1.先建立工作路径,并将hbase解压到工作路径中

2.修改配置文件:conf/hbase-env.sh
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HBASE_CLASSPATH=/usr/hadoop/hadoop-2.7.3/etc/Hadoop


解释:一个分布式运行的 Hbase 依赖一个 zookeeper 集群。所有的节点和客户端都必须能够访问 zookeeper。默认的情况下 Hbase 会管理一个 zookeep 集群,即 Hbase 默认自带一个 zookeep 集群。这个集群会随着 Hbase 的启动而启动。而在实际的商业项目中通常自己管理一个zookeeper集群更便于优化配置提高集群工作效率,但需要配置Hbase。需要修conf/hbaseenv.sh里面的HBASE_MANAGES_ZK 来切换。这个值默认是 true 的,作用是让 Hbase 启动的时候同时也启动 zookeeper.在本实验中,我们采用独立运行 zookeeper 集群的方式,故将其属性值改为 false。
3.配置 conf/hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:6000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/zookeeper/zookeeper-3.4.10</value>
</property>解释:要想运行完全分布式模式,加一个属性 hbase.cluster.distributed设置为 true 然后把 hbase.rootdir 设置为 HDFS 的NameNode 的位置hbase.rootdir:这个目录是 region server 的共享目录,用来持久化 Hbase。URL 需要是’完全正确’的,还包含文件系统的 schemehbase.cluster.distributed :Hbase 的运行模式。false 是单机模式,true是分布式模式。若为 false,Hbase 和 Zookeeper 会运行在同一个 JVM 里面。在hbase-site.xml 配置 zookeeper:当Hbase 管理 zookeeper 的时候,你可以通过修改zoo.cfg来配置zookeeper,对于zookeepr的配置,你至少要在hbase-site.xml中列出zookeepr 的 ensemble servers,具体的字段是hbase.zookeeper.quorum.在这里列出 Zookeeper 集群的地址列表,用逗号分割。
hbase.zookeeper.property.clientPort:ZooKeeper 的 zoo.conf 中的配置,客户端连接的端口。hbase.zookeeper.property.dataDir:ZooKeeper 的 zoo.conf 中的配置。对于独立的Zookeeper,要指明Zookeeper的host和端口。需要在hbase-site.xml中设置。
4.配置 conf/regionservers

5.hadoop 配置文件拷入 hbase 的 conf 目录下(当期位置为hbase的conf文件夹下)
cp /usr/ywq/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml .
cp /usr/ywq/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml .6.分发 hbase
scp -r /usr/ywq/hbase root@slave1:/usr/ywq
scp -r /usr/ywq/hbase root@slave2:/usr/ywq7.配置环境变量

8.运行和测试
在 master 上执行(保证 hadoop 和 zookeeper 已开启)
启动顺序:hadoop-->zookeeper-->hbase
在master上启动hadoop集群: /hadoop/hadoop-p-2.7.3/sbin/start-all.sh
在每一台机器上启动zookeeper: /zookeeper/zookeeper-3.5.4-beta/bin/zkServer.sh start
在master上启动hbase集群: bin/start-hbase.sh
在这里列出了希望运行的全部 HRegionServer,一行写一个 host。列在这里的 server 会随着集群的启动而启动,集群的停止而停止。

查看jps:

子节点上查看进程:

9.访问 master 的 hbase web 界面
http://master IP:16010/master-status
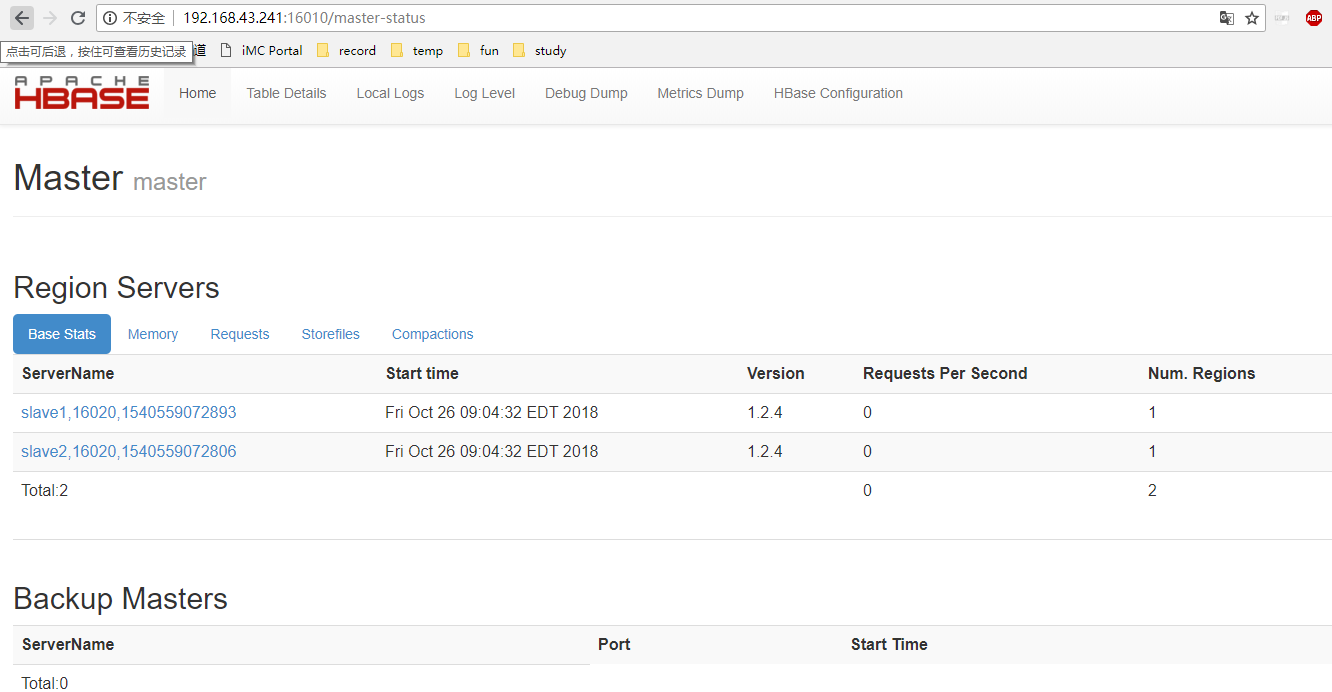
10.进入 hbase 交互界面, 查看状态与版本
