Ref: https://www.cnblogs.com/SeekHit/p/6245283.html
因为有个需求,需要处理文件夹内所有txt文件,将txt里面的数据筛选,重新存储。
一.分析数据格式
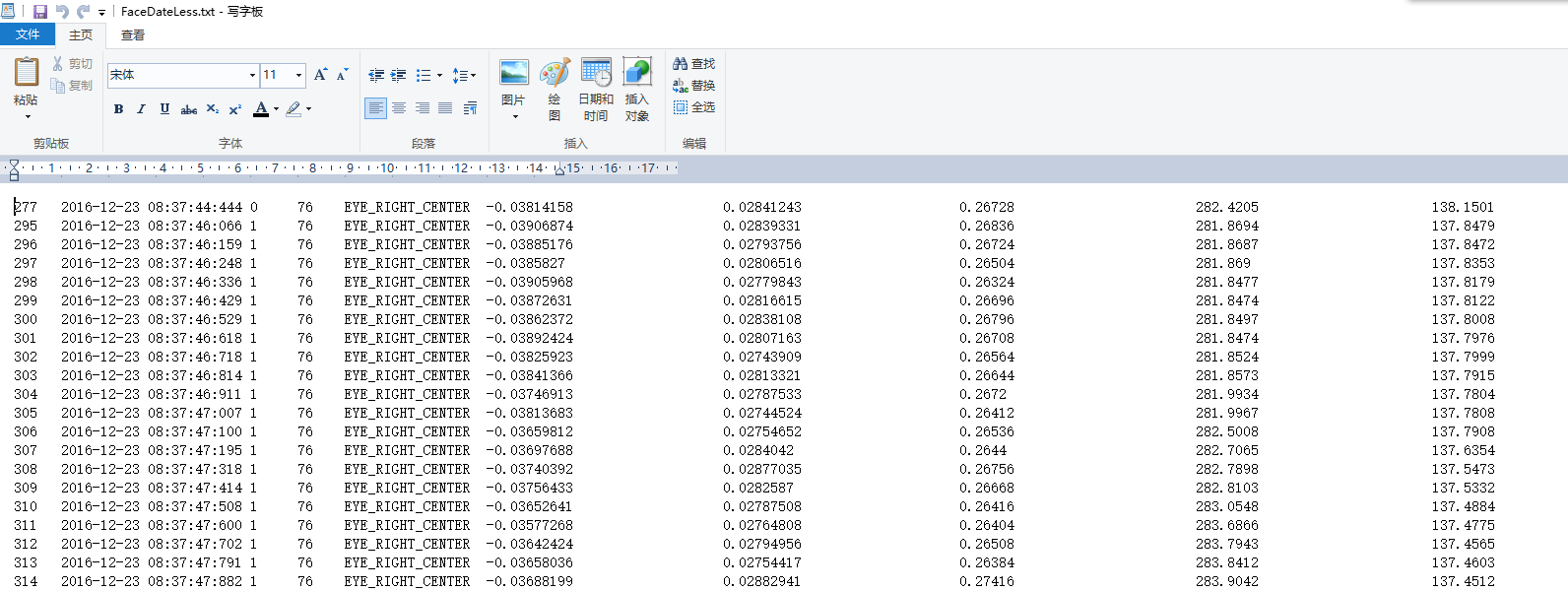
需要处理的数据是txt格式存储的。下图中一行中的数据依次是,帧、时间、编号、特征点编号、特征点名字、特征点世界坐标x,y,z,特征点屏幕坐标x,y,一共32个特征点,最后6个数据是头部姿态的位置x,y,z和偏转角度x,y,z。一行共计233个字段。
需要完成的工作是,把特征点的编号,世界坐标,屏幕坐标分别写入2个csv文件中。
因为后面需要用到svm分类器,在数据挖掘软件weka中进行分类。
二.Python文件读取操作
需要做的是Python中txt文件读取操作,然后利用split()函数将每行的字符串分割成元组,然后利用下标讲我们需要保留的数据写入到新的txt中。
常见的Python文件读取txt的方法有3种:
方法一:

1 f = open("foo.txt") # 返回一个文件对象 2 line = f.readline() # 调用文件的 readline()方法 3 while line: 4 print line, # 后面跟 ',' 将忽略换行符 5 # print(line, end = '') # 在 Python 3中使用 6 line = f.readline() 7 8 f.close()
方法二:
1 for line in open("foo.txt"): 2 print line
方法三:
1 f = open("c:\\1.txt","r") 2 lines = f.readlines()#读取全部内容 3 for line in lines 4 print line
因为需要处理的数据最后一行不完整,所以,我们只处理到倒数第二行。用readlines()读取到的是一个List,每行是一个元素。所以可以用len()方法统计有多少行,处理的时候处理到倒数第二行停止。
完成我们的需求:
1 def readFile(filepath): 2 f1 = open(filepath, "r") #打开传进来的路径 3 f_world = open("WorldData", "w") 4 f_image = open("ImageData", "w") 5 lines = f1.readlines() #读取所有行 6 lines_count = len(lines) #统计行数 7 for n in range(0, lines_count-1): 8 line = lines[n] 9 line_object = line.split('\t') 10 11 i = 5 12 13 worldposition = "" 14 imageposition = "" 15 while i <= 223: #取值 16 id = line_object[i - 2] 17 world_x = line_object[i] 18 world_y = line_object[i + 1] 19 world_z = line_object[i + 2] 20 worldposition = id + " " + world_x + world_y + world_z 21 # print worldposition 22 f_world.write(worldposition) 23 24 image_x = line_object[i + 3] 25 image_y = line_object[i + 4] 26 imageposition = id + " " + image_x + image_y 27 f_image.write(imageposition) 28 29 i += 7 30 i -= 1 31 headposition = line_object[i - 1] + line_object[i] + line_object[i + 1] 32 headrotate = line_object[i + 2] + line_object[i + 3] + line_object[i + 4] 33 head = headposition + headrotate + "\n" 34 35 print head 36 f_world.write(head) # 写入文件操作 37 f_image.write(head) 38 f1.close() 39 f_image.close() 40 f_world.close()
三.递归遍历文件夹下多个txt文件
因为需要处理的数据不止一个,用自动化的思想来解决这个问题,需要依次遍历文件夹下多个txt文件。
代码如下:
1 def eachFile(filepath): 2 pathDir = os.listdir(filepath) #获取当前路径下的文件名,返回List 3 for s in pathDir: 4 newDir=os.path.join(filepath,s) #将文件命加入到当前文件路径后面 5 if os.path.isfile(newDir) : #如果是文件 6 if os.path.splitext(newDir)[1]==".txt": #判断是否是txt 7 readFile(newDir) #读文件 8 pass 9 else: 10 eachFile(newDir) #如果不是文件,递归这个文件夹的路径
四.对处理得到的文件进行命名
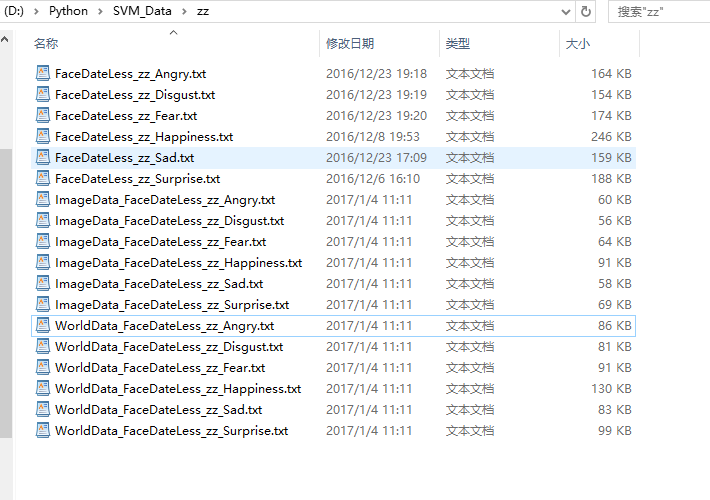
需求是,处理完一个txt,如abc.txt,然后生成的文件,命名为World_abc.txt和Image_abc.txt,并将生成的文件保存在和源文件同样的目录下面。
思路是,对路径就行分割,使用
os.path.split(filepath)
返回的是一个2个元素的元祖,第一个元素是文件夹路径,第二个是文件名。
1 nowDir = os.path.split(filepath)[0] #获取路径中的父文件夹路径 2 fileName = os.path.split(filepath)[1] #获取路径中文件名 3 WorldDataDir = os.path.join(nowDir, "WorldData_" + fileName) #对新生成的文件进行命名的过程 4 ImageDataDir = os.path.join(nowDir, "ImageData_" + fileName) 5 6 f_world = open(WorldDataDir, "w") 7 f_image = open(ImageDataDir, "w")
处理完之后就哗哗哗生成一大堆了。
完整代码:
#读文件
import os
#处理文件数量
count=0
def readFile(filepath):
f1 = open(filepath, "r")
nowDir = os.path.split(filepath)[0] #获取路径中的父文件夹路径
fileName = os.path.split(filepath)[1] #获取路径中文件名
WorldDataDir = os.path.join(nowDir, "WorldData_" + fileName) #对新生成的文件进行命名的过程
ImageDataDir = os.path.join(nowDir, "ImageData_" + fileName)
f_world = open(WorldDataDir, "w")
f_image = open(ImageDataDir, "w")
lines = f1.readlines()
lines_count = len(lines)
for n in range(0, lines_count-1):
line = lines[n]
line_object = line.split('\t')
i = 5
worldposition = ""
imageposition = ""
while i <= 223:
id = line_object[i - 2]
world_x = line_object[i]
world_y = line_object[i + 1]
world_z = line_object[i + 2]
worldposition = id + " " + world_x + world_y + world_z
# print worldposition
f_world.write(worldposition)
image_x = line_object[i + 3]
image_y = line_object[i + 4]
imageposition = id + " " + image_x + image_y
f_image.write(imageposition)
i += 7
i -= 1
headposition = line_object[i - 1] + line_object[i] + line_object[i + 1]
headrotate = line_object[i + 2] + line_object[i + 3] + line_object[i + 4]
head = headposition + headrotate + "\n"
print head
f_world.write(head)
f_image.write(head)
f_world.write("world")
f_image.write("image")
f1.close()
f_image.close()
f_world.close()
global count
count+=1
def eachFile(filepath):
pathDir = os.listdir(filepath) #获取当前路径下的文件名,返回List
for s in pathDir:
newDir=os.path.join(filepath,s) #将文件命加入到当前文件路径后面
if os.path.isfile(newDir) : #如果是文件
if os.path.splitext(newDir)[1]==".txt": #判断是否是txt
readFile(newDir) #读文件
pass
else:
eachFile(newDir) #如果不是文件,递归这个文件夹的路径
eachFile("D:\Python\SVM_Data")
print "共处理"+bytes(count)+"个txt"
补充:
代码中添加了一个globle count变量,记录处理的txt数目,因为python语言是弱类型的语言,在函数中,想要改变全局遍历的值。
1 count=0 2 def xxx(): 3 global count #声明这里的count是全局变量count 4 count+=1
最后输出count数量的时候
1 print "共处理"+count+"个txt" #报错,字符类型和值类型不能这样输出 2 3 print "共处理"+bytes(count)+"个txt" #使用bytes方法,将值类型转换成字符类型
python OS模块的官方文档:
10.1. os.path — Common pathname manipulations — Python 2.7.13 documentation
https://docs.python.org/2.7/library/os.path.html