Opencv 关键点和描述符(三)—— 核心关键点检测方法
存在着大量的关键点检测算法,它们之间没有明显的优劣,因此 Opencv 提供了一个通用的接口来处理所有的检测器使得用户能够更好地使用它们。
The Harris-Shi-Tomasi feature detector and cv::GoodFeaturesToTrackDetector
Harris基于如下自相关函数
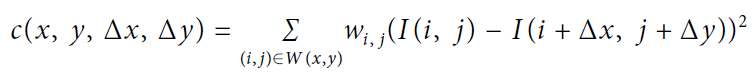
如果 足够小,那么可进行如下近似
![]()
![]()
![]()
上式可以进一步表示为如下形式
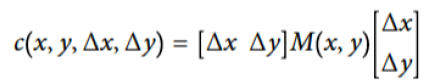
其中

进一步
![]()
Harris 就是基于 H 的特征值对关键点进行检测。如果 H 矩阵的具有两个较大的特征值(表明该点朝两个方向移动均能获得较大的强度变化)则判断该点为关键点。
class cv::GFTTDetector : public cv::Feature2D {
public:
static Ptr<GFTTDetector> create(
int maxCorners = 1000, // Keep this many corners
double qualityLevel = 0.01, // fraction of largest eigenvalue
double minDistance = 1, // Discard corners if this close
int blockSize = 3, // Neighborhood used
bool useHarrisDetector = false, // If false, use Shi Tomasi
double k = 0.04 // Used for Harris metric
);
...
};内部调用的函数
void cv::cornerHarris(
cv::InputArray src, // Input array CV_8UC1
cv::OutputArray dst, // Result array CV_32FC1
int blockSize, // Autocorrelation block sz
int ksize, // Sobel operator size
double k, // Harris's trace weight
int borderType = cv::BORDER_DEFAULT // handle border pix
);
void cv::cornerMinEigenVal(
cv::InputArray src, // Input array CV_8UC1
cv::OutputArray dst, // Result array CV_32FC1
int blockSize, // Autocorrelation block sz
int ksize, = 3 // Sobel operator size
int borderType = cv::BORDER_DEFAULT // handle border pix
);void cornerEigenValsAndVecs(
cv::InputArray src, // Input array CV_8UC1
cv::OutputArray dst, // Result array CV_32FC1
int blockSize, // Autocorrelation block sz
int ksize, // Sobel operator size
int borderType = cv::BORDER_DEFAULT // handle border pix
);The simple blob detector and cv::SimpleBlobDetector
class SimpleBlobDetector : public Feature2D {
public:
struct Params {
Params();
float minThreshold; // First threshold to use
float maxThreshold; // Highest threshold to use
float thresholdStep; // Step between thresholds
size_t minRepeatability; // Blob must appear
// in this many images
float minDistBetweenBlobs; // Blob must be this far
// from others
bool filterByColor; // True to use color filter
uchar blobColor; // always 0 or 255
bool filterByArea; // True to use area filter
float minArea, maxArea; // min and max area to accept
// True to filter on "circularity", and min/max
// ratio to circle area
bool filterByCircularity;
float minCircularity, maxCircularity;
// True to filter on "inertia", and min/max eigenvalue ratio
bool filterByInertia;
float minInertiaRatio, maxInertiaRatio;
// True to filter on convexity, and min/max ratio to hull area
bool filterByConvexity;
float minConvexity, maxConvexity;
void read(const FileNode& fn);
void write(FileStorage& fs) const;
};
static Ptr<SimpleBlobDetector> create(
const SimpleBlobDetector::Params ¶meters
= SimpleBlobDetector::Params()
);
virtual void read(const FileNode& fn);
virtual void write(FileStorage& fs) const;
...
};算法流程
- 将图像转换为灰度图
- 选取一些阈值对图像进行二值化,通常 50-64:10:220-235
- 使用 cv::findContours() 查找轮廓中心点,作为候选关键点位置
- 距离小于 minDistBetweenBlobs 的 blob 或者相应阈值的 blob 将被合并
- 针对合并后的结果得到中心和半径
- 最后基于颜色,大小,半径或者其他筛选得到最终的 blob
The FAST feature detector and cv::FastFeatureDetector
其基本原理是比较某个点周围固定距离的点的亮度,如果有超过阈值的点暗于或亮于该点,则判断该点为关键点。同时,为了解决同一区域选取了多个类似关键点的问题,只保留该区域内以下得分最高的关键点。自适应通用加速分割检测(AGAST)算法通过吧 FAST 算法中的 ID3 决策树改造为二叉树,并能够根据当前处理的图像信息动态且高效地分配决策树,提高了算法的运算效率。

class cv::FastFeatureDetector : public cv::Feature2D {
public:
enum {
TYPE_5_8 = 0, // 8 points, requires 5 in a row
TYPE_7_12 = 1, // 12 points, requires 7 in a row
TYPE_9_16 = 2 // 16 points, requires 9 in a row
};
static Ptr<FastFeatureDetector> create(
int threshold = 10, // center to periphery diff
bool nonmaxSupression = true, // suppress non-max corners?
int type = TYPE_9_16 // Size of circle (see enum)
);
...
};参数说明:
- threshold:像素点强度,必须为整数。这个值通常设置一个相对较大的数,比如 30。
- nonmaxSupression:是否合并邻近关键点
- type:指定合并的参数,比如 cv::FastFeatureDetector::TYPE_9_16 表示 16 个点中必须有超过 9 个过亮或过暗的点
The SIFT feature detector and cv::xfeatures2d::SIFT (Scale Invariant Feature Transform)
其基本原理是使用不同宽度核的高斯核对原始图像进行卷积,之后对相邻核宽的结果进行差值(来近似拉普拉斯核,大大降低的计算量),最后如果某个像素点如果和其周围和上下结果的像素点差别较大,则判定其为关键点。同时,SIFT 通过找到关键点的关键方向(特征值最大的方向)实现了旋转不变性。


class SIFT : public Feature2D {
public:
static Ptr<SIFT> create(
int nfeatures = 0, // Number of features to use
int nOctaveLayers = 3, // Layers in each octave
double contrastThreshold = 0.04, // to filter out weak features
double edgeThreshold = 10, // to filter out "edge" features
double sigma = 1.6 // variance of level-0 Gaussian
);
int descriptorSize() const; // descriptor size, always 128
int descriptorType() const; // descriptor type, always CV_32F
...
};参数说明:
- nfeatures:希望查找的特征数,如果设置为默认值 0,将查找所有的特征值
- nOctaveLayers:参与计算的不同尺度的高斯核的数目,实际使用为设置值加 2。比如上图中,值为 2
- contrastThreshold:用于对候选的关键点进行筛选,是否局部极值点足够不同
- edgeThreshold:用于对候选的关键点进行筛选,空间特征值是否足够相同,从而去除边
- sigma:用于图像的预平滑。可以自己使用高斯滤波器对图像进行平滑,不过这样算法对此一无所知,从而浪费大量的时间查找并不关注的关键点。如果通过 sigma 指定,那么小于该尺度的关键点将被自动忽略。
The SURF feature detector and cv::xfeatures2d::SURF (Speeded-Up Robust Features)
针对 SIFT 计算量大,速度慢的缺点,SURF 直接使用 box filter(类似 Harr 小波) 近似两个高斯核的差值,这种操作可以通过 integral image 技术得以快速计算。


class cv::xfeatures2d::SURF : public cv::Feature2D {
public:
static Ptr<SURF> create(
double hessianThreshold = 100, // Keep features above this
int nOctaves = 4, // Num of pyramid octaves
int nOctaveLayers = 3, // Num of images in each octave
bool extended = false, // false: 64-element,
// true: 128-element descriptors
bool upright = false, // true: don't compute orientation
// (w/out is much faster)
);
int descriptorSize() const; // descriptor size, 64 or 128
int descriptorType() const; // descriptor type, always CV_32F
...
};
typedef SURF SurfFeatureDetector;
typedef SURF SurfDescriptorExtractor;参数说明:
- hessianThreshold:Hessian 矩阵的行列式的关键点阈值。默认值 100 是一个较低的值,经典值比如 1500
- extended:是否使用 128 维特性集合
- upright:不考虑关键点的方向,直接设置为垂直,这被称为 upright-SURF 或者 U-SURF
- nOctave, nOctaveLayer:多少尺度及范围将参与计算。nOctave 的默认值 4 可以适用于大多数场景,减少到 3 并不会获得太多的性能提高。nOctaveLayers 被某些研究证明设为 4 可能更有用,但计算代价更大。
The Star/CenSurE feature detector and cv::xfeatures2d::StarDetector
Star 特性,也被称为 Center Surround Extremum (or CenSurE),最初被用于视觉度量。由于 Harris 角或者 FAST 并不满足尺度不变性,而 SIFT 由于图像金字塔又无法满足高精度定位,而 Star 就是为解决尺度不变性和高精度定位的需求。其主要流程包括以下两个阶段,第一阶段使用类似 SIFT 的 difference of Gaussians(GoD)提取局部极值点,之后第二阶段使用 Harris 度量的尺度自适应版本去除像边的特性。

// Constructor for the Star detector object:
//
class cv::xfeatures2d::StarDetector : public cv::Feature2D {
public:
static Ptr<StarDetector> create(
int maxSize = 45, // Largest feature considered
int responseThreshold = 30, // Minimum wavelet response
int lineThresholdProjected = 10, // Threshold on Harris measure
int lineThresholdBinarized = 8, // Threshold on binarized Harris
int suppressNonmaxSize = 5 // Keep only best features
// in this size space
);
...
};参数说明:
- maxSize:搜索的最大特征大小,其只能是 4, 6, 8, 11, 12, 16, 22, 23, 32, 45, 46, 64, 90, or 128
- responseThreshold:CenSurE 核判断关键点的阈值。为适应所有尺度,在判断之前进行了归一化
- lineThresholdProjected,lineThresholdBinarized:第一个阈值用于去除类似直线的关键点,而第二个阈值用于去除非尺度空间极值点
- supressNonmaxSize:去除该区域内非最大值的关键点
SIFT与SURF算法使用梯度统计直方图来描述的描述子都属于浮点型特征描述子。但它们计算起来,算法复杂,效率较低,所以后来就出现了许多新型的特征描述算法,如BRIEF。后来很多二进制串描述子ORB,BRISK,FREAK等都是在它上面的基础上的改进。
The BRIEF descriptor extractor and cv::BriefDescriptorExtractor
BRIEF(Binary Robust Independent Elementary Features,二值鲁邦独立元素特征),其并不检测关键点,而是将其他算法检测到的关键点转换为描述符。BRIEF 就是描述一系列测试的描述符,它比较某个单一像素点与特征中的一些其他像素的的亮度,并产生 0-1 的二值化结果。为了降低噪声的影响,在处理前通常会使用高斯滤波对图像进行平滑。而由于该描述符是一个二值字符串,它不仅能够被更快地计算和存储,也能够更有效地进行比较。
class cv::xfeatures2d::BriefDescriptorExtractor : public cv::Feature2D {
public:
static Ptr<BriefDescriptorExtractor> create(
int bytes = 32, // can be equal 16, 32 or 64 bytes
bool use_orientation = false // true if point pairs are "rotated"
// according to keypoint orientation
);
virtual int descriptorSize() const; // number of bytes for features
virtual int descriptorType() const; // Always returns CV_8UC1
};而具体的描述符计算,cv::xfeatures2d::BriefDescriptorExtractor 使用其基类 cv::Feature2D 中的 compute() 函数实现。
BRISK算法
BRISK 是对 BRIEF 的改进,首先 BRIEF 只是一种计算描述符的方法,而 BRISK 可以描述符检测器,同时,BRISK 虽然本质上类似于 BRIEF 但其采用了邻域采样模式,即以特征点为圆心,构建多个不同半径的离散化 Bresenham 同心圆,然后再每一个同心圆上获得具有相同间距的N个采样点。提高了特征的整体鲁棒性。


class cv::BRISK : public cv::Feature2D {
public:
static Ptr<BRISK> create(
int thresh = 30, // Threshold passed to FAST
int octaves = 3, // N doublings in pyramid
float patternScale = 1.0f // Rescale default pattern
);
int descriptorSize() const; // descriptor size
int descriptorType() const; // descriptor type
static Ptr<BRISK> create( // Compute BRISK features
const vector<float>& radiusList, // Radii of sample circles
const vector<int>& numberList, // Sample points per circle
float dMax = 5.85f, // Max distance for short pairs
float dMin = 8.2f, // Min distance for long pairs
const vector<int>& indexChange = std::vector<int>() // Unused
);
};The ORB feature detector and cv::ORB
为了针对实时应用场景,使用基于 BRIEF 的描述符和基于 FAST 的关键点检测算法实现了 ORB 特征检测器。其首先使用 FAST 得到候选的关键点集合;为了去克服 FAST 容易将边作为角的缺点,其计算 Harris 角来限制两个特征值的差异。同时,ORB 相比于 FAST 给出了特征的角度信息。

class ORB : public Feature2D {
public:
// the size of the signature in bytes
enum { kBytes = 32, HARRIS_SCORE = 0, FAST_SCORE = 1 };
static Ptr<ORB> create(
int nfeatures = 500, // Maximum features to compute
float scaleFactor = 1.2f, // Pyramid ratio (greater than 1.0)
int nlevels = 8, // Number of pyramid levels to use
int edgeThreshold = 31, // Size of no-search border
int firstLevel = 0, // Always '0'
int WTA_K = 2, // Pts in each comparison: 2, 3, or 4
int scoreType = 0, // Either HARRIS_SCORE or FAST_SCORE
int patchSize = 31, // Size of patch for each descriptor
int fastThreshold = 20 // Threshold for FAST detector
);
int descriptorSize() const; // descriptor size (bytes), always 32
int descriptorType() const; // descriptor type, always CV_8U
};参数说明:通常保持默认值就能得到满意的结果
- nfeatures:一次希望得到的特征数
- scaleFactor,nlevels:尺度变换因子和层数
- edgeThreshold,patchSize:图像边缘阈值和计算区域大小,必须保证 edgeThreshold 大于等于 patchSize
- firstLevel:设置第一层的变换尺度。设置更大的值将导致更小的尺度严重受到噪声的影响
- WTA_K:tuple 大小,控制多少个像素点将参与一次计算
- scoreType:cv::ORB::HARRIS_SCORE(使用 Harris 度量,效果好速度慢) or cv::ORB::FAST_SCORE(直接基于 FAST,效果差速度快)
The FREAK descriptor extractor and cv::xfeatures2d::FREAK
FREAK (Fast Retina KeyPoint,快速视网膜关键点)根据视网膜原理进行点对采样,中间密集一些,离中心越远越稀疏。并且由粗到精构建描述子,穷举贪婪搜索找相关性小的。42个感受野,一千对点的组合,找前512个即可。这512个分成4组,前128对相关性更小,可以代表粗的信息,后面越来越精。匹配的时候可以先看前16bytes,即代表精信息的部分,如果距离小于某个阈值,再继续,否则就不用往下看了。
class FREAK : public Features2D {
public:
static Ptr<FREAK> create(
bool orientationNormalized = true, // enable orientation normalization
bool scaleNormalized = true, // enable scale normalization
float patternScale = 22.0f, // scaling of the description pattern
int nOctaves = 4, // octaves covered by detected keypoints
const vector<int>& selectedPairs = vector<int>() // user selected pairs
);
virtual int descriptorSize() const; // returns the descriptor length in bytes
virtual int descriptorType() const; // returns the descriptor type
...
};参数说明:绝大多数情况可以使用默认值
- orientationNormalized:是否使描述符具有方向不变性
- scaleNormalized:是否在计算特征向量之前将特征周围的图像缩放到 keypoint 的大小
- patternScale:均匀的缩放 FREAK 的接受域模式。其主要与 nOctave 参数相关,尽量不要修改默认值。
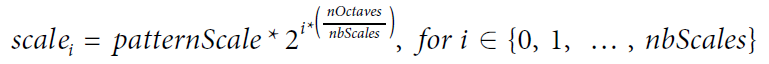
nbScales 是总缩放尺度数,其中每次尺度数都是固定,而不同尺度的空间将随着 nOctave 的增大而增大。
- selectedPairs:这个提供一个专业的功能,使用指定的比较对构建描述符的构建。而其维数必须为 512 的整数向量。普通用户并不需要使用这个参数,只有那些阅读了 FREAK 原始论文的用户可能希望学习过程从而最大效率的使用自己的数据集
Dense feature grids and the cv::DenseFeatureDetector class
其并不检测特征,而是将图像分为横竖的多个方格,而针对每个方格检测特征。最终也证明,在大多数应用中,其不但充分,而且相当可取。
class cv::DenseFeatureDetector : public cv::FeatureDetector {
public:
explicit DenseFeatureDetector(
float initFeatureScale = 1.f, // Size of first layer
int featureScaleLevels = 1, // Number of layers
float featureScaleMul = 0.1f, // Scale factor for layers
int initXyStep = 6, // Spacing between features
int initImgBound = 0, // No-generate boundary
bool varyXyStepWithScale = true, // if true, scale 'initXyStep'
bool varyImgBoundWithScale = false // if true, scale 'initImgBound'
);
cv::AlgorithmInfo* info() const;
...
};参数说明:
- initFeatureScale:设置第一层特征的大小。默认值 1.0 通常不能满足要求,你需要根据自己图像的特征和所使用的描述符进行修改
- featureScaleLevels,featureScaleMul:如果希望产生多层次的特征,可以设置 featureScaleLevels 大于 1。而 featureScaleMul 就是对应的层的缩放系数
- initXyStep,varyXyStepWithScale:设置特征之间的步长,其作用于所有层,除非 varyXyStepWithScale 被设置为 true。这样,不同层的步长将使用 featureScaleMul 进行缩放
- initImgBound,varyImgBoundWithScale:通常不会是图像边缘查找特征,而该参数可以设置距离图像边缘的距离。同样通过设置 varyImgBoundWithScale 可以设置该边界是否随尺度变化而变化