对于每个候选关键词,其得分由五部分加权求和得到: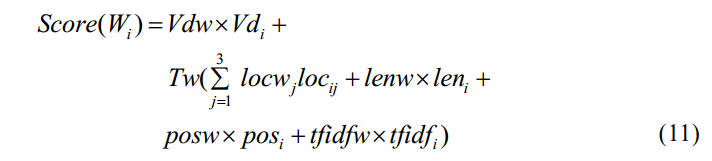
Vd: 单词居间度密度. loc:单词所在文章的位置得分. len: 单词长度得分。
pos: 单词所属词性得分. tfidf:单词的TFIDF值.
论文综合考虑了每个中文字词的各个属性。
代码在我的github :https://github.com/timor1988/SKE
算法里难点在于居间度密度的理解和计算:实现过程中需要用到"最短路径dijkstra算法"。
对于每个候选关键词,其得分由五部分加权求和得到:
Vd: 单词居间度密度. loc:单词所在文章的位置得分. len: 单词长度得分。
pos: 单词所属词性得分. tfidf:单词的TFIDF值.
论文综合考虑了每个中文字词的各个属性。
代码在我的github :https://github.com/timor1988/SKE
算法里难点在于居间度密度的理解和计算:实现过程中需要用到"最短路径dijkstra算法"。