(深度学习)比较新的网络模型:Inception-v3 , ResNet, Inception-v4, Dual-Path-Net , Dense-net , SEnet , Wide ResNet
https://blog.csdn.net/ling00007/article/details/79115156
深度学习——分类之SENet
中心思想:对于每个输出channel,预测一个常数权重,对每个channel加权一下。
思路
如下,就是SENet的基本结构:
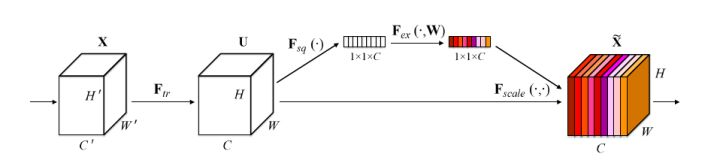
原来的任意变换,将输入X变为输出U,现在,假设输出的U不是最优的,每个通道的重要程度不同,有的通道更有用,有的通道则不太有用。
对于每一输出通道,先global average pool,每个通道得到1个标量,C个通道得到C个数,然后经过FC-ReLU-FC-Sigmoid得到C个0到1之间的标量,作为通道的权重,然后原来的输出通道每个通道用对应的权重进行加权(对应通道的每个元素与权重分别相乘),得到新的加权后的特征,作者称之为feature recalibration。
第一步每个通道HxW个数全局平均池化得到一个标量,称之为Squeeze,然后两个FC得到01之间的一个权重值,对原始的每个HxW的每个元素乘以对应通道的权重,得到新的feature map,称之为Excitation。任意的原始网络结构,都可以通过这个Squeeze-Excitation的方式进行feature recalibration,采用了改方式的网络,即SENet版本。
上面的模块很通用,也可以很容易地和现有网络集成,得到对应地SENet版本,提升现有网络性能,SENet泛指所有的采用了上述结构地网络。另外,SENet也可以特指作者 ILSVRC 2017夺冠中采用的SE-ResNeXt-152 (64 × 4d)。
实现
下面是SENet和Inception的结合:

下面是SENet和ResNet的结合:

可以看到,具体实现上就是一个Global Average Pooling-FC-ReLU-FC-Sigmoid,第一层的FC会把通道降下来,然后第二层FC再把通道升上去,得到和通道数相同的C个权重,每个权重用于给对应的一个通道进行加权。上图中的r就是缩减系数,实验确定选取16,可以得到较好的性能并且计算量相对较小。
SENet一个很大的优点就是可以很方便地集成到现有网络中,提升网络性能,并且代价很小。
对比ResNet-50和SE-ResNet-50:
在GPU上训练一个step(包括前向和反向),ResNet-50要190ms,而SE-ResNet-50要209ms
在CPU上inference一张224x224的图片,ResNet-50要164ms,而SE-ResNet-50要167ms
SE-ResNet-50总参数量大约比ResNet-50多10%,扔掉最后一个SE的话只多4%
可以看到,ResNet-50和SE-ResNet-50各方面相当,但是准确率却和ResNet-101相当,提升很大。
下图是SE-ResNet50的网络结构配置:

总结
提升很大,并且代价很小,通过对通道进行加权,强调有效信息,抑制无效信息,注意力机制,并且是一个通用方法,应用在Inception、Inception-ResNet、ResNet、ResNeXt都能有所提升,适用范围很广。
思路很清晰简洁,实现很简单,用起来很方便,各种实验都证明了其有效性,各种任务都可以尝试一下,效果应该不会太差。