版权声明:转载请注明出处 https://blog.csdn.net/nanhuaibeian/article/details/86510934
1. 查看网页源代码定位要爬取的信息(谷歌浏览器)
-
目标网页:https://blog.csdn.net/nanhuaibeian/article/details/85521071
-
审查网页元素,确定爬取内容
目标想要爬取这一个列表信息

-
确定网页在div标签下,class属性为‘table-box’

-
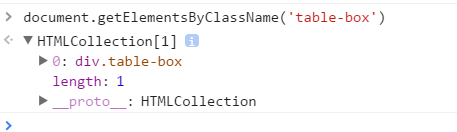
Console控制台下得到这个table
2.爬取下网页并保存
- 代码实现
import requests
url = 'https://blog.csdn.net/nanhuaibeian/article/details/85521071'
response = requests.get(url)
response.encoding('utf-8')
with open('real_case.html','w') as f:
f.write(response.text)
- 由于已经确定获取目标内容的标签为div(class=‘table-box’),往下进行,会发现,爬取下来的网页内容不含有这一标签,审查元素发现这一标签是通过js设置的

修改方法从谷歌浏览器将源码下载保存到real_case.html中。
3. 获取目标内容
import requests
import re
from lxml import etree
import html
with open('real_case.html','r',encoding='utf-8') as f:
c = f.read()
#将换行符全部替换掉
s = re.sub(r'\n',' ',c)
tree = etree.HTML(c)
table_element = tree.xpath("//div[@class='table-box'][1]/table/tbody/tr")
# 正则表达式替换掉'<>'
pattern1_attrib = re.compile(r"<.*?>")
#读取内容
for row in table_element:
try:
td1 = row.xpath('td')[0]
s1 = etree.tostring(td1).decode('utf-8')
#将'<>'用空替换掉
s1 = pattern1_attrib.sub('',s1)
#按照HTML5的定义进行转码
s1 = html.unescape(s1)
td2 = row.xpath('td')[1]
s2 = etree.tostring(td2).decode('utf-8')
s2 = pattern1_attrib.sub('', s2)
s2 = html.unescape(s2)
print(s1,':',s2)
except Exception as err:
print('error:',err)
pass