
对方不想和你说话,并向你扔了一串数…… 而你必须从这一串数字中找到“250”这个高大上的感人数字。
输入格式:
输入在一行中给出不知道多少个绝对值不超过1000的整数,其中保证至少存在一个“250”。
输出格式:
在一行中输出第一次出现的“250”是对方扔过来的第几个数字(计数从1开始)。题目保证输出的数字在整型范围内。
输入样例:
888 666 123 -233 250 13 250 -222
输出样例:
5水题
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 int main() 5 { 6 int x,p=1,ac=-1; 7 while(scanf("%d",&x)!=EOF) 8 { 9 if(x==250&&ac==-1)ac=p; 10 p++; 11 } 12 printf("%d\n",ac); 13 return 0; 14 }
世界上不同国家有不同的写日期的习惯。比如美国人习惯写成“月-日-年”,而中国人习惯写成“年-月-日”。下面请你写个程序,自动把读入的美国格式的日期改写成中国习惯的日期。
输入格式:
输入在一行中按照“mm-dd-yyyy”的格式给出月、日、年。题目保证给出的日期是1900年元旦至今合法的日期。
输出格式:
在一行中按照“yyyy-mm-dd”的格式给出年、月、日。
输入样例:
03-15-2017
输出样例:
2017-03-15水题
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 int main() 5 { 6 int m,d,y; 7 scanf("%d-%d-%d",&m,&d,&y); 8 printf("%04d-%02d-%02d\n",y,m,d); 9 return 0; 10 }
天梯图书阅览室请你编写一个简单的图书借阅统计程序。当读者借书时,管理员输入书号并按下S键,程序开始计时;当读者还书时,管理员输入书号并按下E键,程序结束计时。书号为不超过1000的正整数。当管理员将0作为书号输入时,表示一天工作结束,你的程序应输出当天的读者借书次数和平均阅读时间。
注意:由于线路偶尔会有故障,可能出现不完整的纪录,即只有S没有E,或者只有E没有S的纪录,系统应能自动忽略这种无效纪录。另外,题目保证书号是书的唯一标识,同一本书在任何时间区间内只可能被一位读者借阅。
输入格式:
输入在第一行给出一个正整数N(≤10),随后给出N天的纪录。每天的纪录由若干次借阅操作组成,每次操作占一行,格式为:
书号([1, 1000]内的整数) 键值(S或E) 发生时间(hh:mm,其中hh是[0,23]内的整数,mm是[0, 59]内整数)
每一天的纪录保证按时间递增的顺序给出。
输出格式:
对每天的纪录,在一行中输出当天的读者借书次数和平均阅读时间(以分钟为单位的精确到个位的整数时间)。
输入样例:
3
1 S 08:10
2 S 08:35
1 E 10:00
2 E 13:16
0 S 17:00
0 S 17:00
3 E 08:10
1 S 08:20
2 S 09:00
1 E 09:20
0 E 17:00
输出样例:
2 196
0 0
1 60小坑:当出现SSE的时候,得把第一个S忽视,因为它没有E
四舍五入可以%.0f进行输出
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 int ti[1005]; 5 bool live[1005]; 6 int main() 7 { 8 int day,n=0,id,th,tm; 9 int E=0,T=0; 10 char s[2]; 11 scanf("%d",&day); 12 while(scanf("%d%s%d:%d",&id,s,&th,&tm)!=EOF) 13 { 14 if(id==0) 15 { 16 n++; 17 printf("%d %.0f\n",E,E==0?E:T*1./E); 18 E=0,T=0; 19 memset(live,false,sizeof live); 20 continue; 21 } 22 if(day==n)break; 23 if(s[0]=='S')//借书 24 ti[id]=th*60+tm,live[id]=true; 25 else if(s[0]=='E'&&live[id])//已借去还书 26 live[id]=false,E++,T+=th*60+tm-ti[id]; 27 } 28 return 0; 29 }
大家应该都会玩“锤子剪刀布”的游戏:两人同时给出手势,胜负规则如图所示:
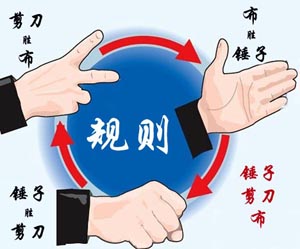
现要求你编写一个稳赢不输的程序,根据对方的出招,给出对应的赢招。但是!为了不让对方输得太惨,你需要每隔K次就让一个平局。
输入格式:
输入首先在第一行给出正整数K(≤10),即平局间隔的次数。随后每行给出对方的一次出招:ChuiZi代表“锤子”、JianDao代表“剪刀”、Bu代表“布”。End代表输入结束,这一行不要作为出招处理。
输出格式:
对每一个输入的出招,按要求输出稳赢或平局的招式。每招占一行。
输入样例:
2
ChuiZi
JianDao
Bu
JianDao
Bu
ChuiZi
ChuiZi
End
输出样例:
Bu
ChuiZi
Bu
ChuiZi
JianDao
ChuiZi
Bu水题当p为k+1的倍数时,需要平局
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 int main() 5 { 6 int k,p=1; 7 char s[10]; 8 scanf("%d",&k); 9 while(scanf("%s",s)!=EOF) 10 { 11 if(s[0]=='E')break; 12 if(p%(k+1)) 13 { 14 if(s[0]=='C')printf("Bu\n"); 15 else if(s[0]=='J')printf("ChuiZi\n"); 16 else if(s[0]=='B')printf("JianDao\n"); 17 } 18 else 19 { 20 if(s[0]=='C')printf("ChuiZi\n"); 21 else if(s[0]=='J')printf("JianDao\n"); 22 else if(s[0]=='B')printf("Bu\n"); 23 } 24 p++; 25 } 26 return 0; 27 }
据说所有程序员学习的第一个程序都是在屏幕上输出一句“Hello World”,跟这个世界打个招呼。作为天梯赛中的程序员,你写的程序得高级一点,要能跟任意指定的星球打招呼。
输入格式:
输入在第一行给出一个星球的名字S,是一个由不超过7个英文字母组成的单词,以回车结束。
输出格式:
在一行中输出Hello S,跟输入的S星球打个招呼。
输入样例:
Mars
输出样例:
Hello Mars水题
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 int main() 5 { 6 string s; 7 cin>>s; 8 cout<<"Hello "<<s; 9 return 0; 10 }
这里所谓的“光棍”,并不是指单身汪啦~ 说的是全部由1组成的数字,比如1、11、111、1111等。传说任何一个光棍都能被一个不以5结尾的奇数整除。比如,111111就可以被13整除。 现在,你的程序要读入一个整数x,这个整数一定是奇数并且不以5结尾。然后,经过计算,输出两个数字:第一个数字s,表示x乘以s是一个光棍,第二个数字n是这个光棍的位数。这样的解当然不是唯一的,题目要求你输出最小的解。
提示:一个显然的办法是逐渐增加光棍的位数,直到可以整除x为止。但难点在于,s可能是个非常大的数 —— 比如,程序输入31,那么就输出3584229390681和15,因为31乘以3584229390681的结果是111111111111111,一共15个1。
输入格式:
输入在一行中给出一个不以5结尾的正奇数x(<1000)。
输出格式:
在一行中输出相应的最小的s和n,其间以1个空格分隔。
输入样例:
31
输出样例:
3584229390681 15模拟下大数除以小数,now/x为商
#include<bits/stdc++.h> using namespace std; int main() { int x,p=0,now=0,Len=0; scanf("%d",&x); while(++Len) { now=now*10+1; if(p||now/x) cout<<now/x,p=1; now%=x; if(now==0) { cout<<' '<<Len; break; } } return 0; }
你永远叫不醒一个装睡的人 —— 但是通过分析一个人的呼吸频率和脉搏,你可以发现谁在装睡!医生告诉我们,正常人睡眠时的呼吸频率是每分钟15-20次,脉搏是每分钟50-70次。下面给定一系列人的呼吸频率与脉搏,请你找出他们中间有可能在装睡的人,即至少一项指标不在正常范围内的人。
输入格式:
输入在第一行给出一个正整数N(≤10)。随后N行,每行给出一个人的名字(仅由英文字母组成的、长度不超过3个字符的串)、其呼吸频率和脉搏(均为不超过100的正整数)。
输出格式:
按照输入顺序检查每个人,如果其至少一项指标不在正常范围内,则输出其名字,每个名字占一行。
输入样例:
4
Amy 15 70
Tom 14 60
Joe 18 50
Zoe 21 71
输出样例:
Tom
Zoe水题
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 int main() 5 { 6 int n,a,b; 7 char name[5]; 8 scanf("%d",&n); 9 for(int i=0;i<n;i++) 10 { 11 scanf("%s%d%d",name,&a,&b); 12 if(a<15||20<a||b<50||70<b)printf("%s\n",name); 13 } 14 return 0; 15 }
给定两个矩阵A和B,要求你计算它们的乘积矩阵AB。需要注意的是,只有规模匹配的矩阵才可以相乘。即若A有Ra行、Ca列,B有Rb行、Cb列,则只有Ca与Rb相等时,两个矩阵才能相乘。
输入格式:
输入先后给出两个矩阵A和B。对于每个矩阵,首先在一行中给出其行数R和列数C,随后R行,每行给出C个整数,以1个空格分隔,且行首尾没有多余的空格。输入保证两个矩阵的R和C都是正数,并且所有整数的绝对值不超过100。
输出格式:
若输入的两个矩阵的规模是匹配的,则按照输入的格式输出乘积矩阵AB,否则输出Error: Ca != Rb,其中Ca是A的列数,Rb是B的行数。
输入样例1:
2 3
1 2 3
4 5 6
3 4
7 8 9 0
-1 -2 -3 -4
5 6 7 8输出样例1:
2 4
20 22 24 16
53 58 63 28输入样例2:
3 2
38 26
43 -5
0 17
3 2
-11 57
99 68
81 72
输出样例2:
Error 2 != 3矩阵A naXnb
矩阵B maXmb
矩阵C naXnb*maXmb = naXmb(当且仅当nb==ma)
三层循环,第一层C的na,第二层C的mb,第三层ma或者nb
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 int a[105][105],b[105][105],c[105][105]; 5 int main() 6 { 7 int na,ma,nb,mb; 8 scanf("%d%d",&na,&nb); 9 for(int i=1;i<=na;i++) 10 for(int j=1;j<=nb;j++) 11 scanf("%d",&a[i][j]); 12 scanf("%d%d",&ma,&mb); 13 for(int i=1;i<=ma;i++) 14 for(int j=1;j<=mb;j++) 15 scanf("%d",&b[i][j]); 16 if(nb!=ma)printf("Error: %d != %d\n",nb,ma); 17 else 18 { 19 for(int i=1;i<=na;i++) 20 for(int j=1;j<=mb;j++) 21 for(int k=1;k<=ma;k++) 22 c[i][j]+=a[i][k]*b[k][j]; 23 printf("%d %d\n",na,mb); 24 for(int i=1;i<=na;i++) 25 for(int j=1;j<=mb;j++) 26 printf("%d%c",c[i][j],j==mb?'\n':' '); 27 } 28 return 0; 29 }
微博上有个“点赞”功能,你可以为你喜欢的博文点个赞表示支持。每篇博文都有一些刻画其特性的标签,而你点赞的博文的类型,也间接刻画了你的特性。然而有这么一种人,他们会通过给自己看到的一切内容点赞来狂刷存在感,这种人就被称为“点赞狂魔”。他们点赞的标签非常分散,无法体现出明显的特性。本题就要求你写个程序,通过统计每个人点赞的不同标签的数量,找出前3名点赞狂魔。
输入格式:
输入在第一行给出一个正整数N(≤100),是待统计的用户数。随后N行,每行列出一位用户的点赞标签。格式为“Name K F1⋯FK”,其中Name是不超过8个英文小写字母的非空用户名,1≤K≤1000,Fi(i=1,⋯,K)是特性标签的编号,我们将所有特性标签从 1 到 107 编号。数字间以空格分隔。
输出格式:
统计每个人点赞的不同标签的数量,找出数量最大的前3名,在一行中顺序输出他们的用户名,其间以1个空格分隔,且行末不得有多余空格。如果有并列,则输出标签出现次数平均值最小的那个,题目保证这样的用户没有并列。若不足3人,则用-补齐缺失,例如mike jenny -就表示只有2人。
输入样例:
5
bob 11 101 102 103 104 105 106 107 108 108 107 107
peter 8 1 2 3 4 3 2 5 1
chris 12 1 2 3 4 5 6 7 8 9 1 2 3
john 10 8 7 6 5 4 3 2 1 7 5
jack 9 6 7 8 9 10 11 12 13 14
输出样例:
jack chris john结构体排序一下就行,判重用set
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 struct p 5 { 6 char name[15]; 7 int cnt; 8 double ave; 9 }d[105]; 10 bool cmp(p a,p b) 11 { 12 if(a.cnt!=b.cnt)return a.cnt>b.cnt; 13 return a.ave<b.ave; 14 } 15 int main() 16 { 17 int n,k; 18 set<int>s; 19 scanf("%d",&n); 20 for(int i=0;i<n;i++) 21 { 22 scanf("%s%d",d[i].name,&k); 23 for(int j=0;j<k;j++) 24 { 25 int v; 26 scanf("%d",&v); 27 s.insert(v); 28 } 29 d[i].cnt=s.size(); 30 d[i].ave=k*1./(int)s.size(); 31 s.clear(); 32 } 33 sort(d,d+n,cmp); 34 for(int i=0;i<3;i++) 35 { 36 if(i!=0)printf(" "); 37 if(i<n)printf("%s",d[i].name); 38 else printf("-"); 39 } 40 return 0; 41 }
给定一个单链表 L1→L2→⋯→Ln−1→Ln,请编写程序将链表重新排列为 Ln→L1→Ln−1→L2→⋯。例如:给定L为1→2→3→4→5→6,则输出应该为6→1→5→2→4→3。
输入格式:
每个输入包含1个测试用例。每个测试用例第1行给出第1个结点的地址和结点总个数,即正整数N (≤105)。结点的地址是5位非负整数,NULL地址用−1表示。
接下来有N行,每行格式为:
Address Data Next
其中Address是结点地址;Data是该结点保存的数据,为不超过105的正整数;Next是下一结点的地址。题目保证给出的链表上至少有两个结点。
输出格式:
对每个测试用例,顺序输出重排后的结果链表,其上每个结点占一行,格式与输入相同。
输入样例:
00100 6
00000 4 99999
00100 1 12309
68237 6 -1
33218 3 00000
99999 5 68237
12309 2 33218
输出样例:
68237 6 00100
00100 1 99999
99999 5 12309
12309 2 00000
00000 4 33218
33218 3 -1先建一个链表,注意会有多余节点(无用),输出的时候一左一右,两行两行输出,最后判断一下奇偶,奇数就输出最后一行,偶数输出最后两行
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 const int maxn=1e5+5; 5 struct Node 6 { 7 int u,v,w; 8 }a[maxn]; 9 vector<Node>G; 10 int main() 11 { 12 int s,k,u,v,w; 13 scanf("%d%d",&s,&k); 14 for(int i=0;i<k;i++) 15 { 16 scanf("%d%d%d",&u,&w,&v); 17 a[u]={u,v,w}; 18 } 19 int cnt=0; 20 while(1) 21 { 22 G.push_back(a[s]); 23 s=a[s].v; 24 cnt++; 25 if(s==-1)break; 26 } 27 int L=0,R=cnt-1; 28 while(L<=R) 29 { 30 printf("%05d %d %05d\n",G[R].u,G[R].w,G[L].u); 31 printf("%05d %d ",G[L].u,G[L].w); 32 L++,R--; 33 if(L==R) 34 { 35 //剩一个 36 printf("%05d\n%05d %d -1\n",G[R].u,G[R].u,G[R].w); 37 break; 38 } 39 else 40 { 41 if(L<cnt/2)//不是最后俩个 42 printf("%05d\n",G[R].u); 43 else//最后俩个 44 { 45 printf("-1\n"); 46 break; 47 } 48 } 49 } 50 return 0; 51 }
图着色问题是一个著名的NP完全问题。给定无向图G=(V,E),问可否用K种颜色为V中的每一个顶点分配一种颜色,使得不会有两个相邻顶点具有同一种颜色?
但本题并不是要你解决这个着色问题,而是对给定的一种颜色分配,请你判断这是否是图着色问题的一个解。
输入格式:
输入在第一行给出3个整数V(0<V≤500)、E(≥0)和K(0<K≤V),分别是无向图的顶点数、边数、以及颜色数。顶点和颜色都从1到V编号。随后E行,每行给出一条边的两个端点的编号。在图的信息给出之后,给出了一个正整数N(≤20),是待检查的颜色分配方案的个数。随后N行,每行顺次给出V个顶点的颜色(第i个数字表示第i个顶点的颜色),数字间以空格分隔。题目保证给定的无向图是合法的(即不存在自回路和重边)。
输出格式:
对每种颜色分配方案,如果是图着色问题的一个解则输出Yes,否则输出No,每句占一行。
输入样例:
6 8 3
2 1
1 3
4 6
2 5
2 4
5 4
5 6
3 6
4
1 2 3 3 1 2
4 5 6 6 4 5
1 2 3 4 5 6
2 3 4 2 3 4
输出样例:
Yes
Yes
No
No点数很少,可以直接暴力找连边是否颜色相同,N个询问复杂度(N*V^2)不高可以通过,这里用set判颜色数量,颜色数量刚好为K才可以
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 bool G[505][505]; 5 int color[505]; 6 int main() 7 { 8 int v,e,k,uu,vv; 9 scanf("%d%d%d",&v,&e,&k); 10 for(int i=0;i<e;i++) 11 { 12 scanf("%d%d",&uu,&vv); 13 G[uu][vv]=G[vv][uu]=true; 14 } 15 int n; 16 scanf("%d",&n); 17 while(n--) 18 { 19 int cnt=0; 20 map<int,int>ma; 21 for(int i=1;i<=v;i++) 22 { 23 scanf("%d",&color[i]); 24 if(ma[color[i]]==0) 25 { 26 ma[color[i]]=1; 27 cnt++; 28 } 29 } 30 int flag=1; 31 if(cnt!=k)flag=0; 32 else 33 { 34 for(int i=1;i<=v;i++) 35 { 36 for(int j=1;j<=v;j++) 37 { 38 if(G[i][j]&&i!=j&&color[i]==color[j]) 39 { 40 flag=0; 41 break; 42 } 43 } 44 if(flag==0)break; 45 } 46 } 47 if(flag)printf("Yes\n"); 48 else printf("No\n"); 49 } 50 return 0; 51 }
在一个社区里,每个人都有自己的小圈子,还可能同时属于很多不同的朋友圈。我们认为朋友的朋友都算在一个部落里,于是要请你统计一下,在一个给定社区中,到底有多少个互不相交的部落?并且检查任意两个人是否属于同一个部落。
输入格式:
输入在第一行给出一个正整数N(≤104),是已知小圈子的个数。随后N行,每行按下列格式给出一个小圈子里的人:
K P[1] P[2] ⋯ P[K]
其中K是小圈子里的人数,P[i](i=1,⋯,K)是小圈子里每个人的编号。这里所有人的编号从1开始连续编号,最大编号不会超过104。
之后一行给出一个非负整数Q(≤104),是查询次数。随后Q行,每行给出一对被查询的人的编号。
输出格式:
首先在一行中输出这个社区的总人数、以及互不相交的部落的个数。随后对每一次查询,如果他们属于同一个部落,则在一行中输出Y,否则输出N。
输入样例:
4
3 10 1 2
2 3 4
4 1 5 7 8
3 9 6 4
2
10 5
3 7
输出样例:
10 2
Y
N并查集模板题
find(x) 找x的父亲,并且压缩路径(再以后查找的时候会变快),比如1-3-4会变成1-4
join 连通a和b
初始化f[i]=i
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 const int maxn=1e4+5; 5 int f[maxn]; 6 int find(int x) 7 { 8 return f[x]==x?x:f[x]=find(f[x]); 9 } 10 void join(int a,int b) 11 { 12 f[find(a)]=find(b); 13 } 14 int main() 15 { 16 int n,u,v,q,ans=0,maxx=0; 17 scanf("%d",&n); 18 for(int i=1;i<=10000;i++)f[i]=i; 19 for(int i=1;i<=n;i++) 20 { 21 int k,u,v; 22 scanf("%d",&k); 23 if(k>=1)scanf("%d",&u),maxx=max(maxx,u); 24 for(int j=2;j<=k;j++) 25 { 26 scanf("%d",&v),maxx=max(maxx,v); 27 join(u,v); 28 } 29 } 30 for(int i=1;i<=maxx;i++) 31 if(f[i]==i) 32 ans++; 33 printf("%d %d\n",maxx,ans); 34 scanf("%d",&q); 35 for(int i=0;i<q;i++) 36 { 37 int u,v; 38 scanf("%d%d",&u,&v); 39 if(find(u)==find(v))printf("Y\n"); 40 else printf("N\n"); 41 } 42 return 0; 43 }
二叉搜索树或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;它的左、右子树也分别为二叉搜索树。(摘自百度百科)
给定一系列互不相等的整数,将它们顺次插入一棵初始为空的二叉搜索树,然后对结果树的结构进行描述。你需要能判断给定的描述是否正确。例如将{ 2 4 1 3 0 }插入后,得到一棵二叉搜索树,则陈述句如“2是树的根”、“1和4是兄弟结点”、“3和0在同一层上”(指自顶向下的深度相同)、“2是4的双亲结点”、“3是4的左孩子”都是正确的;而“4是2的左孩子”、“1和3是兄弟结点”都是不正确的。
输入格式:
输入在第一行给出一个正整数N(≤100),随后一行给出N个互不相同的整数,数字间以空格分隔,要求将之顺次插入一棵初始为空的二叉搜索树。之后给出一个正整数M(≤100),随后M行,每行给出一句待判断的陈述句。陈述句有以下6种:
A is the root,即"A是树的根";A and B are siblings,即"A和B是兄弟结点";A is the parent of B,即"A是B的双亲结点";A is the left child of B,即"A是B的左孩子";A is the right child of B,即"A是B的右孩子";A and B are on the same level,即"A和B在同一层上"。
题目保证所有给定的整数都在整型范围内。
输出格式:
对每句陈述,如果正确则输出Yes,否则输出No,每句占一行。
输入样例:
5
2 4 1 3 0
8
2 is the root
1 and 4 are siblings
3 and 0 are on the same level
2 is the parent of 4
3 is the left child of 4
1 is the right child of 2
4 and 0 are on the same level
100 is the right child of 3
输出样例:
Yes
Yes
Yes
Yes
Yes
No
No
No时隔1年的时间再来做这个题,当时170行搜索树上搜搜搜,现在120行DFS一便记录所有信息,有所进步(雾)
建搜索树还是老样子,链表
建完后,DFS(root,fa)root为根节点,fa为双亲节点
每个数字用map<int,int>ma,cnt=1进行哈希存储,map在int下若不存在值为0
每个节点信息存fa双亲节点,sonl左儿子,sonr右儿子,level层数
询问的时候,前提条件是询问的节点都存在即map[A]>0||map[B]>0
1.根,root->data
2.AB兄弟,父母一样
3.A是B的双亲,B的双亲为A
4.A是B左儿子,B的左儿子为A
5.A是B右儿子,B的右儿子为A
6.AB同一层,层数相同
1 #include<bits/stdc++.h> 2 using namespace std; 3 struct Node 4 { 5 int data; 6 Node *Left,*Right; 7 Node():data(-1),Left(NULL),Right(NULL){} 8 }; 9 Node *addnode(){return new Node();} 10 Node *root; 11 int cnt=0; 12 map<int,int>ma; 13 void Create(Node *u,int a) 14 { 15 if(u->data==-1) 16 { 17 u->data=a; 18 return ; 19 } 20 else 21 { 22 if(a>u->data) 23 { 24 if(u->Right==NULL) 25 u->Right=addnode(); 26 Create(u->Right,a); 27 } 28 else 29 { 30 if(u->Left==NULL) 31 u->Left=addnode(); 32 Create(u->Left,a); 33 } 34 } 35 } 36 struct message 37 { 38 int fa; 39 int sonl,sonr; 40 int level; 41 }d[105]; 42 void dfs(Node *u,Node *fa,int level) 43 { 44 if(u==NULL)return; 45 int val=u->data; 46 int pos=ma[val]; 47 if(fa!=NULL) 48 d[pos].fa=fa->data; 49 if(u->Left!=NULL) 50 d[pos].sonl=u->Left->data; 51 if(u->Right!=NULL) 52 d[pos].sonr=u->Right->data; 53 d[pos].level=level; 54 dfs(u->Left,u,level+1); 55 dfs(u->Right,u,level+1); 56 } 57 int main() 58 { 59 root=addnode(); 60 int n,m; 61 scanf("%d",&n); 62 for(int i=1,u;i<=n;i++) 63 { 64 scanf("%d",&u); 65 if(ma[u]==0)ma[u]=++cnt; 66 Create(root,u); 67 } 68 for(int i=1;i<105;i++) 69 d[i].fa=-1,d[i].sonl=-1,d[i].sonr=-1,d[i].level=-1; 70 dfs(root,NULL,1); 71 scanf("%d",&m); 72 string s; 73 int A,B; 74 while(m--) 75 { 76 cin>>A>>s; 77 int posA=ma[A]; 78 int posB; 79 int flag=0; 80 if(s=="is") 81 { 82 cin>>s>>s; 83 if(s=="root")//1 84 { 85 if(root->data==A)flag=1; 86 } 87 else if(s=="parent")//3 88 { 89 cin>>s>>B; 90 posB=ma[B]; 91 if(d[posB].fa==A)flag=1; 92 } 93 else if(s=="left")//4 94 { 95 cin>>s>>s>>B; 96 posB=ma[B]; 97 if(d[posB].sonl==A)flag=1; 98 } 99 else if(s=="right")//5 100 { 101 cin>>s>>s>>B; 102 posB=ma[B]; 103 if(d[posB].sonr==A)flag=1; 104 } 105 } 106 else if(s=="and") 107 { 108 cin>>B>>s>>s; 109 posB=ma[B]; 110 if(s=="siblings")//2 111 { 112 if(d[posA].fa==d[posB].fa)flag=1; 113 } 114 else if(s=="on")//6 115 { 116 cin>>s>>s>>s; 117 if(d[posA].level==d[posB].level)flag=1; 118 } 119 } 120 if(posA==0||posB==0)flag=0; 121 printf("%s\n",flag?"Yes":"No"); 122 } 123 return 0; 124 }
森森开了一家快递公司,叫森森快递。因为公司刚刚开张,所以业务路线很简单,可以认为是一条直线上的N个城市,这些城市从左到右依次从0到(N−1)编号。由于道路限制,第i号城市(i=0,⋯,N−2)与第(i+1)号城市中间往返的运输货物重量在同一时刻不能超过Ci公斤。
公司开张后很快接到了Q张订单,其中j张订单描述了某些指定的货物要从Sj号城市运输到Tj号城市。这里我们简单地假设所有货物都有无限货源,森森会不定时地挑选其中一部分货物进行运输。安全起见,这些货物不会在中途卸货。
为了让公司整体效益更佳,森森想知道如何安排订单的运输,能使得运输的货物重量最大且符合道路的限制?要注意的是,发货时间有可能是任何时刻,所以我们安排订单的时候,必须保证共用同一条道路的所有货车的总重量不超载。例如我们安排1号城市到4号城市以及2号城市到4号城市两张订单的运输,则这两张订单的运输同时受2-3以及3-4两条道路的限制,因为两张订单的货物可能会同时在这些道路上运输。
输入格式:
输入在第一行给出两个正整数N和Q(2≤N≤105, 1≤Q≤105),表示总共的城市数以及订单数量。
第二行给出(N−1)个数,顺次表示相邻两城市间的道路允许的最大运货重量Ci(i=0,⋯,N−2)。题目保证每个Ci是不超过231的非负整数。
接下来Q行,每行给出一张订单的起始及终止运输城市编号。题目保证所有编号合法,并且不存在起点和终点重合的情况。
输出格式:
在一行中输出可运输货物的最大重量。
输入样例:
10 6
0 7 8 5 2 3 1 9 10
0 9
1 8
2 7
6 3
4 5
4 2
输出样例:
7样例提示:我们选择执行最后两张订单,即把5公斤货从城市4运到城市2,并且把2公斤货从城市4运到城市5,就可以得到最大运输量7公斤。
贪心+线段树区间更新
贪心处理区间A[l,r]和B[L,R],这里已经按右端点从小到大排序了:
A和B区间不相交 不影响 假设取A
A完全包含于B A在里面,先取B的话,会对后面的C产生影响,所以得取A
A和B相交 假设先取B,那么会影响到A的取值,取A的影响小
A的r和B的R相同怎么取,情况1:B包含于A,取A取B一样。情况2:AB不交,取A取B一样
所以按照右端点从小到大排就行
然后就是愉快的线段树区间lazy标记,比较模板,注意得开LL
1 #include<bits/stdc++.h> 2 using namespace std; 3 4 #define LL long long 5 const int maxn=1e5+5; 6 LL minn[maxn<<2],lazy[maxn<<2]; 7 int n,q; 8 void build(int l,int r,int rt) 9 { 10 if(l==r) 11 { 12 if(l>1)scanf("%lld",&minn[rt]); 13 else minn[r]=(1LL<<31); 14 return; 15 } 16 int mid=(l+r)>>1; 17 build(l,mid,rt<<1); 18 build(mid+1,r,rt<<1|1); 19 minn[rt]=min(minn[rt<<1],minn[rt<<1|1]); 20 } 21 void pushdown(int rt) 22 { 23 if(lazy[rt]==0)return; 24 lazy[rt<<1]+=lazy[rt]; 25 lazy[rt<<1|1]+=lazy[rt]; 26 minn[rt<<1]+=lazy[rt]; 27 minn[rt<<1|1]+=lazy[rt]; 28 lazy[rt]=0; 29 } 30 LL query(int L,int R,int l,int r,int rt) 31 { 32 if(L<=l&&r<=R)return minn[rt]; 33 int mid=(l+r)>>1; 34 LL ans=(1LL<<31); 35 pushdown(rt); 36 if(L<=mid)ans=min(ans,query(L,R,l,mid,rt<<1)); 37 if(R>mid)ans=min(ans,query(L,R,mid+1,r,rt<<1|1)); 38 minn[rt]=min(minn[rt<<1],minn[rt<<1|1]); 39 return ans; 40 } 41 void update(int L,int R,LL C,int l,int r,int rt) 42 { 43 if(L<=l&&r<=R) 44 { 45 minn[rt]+=C; 46 lazy[rt]+=C; 47 return; 48 } 49 int mid=(l+r)>>1; 50 pushdown(rt); 51 if(L<=mid)update(L,R,C,l,mid,rt<<1); 52 if(R>mid)update(L,R,C,mid+1,r,rt<<1|1); 53 minn[rt]=min(minn[rt<<1],minn[rt<<1|1]); 54 } 55 struct p 56 { 57 int s,e; 58 }d[maxn]; 59 bool cmp(p a,p b) 60 { 61 return a.s<b.s||(a.s==b.s&&a.e<b.e); 62 } 63 int main() 64 { 65 memset(minn,0x3f,sizeof minn); 66 scanf("%d%d",&n,&q); 67 build(1,n,1); 68 for(int i=0;i<q;i++) 69 { 70 scanf("%d%d",&d[i].s,&d[i].e),d[i].s++,d[i].e++; 71 if(d[i].s>d[i].e)swap(d[i].s,d[i].e); 72 } 73 sort(d,d+q,cmp); 74 LL ans=0; 75 for(int i=0;i<q;i++) 76 { 77 int L=d[i].s,R=d[i].e; 78 if(L==R)continue; 79 LL minn=query(L+1,R,1,n,1); 80 update(L+1,R,-minn,1,n,1); 81 ans+=minn; 82 } 83 printf("%lld\n",ans); 84 return 0; 85 }
森森最近想让自己的朋友圈熠熠生辉,所以他决定自己写个美化照片的软件,并起名为森森美图。众所周知,在合照中美化自己的面部而不美化合照者的面部是让自己占据朋友圈高点的绝好方法,因此森森美图里当然得有这个功能。 这个功能的第一步是将自己的面部选中。森森首先计算出了一个图像中所有像素点与周围点的相似程度的分数,分数越低表示某个像素点越“像”一个轮廓边缘上的点。 森森认为,任意连续像素点的得分之和越低,表示它们组成的曲线和轮廓边缘的重合程度越高。为了选择出一个完整的面部,森森决定让用户选择面部上的两个像素点A和B,则连接这两个点的直线就将图像分为两部分,然后在这两部分中分别寻找一条从A到B且与轮廓重合程度最高的曲线,就可以拼出用户的面部了。 然而森森计算出来得分矩阵后,突然发现自己不知道怎么找到这两条曲线了,你能帮森森当上朋友圈的小王子吗?
为了解题方便,我们做出以下补充说明:
- 图像的左上角是坐标原点(0,0),我们假设所有像素按矩阵格式排列,其坐标均为非负整数(即横轴向右为正,纵轴向下为正)。
- 忽略正好位于连接A和B的直线(注意不是线段)上的像素点,即不认为这部分像素点在任何一个划分部分上,因此曲线也不能经过这部分像素点。
- 曲线是八连通的(即任一像素点可与其周围的8个像素连通),但为了计算准确,某像素连接对角相邻的斜向像素时,得分额外增加两个像素分数和的√2倍减一。例如样例中,经过坐标为(3,1)和(4,2)的两个像素点的曲线,其得分应该是这两个像素点的分数和(2+2),再加上额外的(2+2)乘以(√2−1),即约为5.66。
输入格式:
输入在第一行给出两个正整数N和M(5≤N,M≤100),表示像素得分矩阵的行数和列数。
接下来N行,每行M个不大于1000的非负整数,即为像素点的分值。
最后一行给出用户选择的起始和结束像素点的坐标(Xstart,Ystart)和(Xend,Yend)。4个整数用空格分隔。
输出格式:
在一行中输出划分图片后找到的轮廓曲线的得分和,保留小数点后两位。注意起点和终点的得分不要重复计算。
输入样例:
6 6
9 0 1 9 9 9
9 9 1 2 2 9
9 9 2 0 2 9
9 9 1 1 2 9
9 9 3 3 1 1
9 9 9 9 9 9
2 1 5 4
输出样例:
27.04首先怎么判断在直线两侧
考虑叉积,如果叉积(A,B,C)>0,说明AB在AC逆时针方向,<0顺时针,=0重合
直线中的两点A和B,叉积(A,B,C)>0说明在直线左边
直线右边就是叉积(B,A,C)>0
那么问题就变成最短路
注意如果斜着走是额外加两个值*(sqrt(2)-1)
然后从A跑到B(左侧),再从B跑到A(由于叉积判左侧,倒着来就是在右侧),最后减去多算的A点和B点的值
#include<bits/stdc++.h> using namespace std; double sc[110][110]; int dx[]={1,-1,0,0,1,-1,1,-1}; int dy[]={0,0,1,-1,1,-1,-1,1}; struct p { int x,y; }l,r; int cross(p a,p b,p c) { return (b.x-a.x)*(c.y-a.y)-(b.y-a.y)*(c.x-a.x); } double ans[110][110]; int n,m; double bfs(p s,p e) { for(int i=0;i<=105;i++) for(int j=0;j<=105;j++) ans[i][j]=1e18; p u,t,a=s,b=e; queue<p>q; while(!q.empty())q.pop(); q.push(s); ans[s.x][s.y]=sc[s.x][s.y]; while(!q.empty()) { u=q.front();q.pop(); for(int i=0;i<8;i++) { t.x=u.x+dx[i]; t.y=u.y+dy[i]; if((cross(a,b,t)>0||(t.x==e.x&&t.y==e.y))&&t.x>=0&&t.x<n&&t.y>=0&&t.y<m) { double w=sc[t.x][t.y]; if(i>3)w+=(sc[t.x][t.y]+sc[u.x][u.y])*(sqrt(2.)-1); if(ans[t.x][t.y]>ans[u.x][u.y]+w) { ans[t.x][t.y]=ans[u.x][u.y]+w; q.push(t); } } } } return ans[e.x][e.y]; } int main() { scanf("%d%d",&n,&m); for(int i=0;i<n;i++) for(int j=0;j<m;j++) scanf("%lf",&sc[i][j]); scanf("%d%d%d%d",&l.y,&l.x,&r.y,&r.x); printf("%.2f\n",bfs(l,r)+bfs(r,l)-sc[l.x][l.y]-sc[r.x][r.y]); return 0; }
2 196
0 0
1 60