实验+理论
关于字符模式应用
字符模式(命令行模式)应用:
- [可选] 从标准输入读取(stdin)
- 工作
- [可选] 写数据到标准输出(stdout)或标准输出(stderr)
字符模式应用程序通过,console 或 terminal application 和end-user 用户交流。console 转换用户输入(键盘,鼠标,触屏,pen 等),并将其发送到一个字符模式application 的stdin。一个console 可能会显示一个字符模式application 的text output 在一个用户的屏幕上。
windows 中,console 是内置的,并提供丰富的操作API,借此,字符模式app 可以与用户交互。
输入和输出方法
有两种console I/O 的模式,使用哪种取决于application 的复杂程度及需求。高层的方法支持简单的字符流I/O ,但它限制了对于console 的输入输出缓冲的访问。低层的方法需要开发人员写更多的代码,并从更大范围的函数集中做选择,但它给乐application 更大的灵活性。
application 可以使用文件I/O 函数,ReadFile 和 WriteFile ,以及Console 函数 ReadConsole 和 WriteConsole ,来执行高层的I/O ,这些函数提供了对于console 的 输入输出缓冲的间接访问。高层输入函数过滤并处理console 的输入缓冲中的数据,并返回一个字符流格式的输入,丢弃鼠标和缓冲区大小重置输入。类似的,高层输出函数将字符流写入到屏幕缓冲中,并显示在当前光标所在的位置。一个application 通过控制一个console 的I/O 模式来控制这些函数的工作方式。
低层的I/O 函数提供了对于console 的输入和输出缓冲的直接的方法,使得application 访问鼠标和缓冲区-大小重置输入事件,以及扩展的键盘输入事件。低层输出函数使得一个application 读或写屏幕缓冲区中的特定数量的连续字符单元格,或者在屏幕缓冲区中的指定位置读取或写入字符单元的矩形块。console 的输入模式影响低层输入,它决定了application 是否将输入表和缓冲区-重置大小 事件放到输入缓冲中。一个console 的输出模式不会影响低层的输出方法。
高层和低层I/O 方法不是互相独立的,一个application 可以使用这些函数的任意的组合。
console code pages
一个code page 是256 个字符代码到单个字符的映射。不同的代码页包括不同的指定字符,通常是针对一种语言或一组语言定制的。
跟每个console 绑定的,有两个code page:输入和输出。一个console 使用它的输入code page 将键盘输出转换到对应的字符值,使用output code page 来将各种输出函数写的各种字符值转换为显示在console 窗口上的字符图像。一个application 可以使用SetConsoleCP 和 GetConsoleCP 设置和获取console 的input code page ,output code page:SetConsoleOutputCP 和 GetConsoleOutputCP。
本地计算机上可以使用的code page 的ID 存储在如下注册表:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage
Console 控制处理函数
每个console 进程有自己的control handler 函数列表,当进程接收到CTRL+C,CTRL+BREAK或CTRL+CLOSE信号,系统会调用这些函数。初始,每个进程的control handlers 列表仅拥有一个默认的handler 函数,其调用ExitProcess。console process 可以通过调用SetConsoleCtrlHandler 函数添加或删除额外的HandlerRoutine 函数。这个函数不影响其他进程的这个列表。当一个console process 接收到任何control signals,它调用最新注册的 handler functions ,直到其中一个handlers 返回了TRUE。如果没有handlers 返回TRUE,将调用默认的handler。
函数的dwCtrlType 参数表示了当前是哪种control signal,返回值标识此signal 是否被处理。
例子:https://docs.microsoft.com/en-us/windows/console/registering-a-control-handler-function
console 别名
Console 别名用来映射一个源字符串到目标字符串。
console buffer 安全性和访问权限
调用CreateFile 或 CreateConsoleScreenBuffer 时,可以指定自己需要的安全描述符。详情看相关函数即可
console application 问题
8-bit console 函数使用OEM code page,所有其他的函数默认使用ANSI code page。这意味着,console 函数返回的strings,其他函数可能无法正确处理,反之亦然。例如,如果FindFirstFileA 返回一个包含特定的扩展的ANSI 字符,WriteConsoleA 函数将无法正确显示该string。
console application 最好的长期的解决方法是使用unicode。除此之外,console application 应该使用SetFileApisToOEM 函数,这个函数改变相关文件函数,它们将使用OEM 字符集而不是ANSI 字符集。
wiki 中关于code pages 的描述
- windows code pages 是字符集,或code page 集,(其他操作系统上称为,字符编码)。当windows 中实现了 unicode,windows code pages 渐渐被取而代之了,尽管它们仍然在windows 和 其它平台上受支持。
- 有两组code pages,OEM 和 ANSI
ANSI code page
ANSI code page(也称windows code page),windows 系统中,使用GUI 的原生非 unicode application 使用。
ANSI windows code page,特使是 1252 code page(默认情况下,在Microsoft Windows的旧版组件中使用英语和其他一些西方语言(其他语言使用不同的默认编码)),据说它们是基于提交给或打算提交给 ANSI(American National Standards Institute 美国国家标准协会)的草案建立的,因此叫这个名字。但,ANSI 和 ISO 没有这些code page 的任何标准。
OEM code page
OME code page,由win32 console application 和 虚拟 DOS 使用,可以被认为是DOS 和原始 IBM PC架构的延续。实现了一套单独的code page,不仅是因为兼容性,还因为VGA(和后代)硬件的字体建议将线条图字符的编码与code page 437 兼容。大多数OEM 代码页共享许多代码点,特别是对于非字母字符,使用CP437 的第二个(非ANSI)的一半。
实验
char szBuffer[] = "汉";
wchar_t wzBuffer[] = L"汉";
TCHAR tzBuffer[] = TEXT("汉");
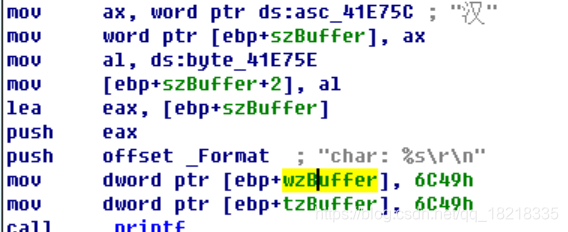
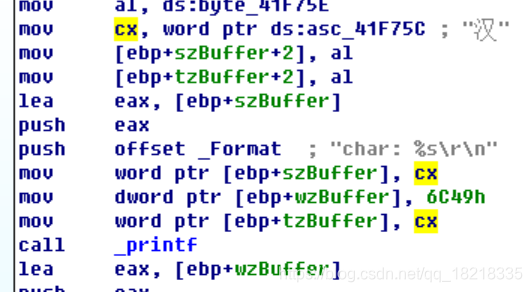
以上两个图,是分别将,字符集设置为unicode 和 multibyte,它们没有区别
编程中,设置字符集(multibyte、unicode 多字节 unicode)到底是设置了什么?
为了支持,那些拥有庞大的字符集的语言(日语,中文),MFC 支持两种处理大字符集的方法:
- unicode wchar_t 基于宽字符 和UTF-16 字符编码
- multibyte character sets(MBCS),char,基于单或多字节 character 和 以特定于语言环境的字符集编码的字符串。(windows 中的字符集编码的概念,就是code page 的概念,因此下面的操作中我们要额外关心code page,包括输入code page 和 输出 code page)
这里的字符集设置其实就是选择性的定义了两个宏:
多字节:_MBCS
UNICODE:_UNICODE
此时将影响,TCHAR 的定义(间接影响到CString的类型)、默认的函数类型(A函数还是W 函数)。
新开发的应用程序尽量使用UNICODE,以支持国际化操作。
wchar_t 与 gbk2312
- 注意,我本机设置的系统默认字符集为英文
- 使用的是C 语言
- 上面说了,使用unicode 和 多字节的影响范围,下面的代码没有使用到相关函数,因此结果总是一样的
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<tchar.h>
#include<windows.h>
#include<locale.h>
#include<string.h>
void printCh(LPCSTR strPre,LPCSTR sz)
{
int iIndex = 0;
printf("%s\r\n", strPre);
while (sz[iIndex] != '\0')
{
printf("%2X ", (UCHAR)sz[iIndex++]);
}
printf("\r\n");
}
void printWh(LPCSTR strPre,LPCWSTR wz)
{
int iIndex = 0;
printf("%s\r\n", strPre);
while (wz[iIndex] != L'\0')
{
printf("%2X ", (UCHAR)((BYTE*)wz)[2 * iIndex]);
printf("%2X ", (UCHAR)((BYTE*)wz)[2 * iIndex + 1]);
iIndex++;
}
printf("\r\n");
}
int main()
{
char * szBuffer = (LPSTR)malloc(0x1000);
WCHAR* wzBuffer = (LPWSTR)malloc(0x1000);
char insideSZ[] = "中文";
WCHAR insideWZ[] = L"中文";
printf("%d\r\n", GetACP());
if (szBuffer == NULL)
{
printf("%error ,malloc func error:%d\r\n", GetLastError());
return 0;
}
if (wzBuffer == NULL)
{
free(szBuffer);
szBuffer = NULL;
printf("%error ,malloc func error:%d\r\n", GetLastError());
return 0;
}
printf("%d\r\n", GetACP());
printf("please input some chinese\r\n");
scanf("%s", szBuffer);
printf("there is your input: %s\r\n", szBuffer);
printf("there is inside :%s\r\n", insideSZ);
printf("gbk byte:\r\n");
printCh("input:",szBuffer);
printCh("inside:",insideSZ);
printf("please input some chinese(UTF-8)\r\n");
wscanf(L"%s", wzBuffer);
wprintf(L"there is your input: %s\r\n", wzBuffer);
wprintf(L"there is your inside :%s\r\n", insideWZ);
printf("utf8 byte:\r\n");
printWh("input",wzBuffer);
printWh("inside",insideWZ);
// 清理操作
}
结构如下:
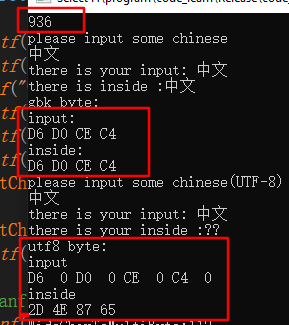
我们看到,刚开始输出的936 表示,当前的code page 为936
https://docs.microsoft.com/en-us/windows/desktop/intl/code-page-identifiers

证明我们的Windows ANSI code page,即,默认的窗口code page 为gbk2312。因此我们才能有机会进行中文的输入输出操作。尽管我本机的默认语言是英语--------这里的默认英语,是后续手动修改的,系统安装的时候,还是选择的中文。后面我们会在真正的英文系统上进行测试
之后,以char 存储的“中文”,的十六进制表示即GBK2312 中对应的十六进制,而从console 输入进来并存储到char 的“中文”与此相同。
这里有几个问题
- 默认的源码文件的保存格式
- console 的输入的code page
- console 的输出的code page
- *A 函数,如何适配不同的系统?
新建一个源码文件的时候,使用的默认保存编码,看来是ANSI,因此,我们以二进制的形式查看代码文件的时候,会发现其字符串, 直接传递给*A 函数后,可以正确的解析----这里有一个问题,当,我们在中文环境下,在源码中,使用了中文字符串,这些字符串,默认,在中文环境可以正常显示;当放到其他语言环境,如果不手动修改输出的code page ,应该是无法正常显示的,下面来实验
int main()
{
char szBuffer[] = "中文";
printf("%s\r\n", szBuffer);
system("pause");
return 0;
}
修改输出的code page:
char szBuffer[] = "中文";
printf("%d\r\n", SetConsoleOutputCP(936));
printf("%s\r\n", szBuffer);
system("pause");
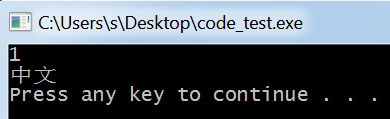
上述结果证明了我们的猜想,但需要注意的是:
刚开始这个程序也没有正确的显示,因为,控制台没有对应的字体来显示我们要求的中文:
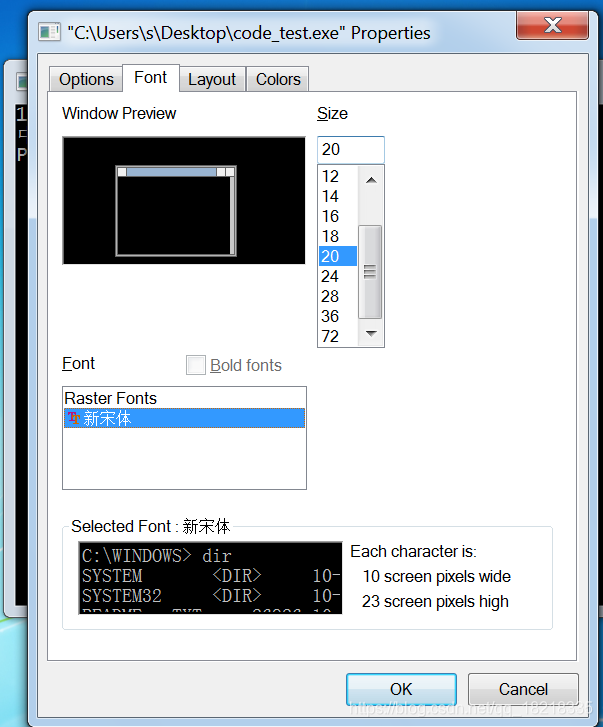
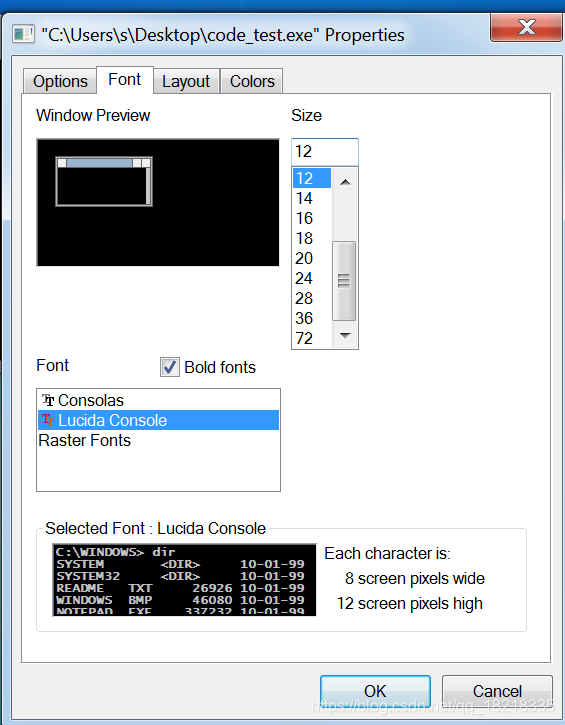
这是修改后的,英文版系统,控制台属性中,默认的字体可不是这个。修改前如下:
当控制台的字体中都没有这个字体的时候,无法正确的显示中文。原因很简单:字体可以理解成,字符编码与显示的字符的对应关系。当这个对应关系中,都没有中文的时候,当然无法显示。
修改方法:
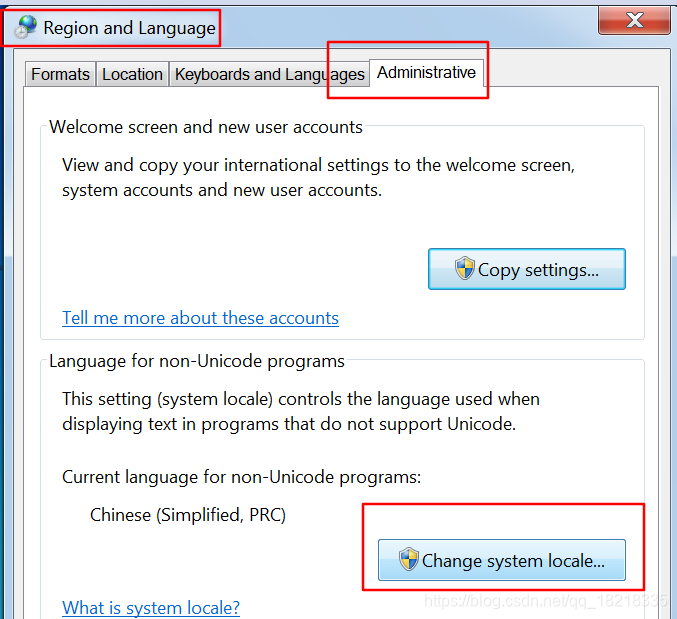
修改后,需要重启才能生效。这里我们改为,中文简体时,才能在控制台正确的输出汉字。
以,wchar 存储的内部“中文”,使用的是UTF-16 编码,而从console 传进来后,由wchar 存储的“中文”,使用的显然是,使用2 字节表示原来GBK 中1字节表示的内容,wchar_t 存储gbk2312 的结果就是这样。而再次向屏幕输出它们的时候,wprintf 可以正常输出wchar 存储的,gbk2312,而UTF-16无法正常显示。
当有国际化的需求,显示其它国家的语言的时候,如何做?
上面我们为了输出中文,将output code page 修改为 936,如果想适应所有的语言,不如直接将其修改为utf-8。一劳永逸,适应性完美。只不过,结合后面,字体的问题,当目标系统上没有要显示的语言的字体,无论如何是显示不出来的。下面,我们使用utf-8 输出中文.我们本机是ansi—gbk2312,如果想输出为utf-8.应该要先转换为wchar–>utf-8。
因此实际编程的时候,我们推荐,直接使用wchar,兼容性和效率都有了。
int pre = GetConsoleOutputCP();
printf("%d\r\n", pre);
printf("%d\r\n", SetConsoleOutputCP(CP_UTF8));
printf("%d\r\n", GetConsoleOutputCP());
printf("%d\r\n", GetACP());
WCHAR wzChar[] = L"中文";
char szBuffer[0x100] = {0};
WideCharToMultiByte(CP_UTF8, 0, wzChar, _countof(wzChar), szBuffer, 0x100, NULL, NULL);
printf("s %s\r\n", szBuffer);//正常
printf("S %S\r\n", szBuffer);
wprintf(L"wprintf %s\r\n", szBuffer);
wprintf(L"wprintf %S\r\n", szBuffer);//正常---->这种方法更推荐,因为,这样L""中的内容也能全部正常显示了。
printf("s %s\r\n", wzChar);
printf("S %S\r\n", wzChar);
wprintf(L"wprintf %s\r\n", wzChar);
wprintf(L"wprintf %S\r\n", wzChar);
printf("%d\r\n", SetConsoleOutputCP(pre));
printf("%d\r\n", GetConsoleOutputCP());
system("pause");
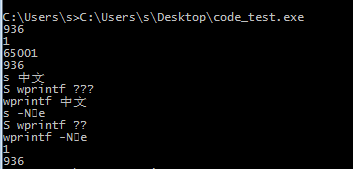
UNICODE to gbk2312
上一篇文章中介绍到了一个函数,
int
WINAPI
WideCharToMultiByte(
_In_ UINT CodePage,
_In_ DWORD dwFlags,
_In_NLS_string_(cchWideChar) LPCWCH lpWideCharStr,
_In_ int cchWideChar,
_Out_writes_bytes_to_opt_(cbMultiByte, return) LPSTR lpMultiByteStr,
_In_ int cbMultiByte,
_In_opt_ LPCCH lpDefaultChar,
_Out_opt_ LPBOOL lpUsedDefaultChar
);
即,宽字符向多字节字符的转换:我们尝试使用:
iLength = WideCharToMultiByte(CP_ACP, 0, insideWZ, -1, NULL, 0, NULL, NULL);
memset(szBuffer, 0, 0x100);
iLength = WideCharToMultiByte(CP_ACP, 0, insideWZ, -1, szBuffer, iLength, NULL, NULL);
printCh("after WideCharToMultiByte",szBuffer);
printf("szBuffer: %s\r\n", szBuffer);
得到结果如下:
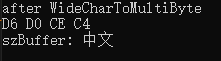
我们成功将宽字符,即utf-16,转换为了gbk2312。
setlocale 如何影响中文的输入输出
当我们在程序起始,调用_tsetlocale 并设置,语言环境为 中文,事情变得有点不同:
int main()
{
char * szBuffer = (LPSTR)malloc(0x1000);
WCHAR* wzBuffer = (LPWSTR)malloc(0x1000);
char insideSZ[] = "中文";
WCHAR insideWZ[] = L"中文";
int iLength = 0;
_tprintf(TEXT("%s\r\n"), _tsetlocale(LC_CTYPE, TEXT("zh-CN")));
if (szBuffer == NULL)
{
printf("%error ,malloc func error:%d\r\n", GetLastError());
return 0;
}
if (wzBuffer == NULL)
{
free(szBuffer);
szBuffer = NULL;
printf("%error ,malloc func error:%d\r\n", GetLastError());
return 0;
}
printf("%d\r\n", GetACP());
printf("please input some chinese\r\n");
scanf("%s", szBuffer);
printf("there is your input: %s\r\n", szBuffer);
printf("there is inside :%s\r\n", insideSZ);
printf("gbk byte:\r\n");
printCh("input:",szBuffer);
printCh("inside:",insideSZ);
printf("please input some chinese(UTF-8)\r\n");
wscanf(L"%s", wzBuffer);
wprintf(L"there is your input: %s\r\n", wzBuffer);
wprintf(L"there is your inside :%s\r\n", insideWZ);
printf("utf8 byte:\r\n");
printWh("input",wzBuffer);
printWh("inside",insideWZ);
return 0;
}
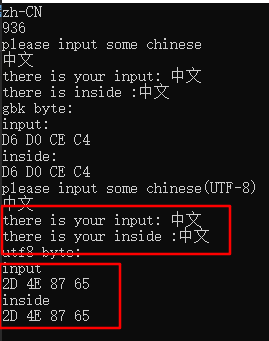
使用wscanf 输入到 wchar_t 时,使用的utf16 存储,且,utf16 和 gbk2312 可同时正常显示。且,GetACP() 在_tsetlocale 之后调用,code page 依然是936。什么情况?


由此我们知道,在执行wprintf 的时候,会自动执行宽字节到,multibyte 的转换。(我没把WideCharToMultiByte 的调用展示出来,单很明显,我们能看到,这里生成了gbk 的字符,因此,确实进行了转换)。
上述过程的代码为:
iLength = WideCharToMultiByte(20936, 0, insideWZ, -1, NULL, 0, NULL, NULL);// 这一步单纯的想得到该函数的地址,好下断点
wprintf(L"there is your inside :%s\r\n", insideWZ);
下面这步,每输出一个字符会中一次断点,我是在输出了“中”字后,开始单步调试,最终看到writefile 字样,猜测是,console 的输出方式,就在那里尝试拿了下参数,最终证明猜测是正确的。各位看官如果有什么问题,欢迎交流,可能上面的过程不是足够详细。(当然,早知道, 这个,wprintf 函数,直接输出“中文“二字,无需其它多余的动作)。
代码文件的保存格式是什么?

显然,是,ANSI 格式(这里是GBK2312)。文章开始的,IDA 中,”中文“对应了不同的编码,是因为,编译器对其进行了处理。
我们脱离这个思考一下,冷静一下。
源码就是文本文件,编码肯定是统一的。
生成的程序中,”字符串“,就是一块儿内存,或者叫字节流,可以通过函数进行解析、转换等操作,因此可以按需存在,硬编码字符串可以这样静态的看到它们编码的不同,当程序运行起来,各种编码的输入输出,当然会产生更多不同的编码数据格式。
utf-8
上面的代码一直有个问题,其中的utf-8 并不是真正的utf-8。UTF-8 的数据长什么样?
我们将源文件copy 一份,然后,使用notepad 保存为utf-8 格式,然后,查看其二进制数据:

众所周知,utf-8 中,中文,每个字符,对应,三个字节。
国际化的软件,如何支持用户选择自己的语言?
#include<iostream>
#include<tchar.h>
#include<windows.h>
#include<string>
using namespace std;
int main()
{
cout << _tsetlocale(LC_CTYPE, TEXT("zh-CN")) << endl;
std::string aStr;
cin >> aStr;
std::wstring wStr(aStr.begin(), aStr.end());
std::u16string u16(wStr.begin(), wStr.end());
std::u32string u32(wStr.begin(),wStr.end());
auto pa = aStr.data();
auto pw = wStr.data();
auto pu16 = u16.data();
auto pu32 = u32.data();
system("pause");
return 0;
}
16进制数据如下:
d6 d0 ce c4 00 gbk
2d 4e 87 65 00 00 utf16
2d 4e 87 65 00 00 utf16
2d 4e 00 00 87 65 00 00 00 00 00 00 utf32