregatedPageImpl<T>(Collections.EMPTY_LIST, pageable, response.getHits().getTotalHits(), response.getScrollId());
}
//可以做更复杂的映射逻辑
Object userIdObj = hit.getSourceAsMap().get("userId");
result.add(new ResultDto(userIdObj));
}
if (result.isEmpty()) {
return new AggregatedPageImpl<T>(Collections.EMPTY_LIST, pageable, response.getHits().getTotalHits(), response.getScrollId());
}
return new AggregatedPageImpl<T>((List<T>) result, pageable, response.getHits().getTotalHits(), response.getScrollId());
}
};
public void demo() {
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withIndices(INDEX_NAME)//索引名
.withTypes(TYPE_NAME)//类型名
.withQuery(QueryBuilders.termQuery("userId", "123"))//查询条件,这里简单使用term查询
.withPageable(PageRequest.of(0, 10))//从0页开始查,每页10个结果
.withFields("userId")//ES里该index内存的文档,可能存了很多我们不关心的字段,全返回没必要,所以指定有用的字段
.build();
ScrolledPage<ResultDto> scroll = (ScrolledPage<ResultDto>) esTemplate.startScroll(SCROLL_TIMEOUT, searchQuery, ResultDto.class, searchResultMapper);
System.out.println("查询总命中数:" + scroll.getTotalElements());
while (scroll.hasContent()) {
for (ResultDto dto : scroll.getContent()) {
//Do your work here
System.out.println(dto);
}
//取下一页,scrollId在es服务器上可能会发生变化,需要用最新的。发起continueScroll请求会重新刷新快照保留时间
scroll = (ScrolledPage<ResultDto>) esTemplate.continueScroll(scroll.getScrollId(), SCROLL_TIMEOUT, ResultDto.class, searchResultMapper);
}
//及时释放es服务器资源
esTemplate.clearScroll(scroll.getScrollId());
}
@Document(indexName = INDEX_NAME,
type = TYPE_NAME)
public class ResultDto {
@Field
private long userId;
public ResultDto() {
}
public ResultDto(long userId) {
this.userId = userId;
}
public ResultDto(Object userIdObj) {
userId = Long.valueOf(userIdObj.toString());
}
public long getUserId() {
return userId;
}
public void setUserId(long userId) {
this.userId = userId;
}
@Override
public String toString() {
return "ResultDto{" +
"userId='" + userId + '\'' +
'}';
}
}
}