1. Inception-v3 (Dec,2015)
2. ResNet(Dec,2015)
3. nception-v4(Aug,2016)
4. Dual-Path-Net (Aug,2017)
5. Dense-net(Aug,2017)
6. SEnet(Sep,2017)
7.Wide Residual Networks(Jun 2017)
Inception V3(还有 V2)
Christian 和他的团队都是非常高产的研究人员。2015 年 2 月,Batch-normalized Inception 被引入作为 Inception V2(参见论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift)。Batch-normalization 在一层的输出上计算所有特征映射的均值和标准差,并且使用这些值规范化它们的响应。这相当于数据「增白(whitening)」,因此使得所有神经图(neural maps)在同样范围有响应,而且是零均值。在下一层不需要从输入数据中学习 offset 时,这有助于训练,还能重点关注如何最好的结合这些特征。
2015 年 12 月,该团队发布 Inception 模块和类似架构的一个新版本(参见论文:Rethinking the Inception Architecture for Computer Vision)。该论文更好地解释了原始的 GoogLeNet 架构,在设计选择上给出了更多的细节。原始思路如下:
通过谨慎建筑网络,平衡深度与宽度,从而最大化进入网络的信息流。在每次池化之前,增加特征映射。
当深度增加时,网络层的深度或者特征的数量也系统性的增加。
使用每一层深度增加在下一层之前增加特征的结合。
只使用 3×3 的卷积,可能的情况下给定的 5×5 和 7×7 过滤器能分成多个 3×3。看下图

因此新的 Inception 成为了:

也可以通过将卷积平整进更多复杂的模块中而分拆过滤器:

在进行 inception 计算的同时,Inception 模块也能通过提供池化降低数据的大小。这基本类似于在运行一个卷积的时候并行一个简单的池化层:

Inception 也使用一个池化层和 softmax 作为最后的分类器。
ResNet
2015 年 12 月又出现了新的变革,这和 Inception V3 出现的时间一样。ResNet 有着简单的思路:供给两个连续卷积层的输出,并分流(bypassing)输入进入下一层(参见论文:Deep Residual Learning for Image Recognition)这个model是2015年底最新给出的,也是15年的imagenet比赛冠军。可以说是进一步将conv进行到底,其特殊之处在于设计了“bottleneck”形式的block(有跨越几层的直连)。

这和之前的一些旧思路类似。但 ResNet 中,它们分流两个层并被应用于更大的规模。在 2 层后分流是一个关键直觉,因为分流一个层并未给出更多的改进。通过 2 层可能认为是一个小型分类器,或者一个 Network-In-Network。
这是第一次网络层数超过一百,甚至还能训练出 1000 层的网络。
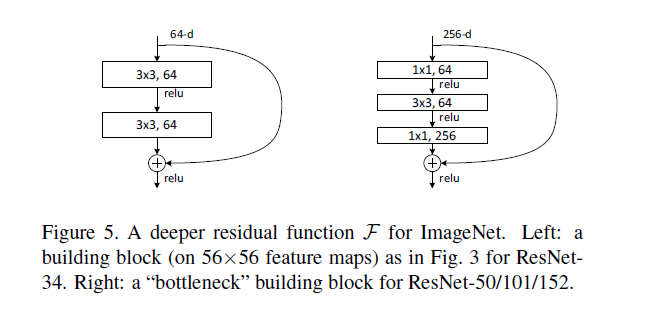
有大量网络层的 ResNet 开始使用类似于 Inception 瓶颈层的网络层:

这种层通过首先是由带有更小输出(通常是输入的 1/4)的 1×1 卷积较少特征的数量,然后使用一个 3×3 的层,再使用 1×1 的层处理更大量的特征。类似于 Inception 模块,这样做能保证计算量低,同时提供丰富的特征结合。
ResNet 在输入上使用相对简单的初始层:一个带有两个池的 7×7 卷基层。可以把这个与更复杂、更少直觉性的 Inception V3、V4 做下对比。
ResNet 也使用一个池化层加上 softmax 作为最后的分类器。
关于 ResNet 的其他贡献每天都有发生:
ResNet 可被认为既是平行模块又是连续模块,把输入输出(inout)视为在许多模块中并行,同时每个模块的输出又是连续连接的。
ResNet 也可被视为并行模块或连续模块的多种组合(参见论文:Residual Networks are Exponential Ensembles of Relatively Shallow Networks)。
已经发现 ResNet 通常在 20-30 层的网络块上以并行的方式运行。而不是连续流过整个网络长度。
当 ResNet 像 RNN 一样把输出反馈给输入时,该网络可被视为更好的生物上可信的皮质模型(参见论文:Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex)。
最深的model采用的152层!!下面是一个34层的例子,更深的model见表格。

其实这个model构成上更加简单,连LRN这样的layer都没有了。
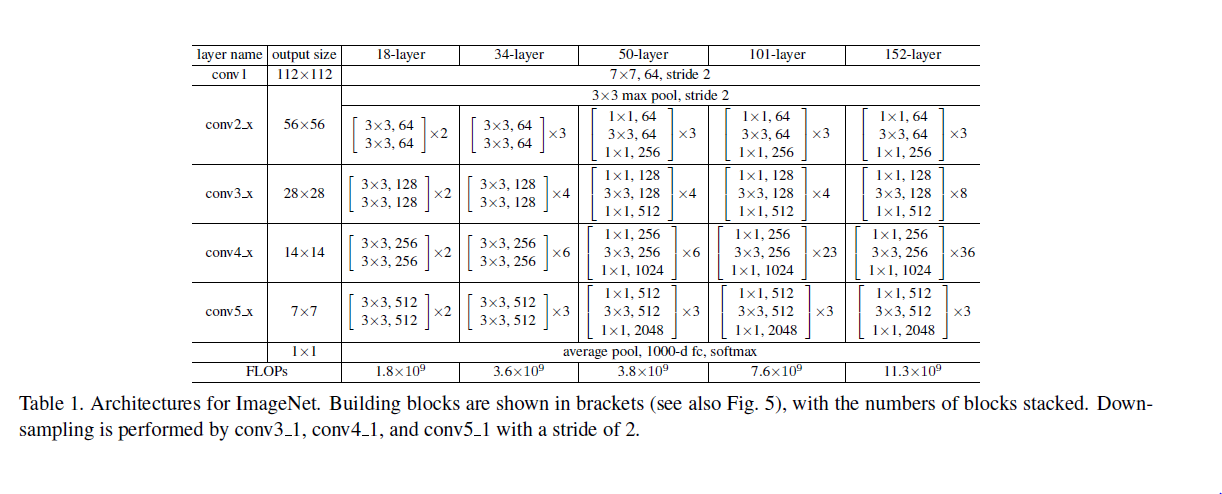
block的构成见下图:
Inception V4
这是 Christian 与其团队的另一个 Inception 版本,该模块类似于 Inception V3:

Inception V4 也结合了 Inception 模块和 ResNet 模块:

我认为该架构不太简洁,但也满满都是较少透明度的启发法(heuristics)。很难理解里面的选择,对作者们而言也难以解释。
考虑到网络的简洁性,可被轻易的理解并修正,那 ResNet 可能就更好了。
Dual-Path-Net
参考:http://blog.csdn.net/u014380165/article/details/75676216
论文:Dual Path Networks
论文链接:https://arxiv.org/abs/1707.01629
代码:https://github.com/cypw/DPNs
MXNet框架下可训练模型的DPN代码(如果对你有帮助,记得给个星):https://github.com/miraclewkf/DPN
算法详解:
本篇博文要介绍的duall path networks(DPN)是颜水成老师新作,前段时间刚刚在arxiv上放出,对于图像分类的效果有一定提升。我们知道ResNet,ResNeXt,DenseNet等网络在图像分类领域的效果显而易见,而DPN可以说是融合了ResNeXt和DenseNet的核心思想,这里为什么不说是融合了ResNet和DenseNet,因为作者也用了group操作,而ResNeXt和ResNet的主要区别就在于group操作。如果你对ResNeXt不大了解,可以参考博客:ResNeXt算法详解,如果你对DenseNet不大了解,可以参考博客:DenseNet算法详解。
那么DPN到底有哪些优点呢?可以看以下两点:
1、关于模型复杂度,作者的原文是这么说的:The DPN-92 costs about 15% fewer parameters than ResNeXt-101 (32 4d), while the DPN-98 costs about 26% fewer parameters than ResNeXt-101 (64 4d).
2、关于计算复杂度,作者的原文是这么说的:DPN-92 consumes about 19% less FLOPs than ResNeXt-101(32 4d), and the DPN-98 consumes about 25% less FLOPs than ResNeXt-101(64 4d).
先放上网络结构Table1,有一个直观的印象。其实DPN和ResNeXt(ResNet)的结构很相似。最开始一个7*7的卷积层和max pooling层,然后是4个stage,每个stage包含几个sub-stage(后面会介绍),再接着是一个global average pooling和全连接层,最后是softmax层。重点在于stage里面的内容,也是DPN算法的核心。
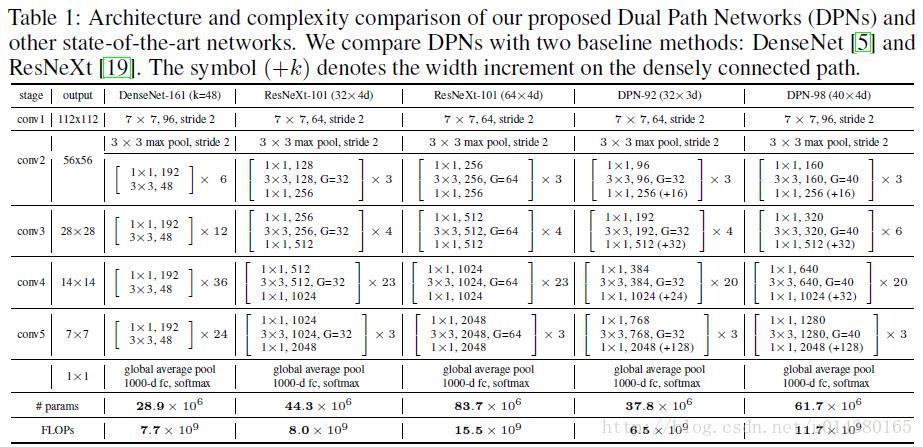
因为DPN算法简单讲就是将ResNeXt和DenseNet融合成一个网络,因此在介绍DPN的每个stage里面的结构之前,先简单过一下ResNet(ResNeXt和ResNet的子结构在宏观上是一样的)和DenseNet的核心内容。下图中的(a)是ResNet的某个stage中的一部分。(a)的左边竖着的大矩形框表示输入输出内容,对一个输入x,分两条线走,一条线还是x本身,另一条线是x经过1*1卷积,3*3卷积,1*1卷积(这三个卷积层的组合又称作bottleneck),然后把这两条线的输出做一个element-wise addition,也就是对应值相加,就是(a)中的加号,得到的结果又变成下一个同样模块的输入,几个这样的模块组合在一起就成了一个stage(比如Table1中的conv3)。(b)表示DenseNet的核心内容。(b)的左边竖着的多边形框表示输入输出内容,对输入x,只走一条线,那就是经过几层卷积后和x做一个通道的合并(cancat),得到的结果又成了下一个小模块的输入,这样每一个小模块的输入都在不断累加,举个例子:第二个小模块的输入包含第一个小模块的输出和第一个小模块的输入,以此类推。
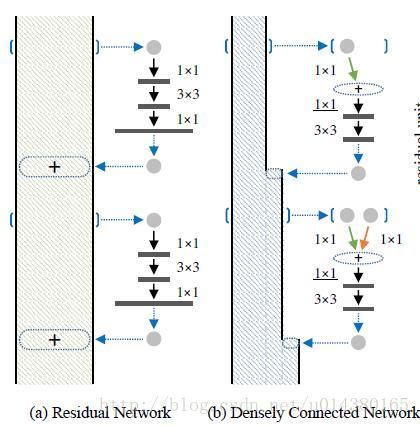
DPN是怎么做呢?简单讲就是将Residual Network 和 Densely Connected Network融合在一起。下图中的(d)和(e)是一个意思,所以就按(e)来讲吧。(e)中竖着的矩形框和多边形框的含义和前面一样。具体在代码中,对于一个输入x(分两种情况:一种是如果x是整个网络第一个卷积层的输出或者某个stage的输出,会对x做一个卷积,然后做slice,也就是将输出按照channel分成两部分:data_o1和data_o2,可以理解为(e)中竖着的矩形框和多边形框;另一种是在stage内部的某个sub-stage的输出,输出本身就包含两部分:data_o1和data_o2),走两条线,一条线是保持data_o1和data_o2本身,和ResNet类似;另一条线是对x做1*1卷积,3*3卷积,1*1卷积,然后再做slice得到两部分c1和c2,最后c1和data_o1做相加(element-wise addition)得到sum,类似ResNet中的操作;c2和data_o2做通道合并(concat)得到dense(这样下一层就可以得到这一层的输出和这一层的输入),也就是最后返回两个值:sum和dense。以上这个过程就是DPN中 一个stage中的一个sub-stage。有两个细节,一个是3*3的卷积采用的是group操作,类似ResNeXt,另一个是在每个sub-stage的首尾都会对dense部分做一个通道的加宽操作。
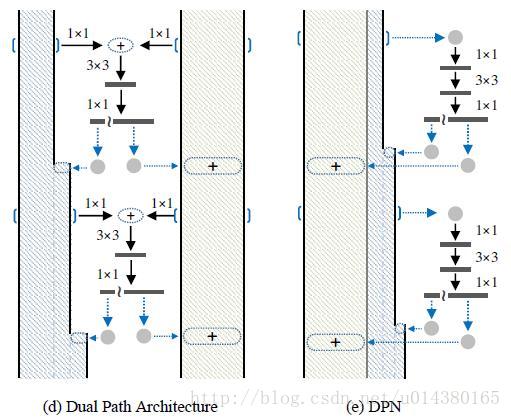
作者在MXNet框架下实现了DPN算法,具体的symbol可以看:https://github.com/cypw/DPNs/tree/master/settings,介绍得非常详细也很容易读懂。
实验结果:
Table2是在ImageNet-1k数据集上和目前最好的几个算法的对比:ResNet,ResNeXt,DenseNet。可以看出在模型大小,GFLOP和准确率方面DPN网络都更胜一筹。不过在这个对比中好像DenseNet的表现不如DenseNet那篇论文介绍的那么喜人,可能是因为DenseNet的需要更多的训练技巧。
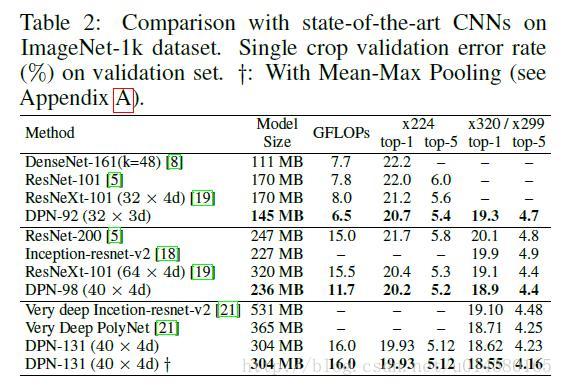
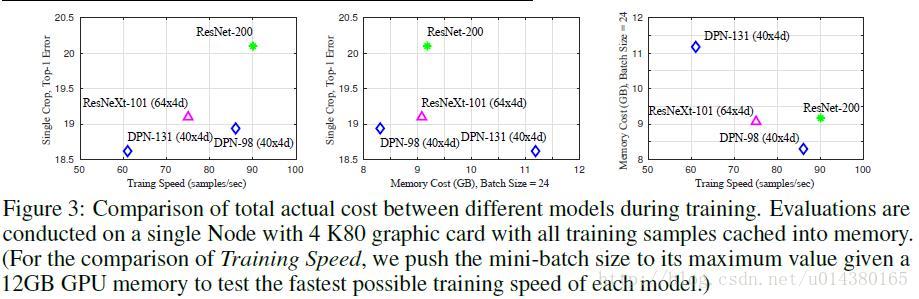
Figure3是关于训练速度和存储空间的对比。现在对于模型的改进,可能准确率方面的提升已经很难作为明显的创新点,因为幅度都不大,因此大部分还是在模型大小和计算复杂度上优化,同时只要准确率还能提高一点就算进步了。
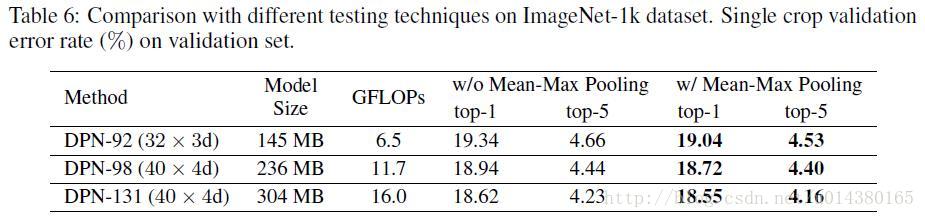
作者的最后提到一个如果在测试阶段,在网络结构后面加上mean-max pooling 层可以提高准确率,如下图:
更多实验结果可以看论文。
总结:
作者提出的DPN网络可以理解为在ResNeXt的基础上引入了DenseNet的核心内容,使得模型对特征的利用更加充分。原理方面并不难理解,而且在跑代码过程中也比较容易训练,同时文章中的实验也表明模型在分类和检测的数据集上都有不错的效果。
Dense-net
参考:http://blog.csdn.net/u012938704/article/details/53468483
代码地址:https://github.com/liuzhuang13/DenseNet
首先看一张图: 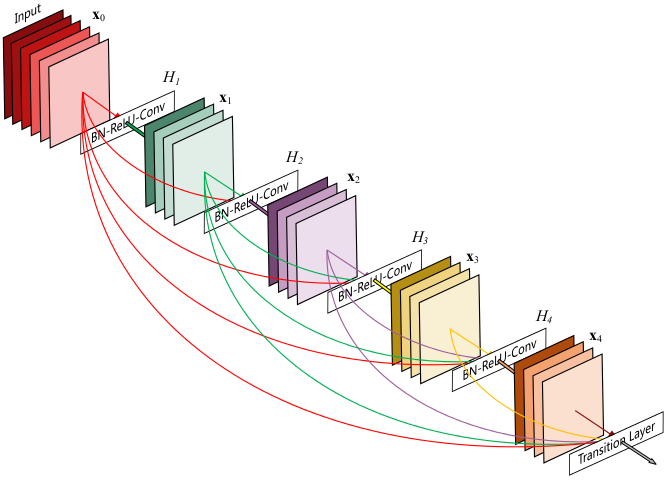
稠密连接:每层以之前层的输出为输入,对于有L层的传统网络,一共有个连接,对于DenseNet,则有。
这篇论文主要参考了Highway Networks,Residual Networks (ResNets)以及GoogLeNet,通过加深网络结构,提升分类结果。加深网络结构首先需要解决的是梯度消失问题,解决方案是:尽量缩短前层和后层之间的连接。比如上图中,层可以直接用到原始输入信息,同时还用到了之前层对处理后的信息,这样能够最大化信息的流动。反向传播过程中,的梯度信息包含了损失函数直接对的导数,有利于梯度传播。
DenseNet有如下优点:
1.有效解决梯度消失问题
2.强化特征传播
3.支持特征重用
4.大幅度减少参数数量
接着说下论文中一直提到的Identity function:
很简单 就是输出等于输入
传统的前馈网络结构可以看成处理网络状态(特征图?)的算法,状态从层之间传递,每个层从之前层读入状态,然后写入之后层,可能会改变状态,也会保持传递不变的信息。ResNet是通过Identity transformations来明确传递这种不变信息。
网络结构:
每层实现了一组非线性变换,可以是Batch Normalization (BN) ,rectified linear units (ReLU) , Pooling , or Convolution (Conv). 第层的输出为。
对于ResNet:

这样做的好处是the gradient flows directly through the identity function from later layers to the earlier layers.
同时呢,由于identity function 和 H的输出通过相加的方式结合,会妨碍信息在整个网络的传播。
受GooLeNet的启发,DenseNet通过串联的方式结合:
这里是一个Composite function,是三个操作的组合:
由于串联操作要求特征图大小一致,而Pooling操作会改变特征图的大小,又不可或缺,于是就有了上图中的分块想法,其实这个想法类似于VGG模型中的“卷积栈”的做法。论文中称每个块为DenseBlock。每个DenseBlock的之间层称为transition layers,由组成。
Growth rate:由于每个层的输入是所有之前层输出的连接,因此每个层的输出不需要像传统网络一样多。这里的输出的特征图的数量都为,即为Growth Rate,用来控制网络的“宽度”(特征图的通道数).比如说第层有的输入特征图,是输入图片的通道数。
虽然说每个层只产生个输出,但是后面层的输入依然会很多,因此引入了Bottleneck layers 。本质上是引入1x1的卷积层来减少输入的数量,的具体表示如下
文中将带有Bottleneck layers的网络结构称为DenseNet-B。
除了在DenseBlock内部减少特征图的数量,还可以在transition layers中来进一步Compression。如果一个DenseNet有m个特征图的输出,则transition layer产生 个输出,其中。对于含有该操作的网络结构称为DenseNet-C。
同时包含Bottleneck layer和Compression的网络结构为DenseNet-BC。
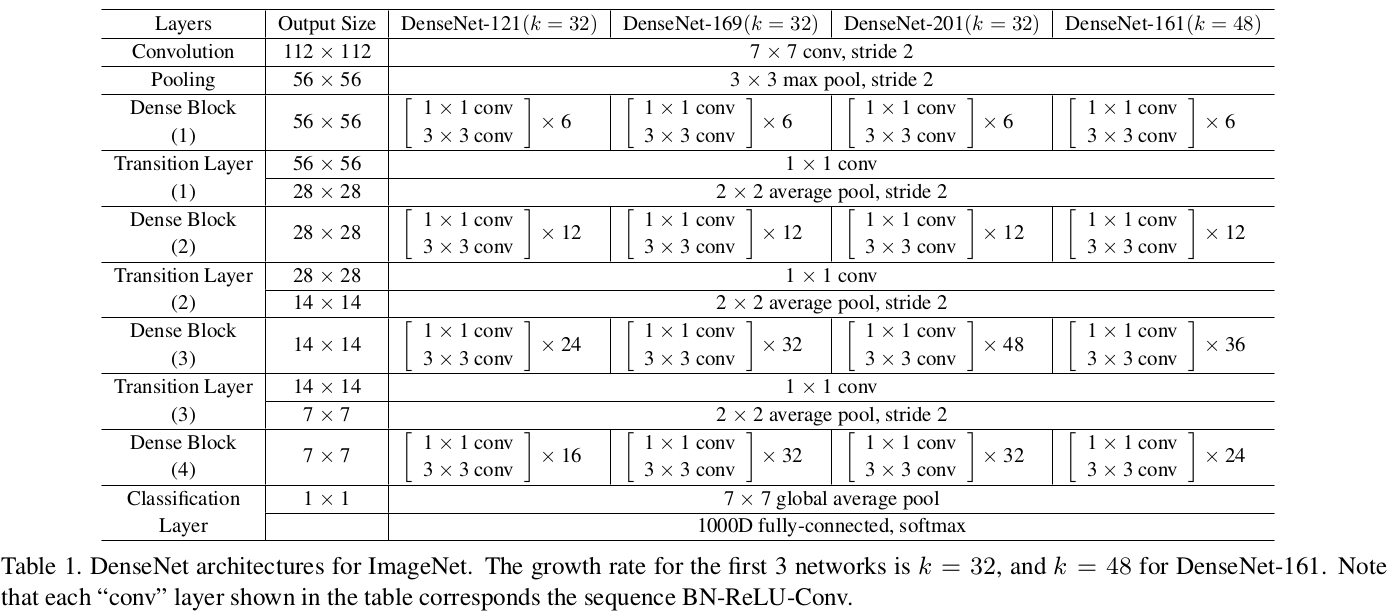
具体的网络结构:
实验以及一些结论
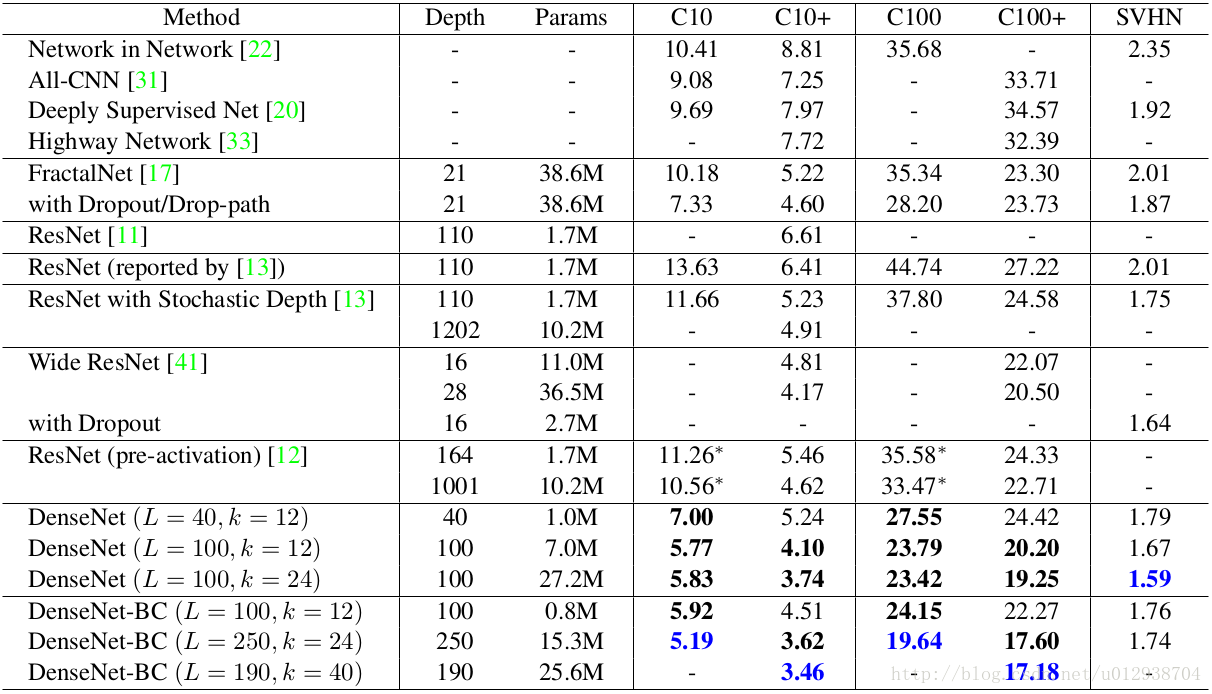
在CIFAR和SVHN上的分类结果(错误率):
表示网络深度,为增长率。蓝色字体表示最优结果,+表示对原数据库进行data augmentation。可以发现DenseNet相比ResNet可以取得更低的错误率,并且使用了更少的参数。
接着看一组对比图:
前两组描述分类错误率与参数量的对比,从第二幅可以看出,在取得相同分类精度的情况下,DenseNet-BC比ResNet少了的参数。第三幅图描述含有10M参数的1001层的ResNet与只有0.8M的100层的DenseNet的训练曲线图。可以发现ResNet可以收敛到更小的loss值,但是最终的test error与DenseNet相差无几。再次说明了DenseNet参数效率(Parameter Efficiency)很高!
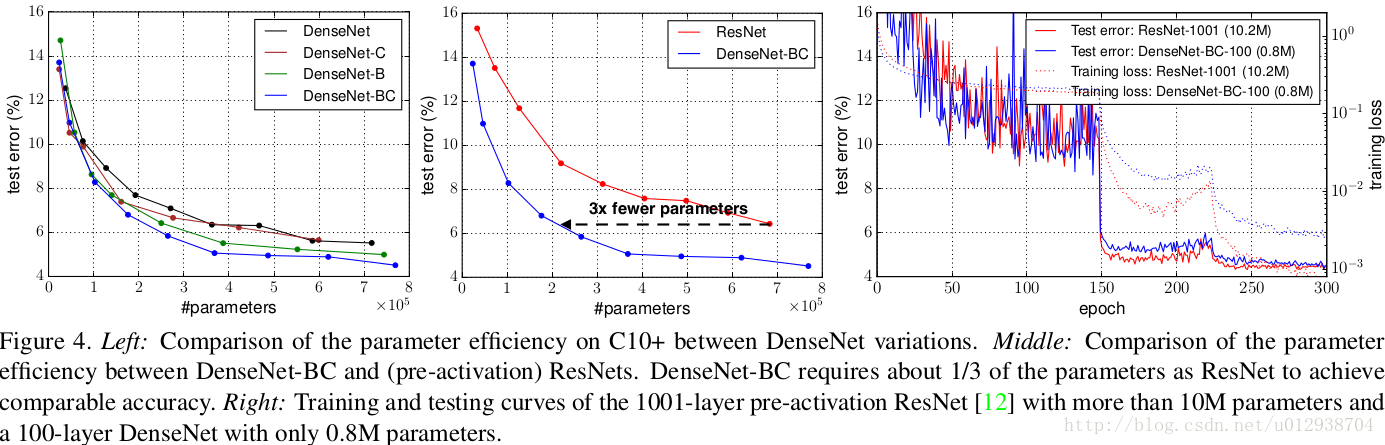
同样的在ImageNet上的分类结果:
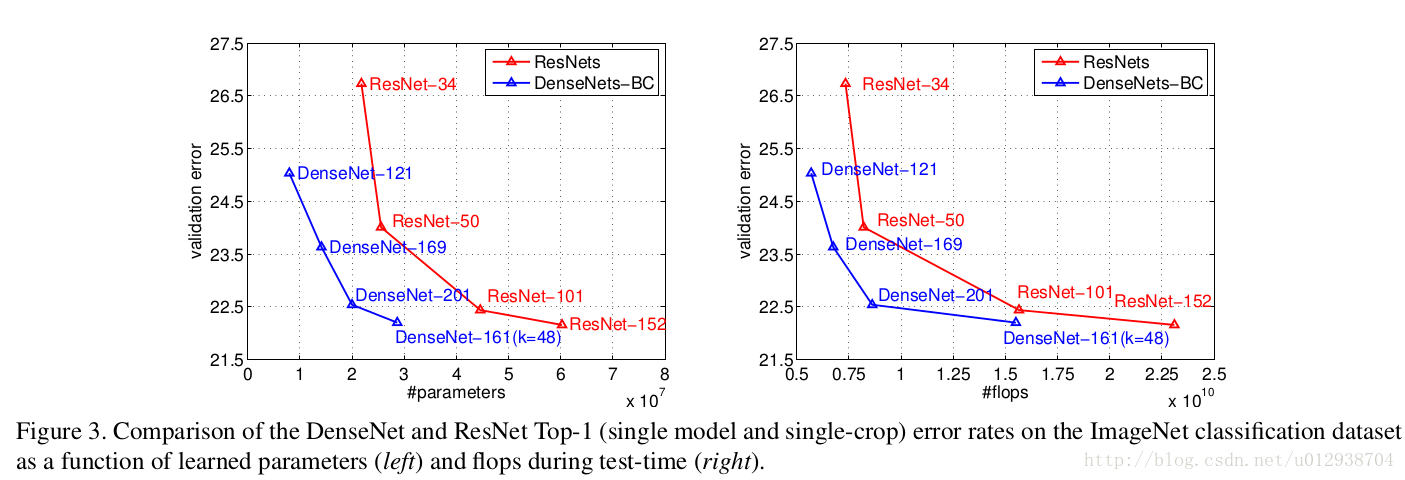
右图使用FLOPS来说明计算量。通过比较ResNet-50,DenseNet-201,ResNet-101,说明计算量方面,DenseNet结果更好。
SEnet
参考:http://blog.csdn.net/u014380165/article/details/78006626
论文:Squeeze-and-Excitation Networks
论文链接:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中,作者采用SENet block和ResNeXt结合在ILSVRC 2017的分类项目中拿到第一,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。
作者在文中将SENet block插入到现有的多种分类网络中,都取得了不错的效果。SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。当然,SE block嵌在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的。
也许通过给某一层特征配备权重的想法很多人都有,那为什么只有SENet成功了?个人认为主要原因在于权重具体怎么训练得到。就像有些是直接根据feature map的数值分布来判断;有些可能也利用了loss来指导权重的训练,不过全局信息该怎么获取和利用也是因人而异。
Figure1表示一个SE block。主要包含Squeeze和Excitation两部分,接下来结合公式来讲解Figure1。
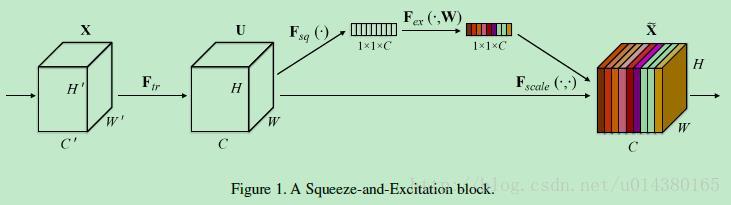
首先Ftr这一步是转换操作(严格讲并不属于SENet,而是属于原网络,可以看后面SENet和Inception及ResNet网络的结合),在文中就是一个标准的卷积操作而已,输入输出的定义如下表示。
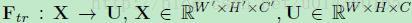
那么这个Ftr的公式就是下面的公式1(卷积操作,vc表示第c个卷积核,xs表示第s个输入)。
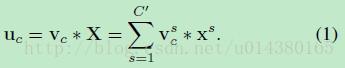
Ftr得到的U就是Figure1中的左边第二个三维矩阵,也叫tensor,或者叫C个大小为H*W的feature map。而uc表示U中第c个二维矩阵,下标c表示channel。
接下来就是Squeeze操作,公式非常简单,就是一个global average pooling:
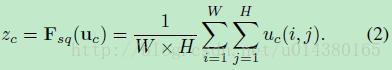
因此公式2就将H*W*C的输入转换成1*1*C的输出,对应Figure1中的Fsq操作。为什么会有这一步呢?这一步的结果相当于表明该层C个feature map的数值分布情况,或者叫全局信息。
再接下来就是Excitation操作,如公式3。直接看最后一个等号,前面squeeze得到的结果是z,这里先用W1乘以z,就是一个全连接层操作,W1的维度是C/r * C,这个r是一个缩放参数,在文中取的是16,这个参数的目的是为了减少channel个数从而降低计算量。又因为z的维度是1*1*C,所以W1z的结果就是1*1*C/r;然后再经过一个ReLU层,输出的维度不变;然后再和W2相乘,和W2相乘也是一个全连接层的过程,W2的维度是C*C/r,因此输出的维度就是1*1*C;最后再经过sigmoid函数,得到s。
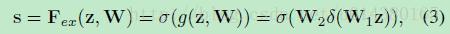
也就是说最后得到的这个s的维度是1*1*C,C表示channel数目。这个s其实是本文的核心,它是用来刻画tensor U中C个feature map的权重。而且这个权重是通过前面这些全连接层和非线性层学习得到的,因此可以end-to-end训练。这两个全连接层的作用就是融合各通道的feature map信息,因为前面的squeeze都是在某个channel的feature map里面操作。
在得到s之后,就可以对原来的tensor U操作了,就是下面的公式4。也很简单,就是channel-wise multiplication,什么意思呢?uc是一个二维矩阵,sc是一个数,也就是权重,因此相当于把uc矩阵中的每个值都乘以sc。对应Figure1中的Fscale。
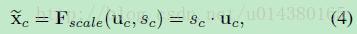
了解完上面的公式,就可以看看在实际网络中怎么添加SE block。Figure2是在Inception中加入SE block的情况,这里的Inception部分就对应Figure1中的Ftr操作。
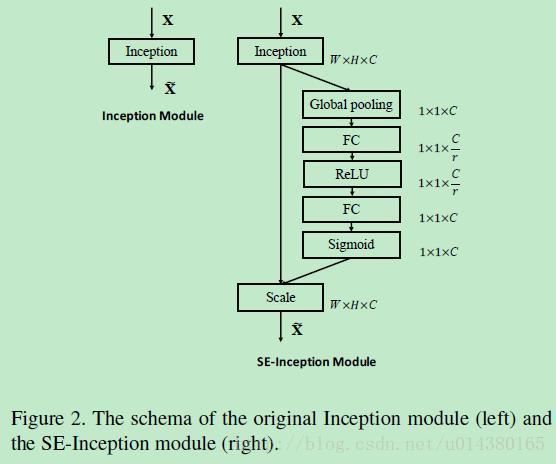
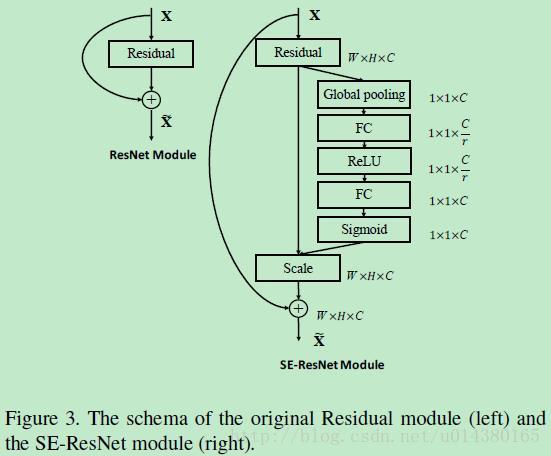
Figure3是在ResNet中添加SE block的情况。
看完结构,再来看添加了SE block后,模型的参数到底增加了多少。其实从前面的介绍可以看出增加的参数主要来自两个全连接层,两个全连接层的维度都是C/r * C,那么这两个全连接层的参数量就是2*C^2/r。以ResNet为例,假设ResNet一共包含S个stage,每个Stage包含N个重复的residual block,那么整个添加了SE block的ResNet增加的参数量就是下面的公式:

除了公式介绍,文中还举了更详细的例子来说明参数增加大概是多少百分比:In total, SE-ResNet-50 introduces 2.5 million additional parameters beyond the 25 million parameters required by ResNet-50, corresponding to a 10% increase in the total number of parameters。而且从公式5可以看出,增加的参数和C关系很大,而网络越到高层,其feature map的channel个数越多,也就是C越大,因此大部分增加的参数都是在高层。同时作者通过实验发现即便去掉最后一个stage的SE block,对模型的影响也非常小(<0.1% top-1 error),因此如果你对参数量的限制要求很高,倒是可以这么做,毕竟具体在哪些stage,哪些block中添加SE block都是自由定义的。
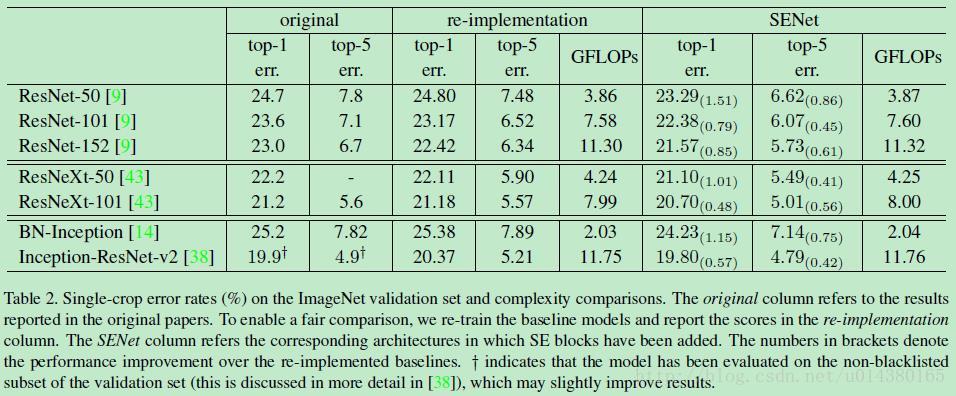
Table2是将SE block添加到ResNet,ResNeXt和Inception三个模型中的效果对比,数据集都是ImageNet,可以看出计算复杂度的增加并不明显(增加的主要是全连接层,全连接层其实主要还是增加参数量,对速度影响不会太大)。
既然是冠军算法,文中也介绍了当时取得冠军时的算法大致组成:Our winning entry comprised a small ensemble of SENets that employed a standard multi-scale and multi-crop fusion strategy to obtain a 2.251% top-5 error on the test set.This result represents a 25% relative improvement on the winning entry of 2016 (2.99% top-5 error). 也就是说其实是多模型做了融合。
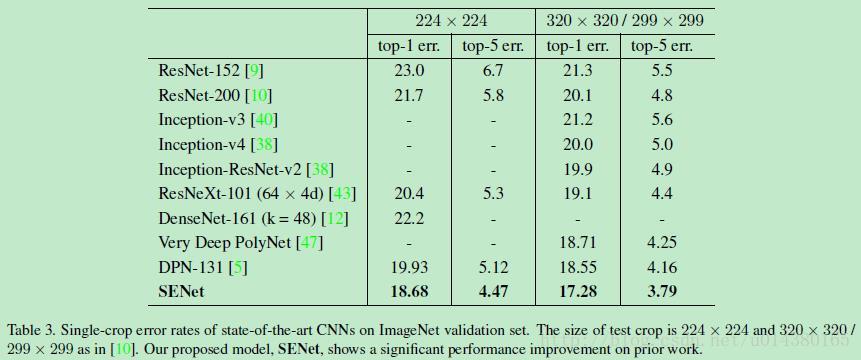
而在融合的多个模型之中:One of our high-performing networks is constructed by integrating SE blocks with a modified ResNeXt,也就是Table3中最后一行的SENet!具体而言是在64*4d 的ResNeXt-152网络中引入了SE block。而这个ResNeXt-152是在ResNeXt-101的基础上根据ResNet-152的叠加方式改造出来的,因为原来的ResNeXt文章中并没有提到152层的ResNeXt,具体改造可以看文章的附录,附录的一些细节可以在以后应用中参考。从Table3可以看出即便是单模型,SENet的效果也比其他算法要好。
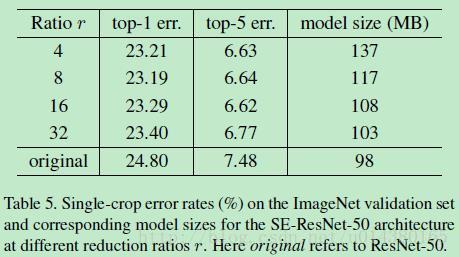
另外前面提到过在SE block中第一个全连接层的维度是C/r * C,这个r在文中取的是16,作用在于将原来输入是1*1*C的feature map缩减为1*1*C/r的feature map,这一就降低了后面的计算量。而下面的Table5则是关于这个参数r取不同值时对结果和模型大小的影响。
最后,除了在ImageNet数据集上做实验,作者还在Places365-Challenge数据集上做了对比,更多实验结果可以参看论文。
附:看了下caffe代码(.prototxt文件),和文章的实现还有些不一样。下图是在Inception中添加SENet的可视化结果:SE-BN-Inception,在Inception中是在每个Inception的后面连上一个SENet,下图的上面一半就是一个Inception,下面一半就是一个SENet,然后这个SENet下面又连着一个新的Inception。
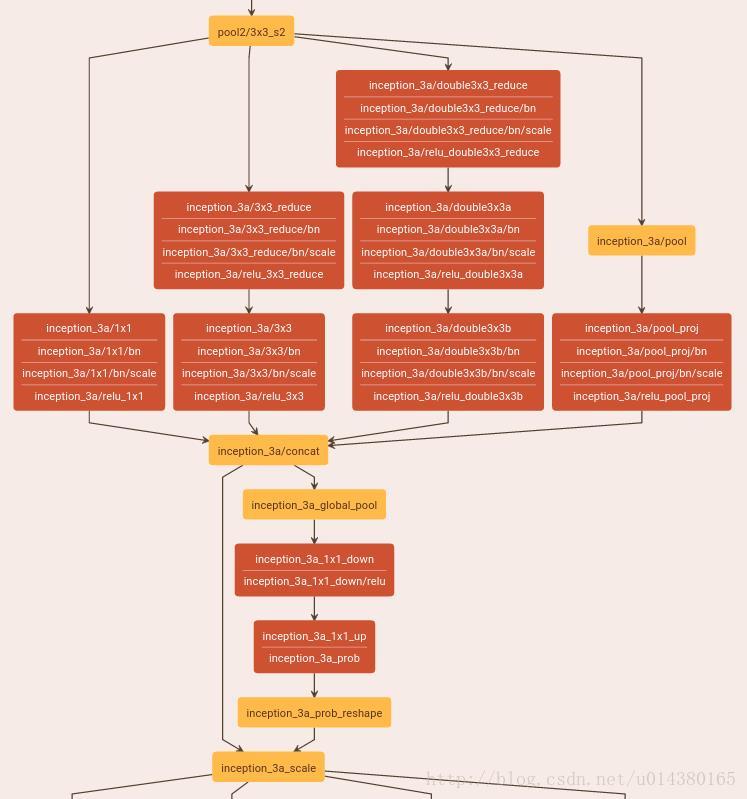
注意看这个SENet的红色部分都是用卷机操作代替文中的全连接层操作实现的,个人理解是为了减少参数(原来一个全连接层是C*C/r个参数,现在变成了C/r个参数了),计算量应该是不影响的,都是C*C/r。具体来说,inception_3a_1*1_down是输出channel为16的1*1卷积,其输入channel是256,这也符合文中说的缩减因子为16(256/16=16);而inception_3a_1*1_up是输出channel为256的1*1卷积。其它层都和文中描述一致,比如inception_3a_global_pool是average pooling,inception_3a_prob是sigmoid函数。
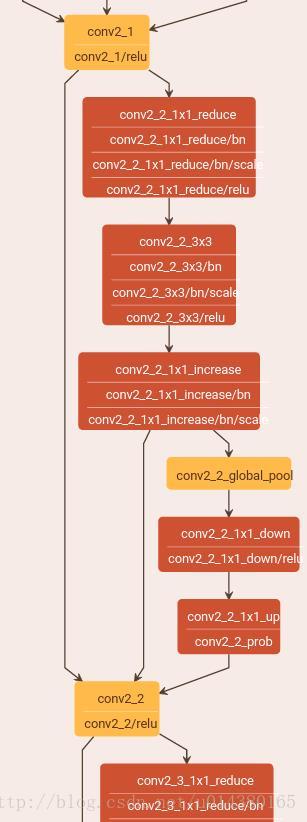
SE-ResNet-50的情况也类似,如下图。在ResNet中都是在Residual block中嵌入SENet。下图最左边的长条连线是原来Residual block的skip connection,右下角的conv2_2_global_pool到conv2_2_prob以及左边那条连线都是SENet。不过也是用两个1*1卷积代替文中的两个全连接层。
Wide Resnet
论文地址:Wide Residual Networks
笔记地址:http://blog.csdn.net/wspba/article/details/72229177
前言
俗话说,高白瘦才是唯一的出路。但在深度学习界貌似并不是这样。Wide Residual Networks就要证明自己,矮胖的神经网络也是潜力股。其实从名字中就可以看出来,Wide Residual Networks(WRNS)源自于Residual Networks,也就是大名鼎鼎的ResNet,之前我们也介绍了,ResNet就是解决随着深度增加所带来的退化问题,它可以将网络深度提升到千层的级别,本身就是以高和瘦出名,可以说是深度学习界的高富帅。然而这一次,大神们剑走偏锋,摒弃了ResNet高瘦的风格,开始在宽度上打起来了注意,而Wide Residual Networks也确实扬眉吐气,从此名声大噪。
动机
作者认为,随着模型深度的加深,梯度反向传播时,并不能保证能够流经每一个残差模块(residual block)的weights,以至于它很难学到东西,因此在整个训练过程中,只有很少的几个残差模块能够学到有用的表达,而绝大多数的残差模块起到的作用并不大。因此作者希望使用一种较浅的,但是宽度更宽的模型,来更加有效的提升模型的性能。
模型结构
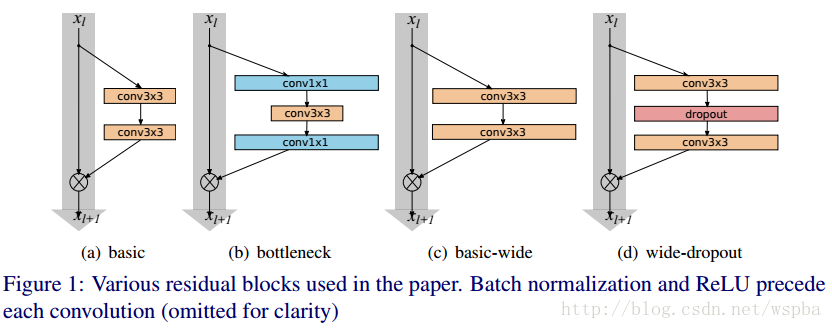
看图,其实很容易理解,(a)和(b)是MSRA提出来的ResNet,一种基本结构,一种bottleneck结构;(c)和(d)就是作者提出来的wide结构。看不出什么来是不是,那下面这个表格就能让你一目了然: 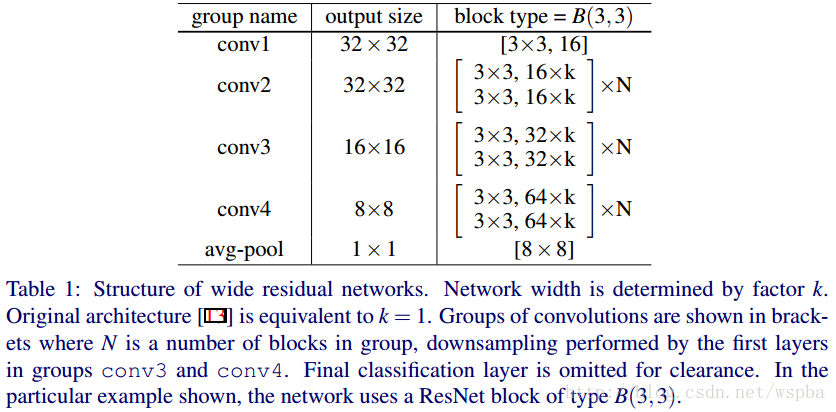
有点眼熟是不是,把表格中的k变为1,是不是就是ResNet论文中,cifar-10实验所使用的网络?还记得吗,ResNet原文中,作者针对cifar-10所使用的的网络,包含三种Residual Block,output channel分别是16、32、64,网络的深度为6*N+2。而在这里,作者给16、32、64之后都加了一个系数k,也就是说,作者是通过增加output channel的数量来使模型变得更wider,从而N可以保持很小的值,就可以是网络达到很好的效果。
当然他确实做到了。 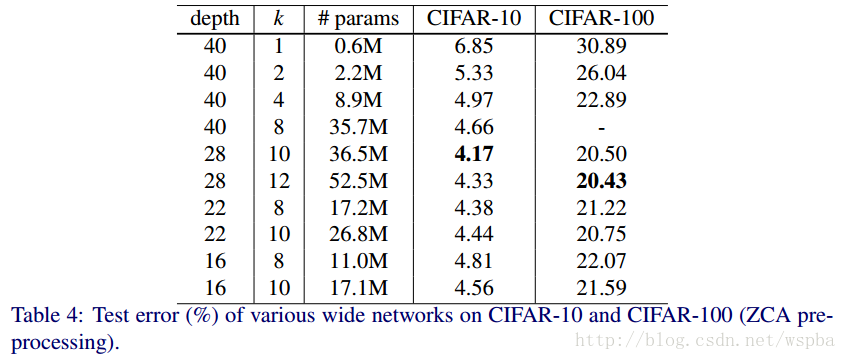
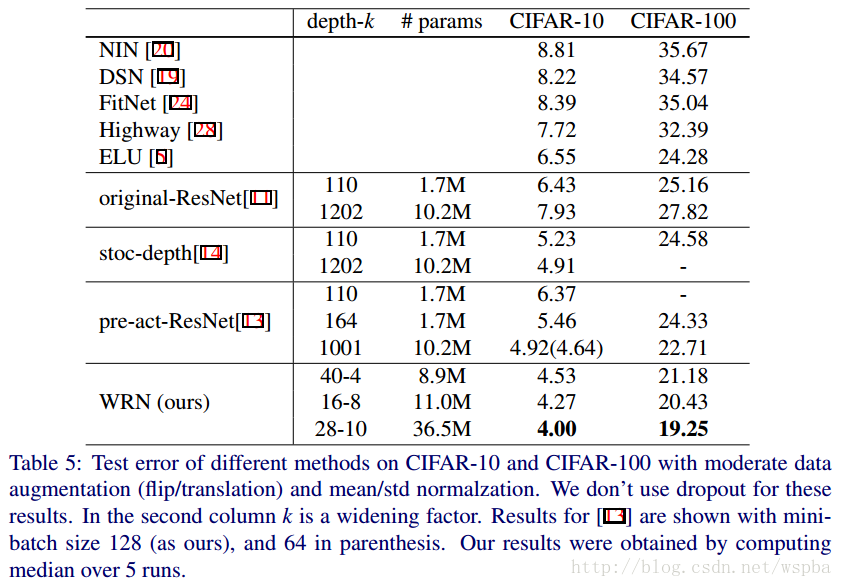
上面结果也确实证明了,增加模型的宽度是对模型的性能是有提升的。不过也不能完全的就认为宽度比深度更好,两者只有相互搭配,达到合适的值,才能取得更好的效果。
后话
其实这篇论文是相对比较简单的,他验证了宽度给模型性能带来的提升,也给大家以后在模型性能遇到瓶颈时提供了一种思路,比如说我在做cifar-10分类任务时,仅仅是将ResNet-20的宽度由16、32、64变为32、64、128,就将分类的性能由92%提升到94%以上,在caffe下,它的caffemodel大小也就10兆出头,和ResNet-56的大小近似,显存占用率也不大,训练速度很快。当然作者文中的WRNS-28-10确实是变态极致的结构了,性能确实好,在我的训练框架下,cifar-10的分类准确率能够逼近97%,但是caffemodel的大小有150M左右,训练的也是非常慢,没记错的话显存应该占用18G左右。所以如果你想在保证在一定准确率的基础上,使得模型复杂度降低,可以从更浅、更加复杂的模型入手。另外我觉得本文还可以尝试的东西可以从文中的另外一个表格入手: 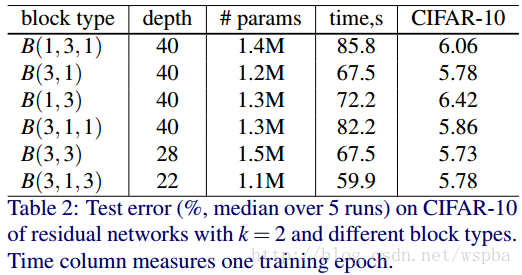
我们可以发现,其实B(3,1,3)在深度最浅、参数量最小、训练时间最短的前提下,在cifar-10的分类错误率上也几乎达到了最好的水平。由于原文中作者只研究了宽度对模型的影响, 因此并没有对这部分内容进行解释。因此这个也是一个可尝试的方向。
另外对于drop-out,其实在WRNS-16-4上,也能够带来性能的提升。虽然dropout是旧办法,但是依然也是好办法,大家大胆去尝试就对了。