1.元组
元组不可修改,但元组元素(如列表)的内部可以修改

元组的+和*
+号可以连接元组来生成新元组,*号可以复制元组

元组拆分
*rest:用于只取出tuple中开头几个元素,剩下的元素直接赋给*rest。如果rest部分是用不到的数据,为了方便直接用_代替

元组方法
count(x):统计x在元组中的出现次数

index(x):查找x在元组中的下标。如果x多次出现,则返回第一次出现的下标

2.列表
2.1 添加和移除元素
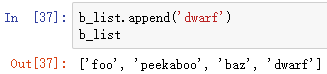
append(x):将x添加到列表尾部
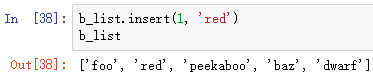
insert(index , x):将x插入到下标index处
pop(index):删除下标index处的元素,并返回元素值
remove(x):删除第一个x


2.2 连接两个列表
+号生成一个新列表,extend添加到原列表上。extend比 + 号快。

2.3 检查一个值是否在列表中,用in:

2.4 列表元素排序sort()

key也是一个函数,用来指定排序方法。比如我们想要按string的长度来排序:

2.5 有序列表:二分查找、插入
bisect.bisect(list,x):返回元素x应当被插入有序list的位置(下标)
bisect.insort(list,x):将x插入有序list, 并仍然保持有序
注:bisect模块不会检查list是否排好序,所以用这个模块之前要先把list排序。

2.6 切片:包含开头,不包含结尾

对切片赋值:比如把一个元素换成两个元素

省略开头或结尾:

负索引表示倒数第几个:

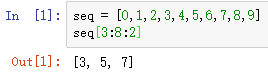
第2个冒号后面的数代表步长,就是隔几个元素取一次:
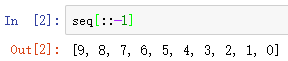
步长设为-1能反转一个list或tuple:
3. 一些序列函数
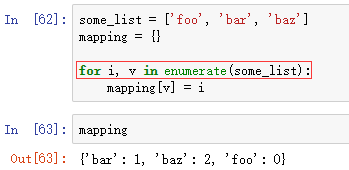
enumerate(枚举)
enumerate能返回一个(i, value)的元组,其中i是下标,value是元素值
比如把序列的元素值(假设没有重复值)映射到下标值:
sorted函数:返回一个新的已排序列表。而前面的sort方法是修改原列表。参数与列表的sort方法一致。

zip函数:将元组或列表配对(本质上是行列变换)。返回值没有实例化,不能直接打印,需要转化为list或tuple。

zip和enumerate搭配,用于遍历配对结果:
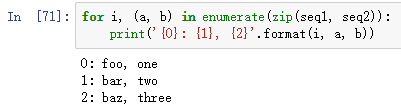
将已配对的结果还原:

reversed函数:将元组、列表等元素倒过来。注意,reversed是一个生成器,所以需要实例化,转化为list或tuple。

4.字典
字典也叫哈希表(hash map )或关联数组(associative array),是键值对集合。
4.1 创建字典:可用{ }创建。

4.2 插入

4.3 删除:del或pop。pop可以返回被删的值

4.4 提取所有key、提取所有value
使用keys()、values()

4.5 字典合并:update()
注:如果两个字典存在相同的键,调用update的字典的值会被覆盖

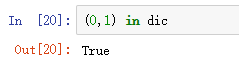
4.6 检查字典中是否含有一个键
4.7 默认值
(1) get(key,default_value)用来获得key对应的值,如果字典中没有key,则返回默认值default

(2) setdefault方法用于指定所有键的初始值
例如:将单词按首字母分类

(3) collections模块的defaultdict指定值的默认类型
