布尔模型
布尔模型是检索模型中最简单的一种,理论基础就是集合论。
用户查询一般使用“与或非”这些逻辑连接词,比如用户希望找到与苹果公司相关的信息,可以用如下的逻辑表达式查询:苹果AND(乔布斯OR iPad),代表的涵义很容易理解。

对于上面的文档,满足搜索的要求是D3和D5。
布尔模型很简单,但是其结果是二元的,要么相关要么不相关。所以无法根据搜索结果进行排序,而且对普通用户来说,使用Or And Not很难。
向量空间模型
向量空间模型作为一种文档表示和相似性计算的工具,不仅仅在搜索领域,在自然语言处理、文本挖掘等诸多其他领域也是普遍采用的有效工具。
- 文档表示
向量空间模型把每个文档看做是由t维特征组成的向量,这些特征可以是单词、词组等多种形式,最常用的还是单词。
直接看图,很容易明白:

特征与文档的交点就是权重。这种模型下,用户的查询也可以被看做一个特殊的文档,也将其转换为t维的特征向量。
权重怎么计算?
答案是:TF-IDF算法。 http://www.tfidf.com/
TF(t) = (Number of times term t appears in a document) / (Total number of terms in the document).
IDF(t) = log_e(Total number of documents / Number of documents with term t in it).
Weight=TF*IDF

文档转换为特征向量后,就可以计算文档之间或者查询与文档之间的相似性了。对于搜索排序这种任务来说,给定用户输入的查询,理论上应该计算查询和网页内容之间的“相关性”,以此来衡量排序的先后。
如何计算相似性呢?Cosine相似性是最常用也是非常有效的计算方式:

我们可以很简单的明白,Cosine(余弦)公式有一个明显的缺陷:
会抑制对长文档的相关度,因为长文档不光会讨论搜索关键词包含的内容,还会讨论其他一些内容。而短文档一般受限于篇幅,所以只会讨论搜索关键词包含的内容。这样会使得短文档更加的相关。
为了便于理解Cosine相似性,可以将每个文档以及查询看做是一个t维向量空间里的向量,Cosine公式就是求两个向量之间的夹角,夹角越小,两个内容越相似。我们知道,二维向量的余弦夹角计算公式如下:
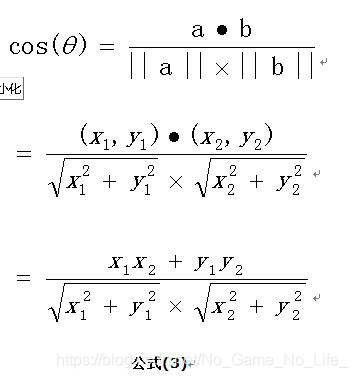
所以拓展到t维,很容易理解。
概率检索模型
概率检索模型是目前效果最好的模型之一。
- 概率排序原理
给定一个查询,如果搜索系统能够在搜索结果排序时按照文档和用户需求的相关性由高到底排序,那么这个搜索系统的准确性是最优的。而在文档集合的基础上尽可能准确的对这种相关性进行估计则是其核心。
从概率排序原理的表述来看,这是一种直接对用户需求相关性进行建模的方法,这点与向量空间模型不同,向量空间模型是以查询和文档的内容相似性来作为相关性的代替品。
怎样对文档与用户需求的相关性进行建模呢?
用户发出一个查询请求,如果我们对文档集合划分为两个分类:相关和不相关的文档子集,于是这样就可以转化为一个分类问题。
对于某个文档D来说,如果其属于相关文档子集的概率大于属于不相关文档子集的概率,我们就可以认为这个文档与用户查询是相关的。途中的P代表相关性的概率或者不相关的概率,那么P(R|D)表示,在文档D的基础上Relative的概率。如果P(R|D)>P(NR|D),我们可以认为文档与用户查询是相关的:
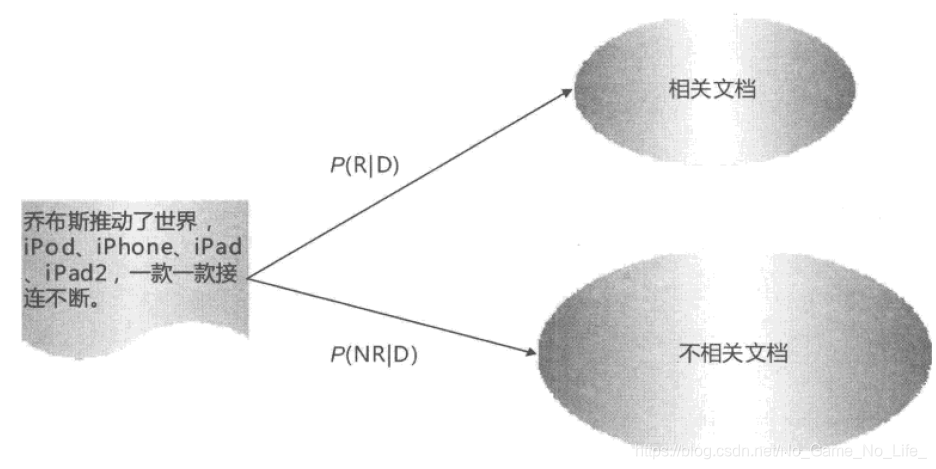
现在的问题是如何计算两个P的值呢?为了简化问题,首先我们根据贝叶斯规则对两个概率值进行改写,即:(概率论内容)
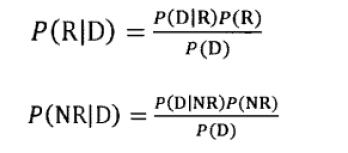
要判断P(R|D)>P(NR|D),就是判断:
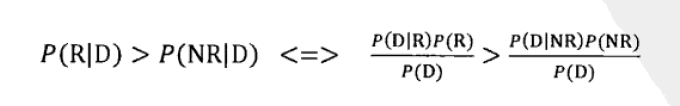
因为是同一篇文档,所以P(D)是相同的,也就是判断:
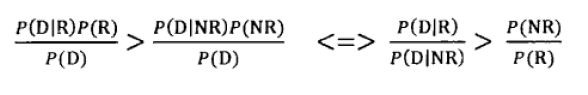
尽管是个二元的分类问题,但搜索的时候并不需要真的分类,只需要按相关性结果由高到低排序即可,也就是按照公式P(D|R)/P(D|NR)排序即可。所以问题进一步化简为估算因子P(D|R)和P(D|NR)。
如何估算,二元独立模型(BIM)提供了计算这些因子的框架:
为了使得估算可行,BIM模型做出了两个假设:
- 二元假设:一篇文章由特征进行表示的时候,分两种情况“出现”“不出现”,不考虑词频等其他因素。按特征表示一个文档D,应该这样表示D{1,0,1,0,1},也就是说出现了第1、3、5个特征。
- 词汇独立性假设:假设文档里出现的单词之间没有任何关联,也就是说每个单词是独立同分布的,不依赖其他单词是否出现。当然这个假设很明显与事实不符,出现“乔布斯”的话,很容易会出现“苹果”一词。但是为了简化计算,我们不得不这么做。
在二元假设中提到了表示法D{1,0,1,0,1},我们用pi表示第i个特征在相关文档集合内出现的概率,于是文档D的P(D\R)概率为:
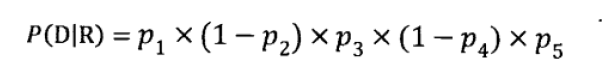
同理P(D|NR)为:
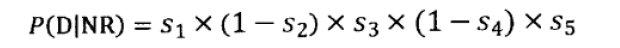
所以,估算表达式为:
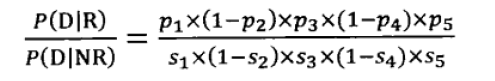
也就是:
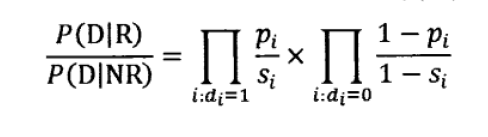
经过化简和取对数:
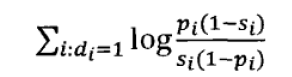
剩下就是知道pi和si怎么计算了,我们利用下表所列数据来估算单词概率:

表中第3行的N为文档集合包含的文档总数,R为相关文档的个数,所以N-R就是不相关文档的个数。
对于某个单词di来说,假设包含这个单词的文档共有ni个,其中相关的文档有ri个,不相关的文档有ni-ri个。
再考虑第二列,因为相关文档个数是R个,其中出现过单词di的有ri个,那么相关文档中没有出现di的就是R-ri个,同理不相关文档里没有出现这个单词的个数就求出来了。
如果假设我们知道N、R、ni、ri的话,其他数值是可以求出来的。
根据表格数据,即可估算si和pi。为了使得pi和si平滑,我们对等式做了一点点变形:
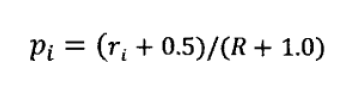
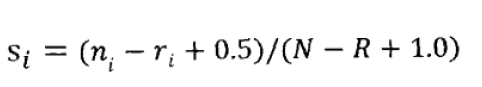
将这两个估值因子带入相关性估算公式:

终于说完了这个模型,但是根据BIM计算相关性的实际效果并不好,但是这个模型确实非常成功的概率模型方法BM25的基础,这就是我们为什么介绍BIM的原因。
- BM25模型
我放弃了!
- BM25F模型
开心就好,头发重要。
语言模型方法
借鉴了语音识别领域采用的语言模型技术,将语言模型和信息检索相互融合的结果。
有缘再看吧。
机器学习排序
略。