目录
1.Python中文文本分析与可视化
- 读取数据
#!pip install wordcloud #安装词云
import warnings
warnings.filterwarnings("ignore")
import jieba #分词包
import numpy #numpy计算包
import codecs #codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
from wordcloud import WordCloud#词云包
df = pd.read_csv('./data/entertainment_news.csv',encoding='utf-8')
print(df.head())
print(len(df))
df = df.dropna() #去除空值所在的整条(行)数据
print(len(df))
- 分词
#转换list
contents = df['content'].values.tolist()
#分词
segment = []
for content in contents:
try:
segs = jieba.lcut(content)
for seg in segs:
if len(seg)>1 and seg != '\r\n':
segment.append(seg)
except:
print(content)
continue- 去停用词
#把分词结果构造成DataFrame
words_df = pd.DataFrame({'segment':segment})
print(len(words_df))
stopwords = pd.read_csv("./data/stopwords.txt",index_col=False,quoting=3,sep='\t',names=['stopword'])
words_df = words_df[~words_df['segment'].isin(stopwords['stopword'])] #去除停止词
print(len(words_df))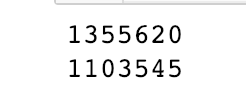
- 统计词频
#统计词频
words_stat = words_df.groupby(by=['segment'])['segment'].agg({'词频':numpy.size})
words_stat = words_stat.reset_index().sort_values(by=['词频'],ascending=False) #降序
print(words_stat.head())
- 构建词云
matplotlib.rcParams['figure.figsize'] = (10.0,6.0)
#设置中文字体 背景颜色等
wordcloud = WordCloud(font_path='./data/simhei.ttf',background_color='black',max_font_size=80)
#字典推导式
word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values} #取词频最高的前1000个词 (词,词频)->{词:词频}
wordcloud = wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)#可视化词频最高的前1000个词 字体越大 词频越高
- 自定义背景
from scipy.misc import imread
matplotlib.rcParams['figure.figsize'] = (15.0,15.0)
from wordcloud import WordCloud,ImageColorGenerator
bimg = imread('./image/entertainment.jpeg') #读入背景图片
plt.imshow(bimg) #可视化背景图片
#使用上述图片 自定义背景
#设置背景颜色 字体 自定义背景
wordcloud = WordCloud(background_color='white',mask=bimg,font_path='./data/simhei.ttf',max_font_size=200)
#字典推导式
word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values} #取词频最高的前1000个词 (词,词频)->{词:词频}
wordcloud = wordcloud.fit_words(word_frequence)
bimgColors = ImageColorGenerator(bimg)
plt.imshow(wordcloud.recolor(color_func=bimgColors))
2.新闻关键词抽取
- 基于TF-IDF的关键词抽取
import jieba.analyse as analyse
import pandas as pd
#技术类新闻
df = pd.read_csv('./data/technology_news.csv',encoding='utf-8').dropna()
print(len(df)) #新闻数量/数据量
#转换列表
contents = df['content'].values.tolist()
contents = ' '.join(contents) #把所有的新闻连接起来
print(analyse.extract_tags(contents,topK=30,withWeight=False,allowPOS=()))
import jieba.analyse as analyse
import pandas as pd
#军事类新闻
df = pd.read_csv("./data/military_news.csv", encoding='utf-8').dropna()
print(len(df)) #新闻数量/数据量
#转换列表
contents=df.content.values.tolist()
contents = " ".join(contents)#把所有的新闻连接起来
print(analyse.extract_tags(contents, topK=30, withWeight=False, allowPOS=()))
- 基于TextRank的关键词抽取
import jieba.analyse as analyse
import pandas as pd
#军事类新闻
df = pd.read_csv('./data/military_news.csv',encoding='utf-8')
df = df.dropna()
print(len(df)) #新闻数量/数据量
#转换列表
contents=df.content.values.tolist()
contents = "".join(contents)#把所有的新闻连接起来
print(analyse.textrank(contents, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')))
print("---------------------我是分割线----------------")
print(analyse.textrank(contents, topK=20, withWeight=False, allowPOS=('ns', 'n')))