切片与MapTask并行决定机制
1.为什么会有切片机制?
因为大数据的处理都是在分布式集群上进行,而且最初设计的理念就是集群部署在廉价的机器上,所以为了达到最高的效率最快的速度,会把数据分成多个块分别分到不同的集群机器上然后执行相同的操作!这样就可以快速器高效了。由此可见如何切块也是job提交流程中非常重要的一环了,所以后面也会主要去介绍。
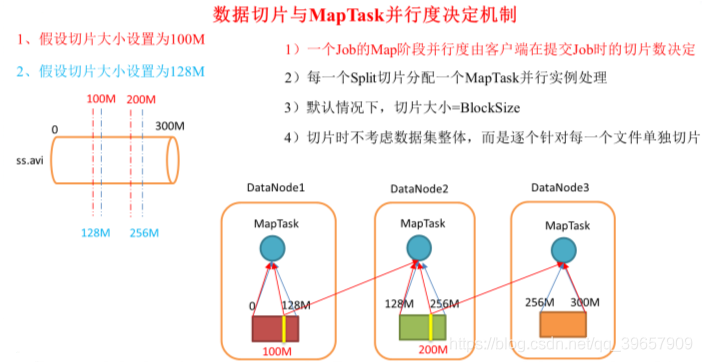
2.机制图解
3.概念简介
数据块:Block是HDFS物理上把数据分成一块一块
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
注:MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。但并不是开越多的MapTask就越好,如1k的数据开多个MapTask反而起到了相反的作用
版权声明:本博客为记录本人自学感悟,转载需注明出处!
https://me.csdn.net/qq_39657909