why 要有交叉验证 ?
当模型建立后,我们需要评估下模型的效果,例如,是否存在欠拟合,过拟合等。但是,在我们建立模型时,我们不能使用全部数据用于训练(考试的示例)。因此,我们可以将数据集分为训练集与测试集。然而,模型并不是绝对单一化的,其可能含有很多种不同的配置方案(参数),这种参数不同于我们之前接触过的权重(w)与偏置(b),这是因为,权重与偏置是通过数据学习来的,而这种参数我们需要在训练前事先指定(例如,正则化的参数alpha等),而这些参数取值不同,也可能会导致训练出来模型的结果也不同。我们将这种参数称为超参数。可以说,超参数不是通过训练得出(事先指定),但是超参数的取值可能会对模型性能造成较大的影响。
因此,我们需要不断去调整超参数的值,进而选择一个合适的超参数,使得模型的表现最优(或接近最优)。我们可以使用测试集去验证这一点。然而,这会导致选择的合适超参数后,无法去检验模型最终的效果。此时,我们可将数据进一步划分,即将原来的训练集再次切割,分为两部分:训练集与验证集。训练集用来建立模型(与之前相同),验证集用来选择合适的超参数,而测试集用于最终模型效果的评估(测试集应该总是作为最终结果的评估,而不是作为中间结果的评估)。
前置解释

以前模型参数单一,LinearRegression没有参数。
整个模型确定好了,再去测试集里跑。
现在ridge模型里面有一个alpha了,训练集上 训练 得到w。
还得看一下0.2的效果,右边的测试集看0.2的效果好不好,不好换成 0.6。
那么就缺数据集了;W是机器学习学出来的,Alpha是你创建的时候实现准备好的。
Alpha就是超参数 ,是指定的,不是学出来的。
测试集:永远是模型确定完毕(alpha调参完成之后)用的。
问题:训练集太少;用 k折交叉验证。

缺点:需要计算五次。
之前给的alpha是指定的,不一定是最好的。

给了不同的超参数,模型表现更好了。
使用哪个参数?用交叉验证

交叉验证(k折交叉验证)
将数据分为训练集,验证集与测试集后,可以解决上述的问题,不过,这样划分依然具有缺陷:
- 划分验证集后,会将模型的训练数据进一步减少,不利于模型的训练。
- 不同的划分方式,模型的结果也可能不尽相同。
我们可以使用交叉验证来解决以上问题。在训练集中,我们分成k个部分,然后使用其中的k - 1个部分作为训练集,剩下的一部分作为验证集来对模型进行评估。如此重复的进行k次,最终取k次评估的平均值。这种交叉验证方式我们称为“k折交叉验证”。
k折交叉验证的优缺点如下:
- 优点:不需要额外的验证集数据,因此不会令训练集数据较少。
- 缺点:需要重复计算k次,大大增加的程序的运行时间。
交叉验证程序解释
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
# LassoCV,RidgeCV,ElasticNetCV CV(cross validation 交叉验证)
# 能够进行交叉验证的Lasso, Ridge与 ElasticNet。
from sklearn.linear_model import LassoCV, RidgeCV, ElasticNetCV
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
def true_fun(X):
return np.cos(1.5 * np.pi * X)
np.random.seed(0)
n_samples = 30
x_train = np.sort(np.random.rand(n_samples))
y_train = true_fun(x_train) + np.random.randn(n_samples) * 0.1
X_train = x_train[:, np.newaxis]
# 定义alpha列表,定义alpha参数的候选值,用于进行交叉验证。
alphas = [0.001, 0.005, 0.01, 0.05, 0.1, 0.5]
# 注意,在交叉验证类中(例如,LassoCV),参数为alphas,而不是alpha。
models = [("L1正则化:", LassoCV(alphas=alphas, max_iter=5000)), ("L2正则化", RidgeCV(alphas=alphas)),
("弹性网络", ElasticNetCV(l1_ratio=0.5, alphas=alphas))]
plt.figure(figsize=(18, 5))
for i, (name, model) in enumerate(models):
plt.subplot(1, 3, i + 1)
pipeline = Pipeline([("poly", PolynomialFeatures(degree=15)), ("model", model)])
# cv cross validation 指定交叉验证的份数。即进行几折交叉验证。
pipeline.set_params(model__cv=10)
pipeline.fit(X_train, y_train)
train_score = pipeline.score(X_train, y_train)
# 当训练完毕,进行交叉验证的超参数就也确定了。
print(pipeline.named_steps["model"].alpha_)
x_test = np.linspace(0, 1, 100)
y_test = true_fun(x_test)
X_test = x_test[:, np.newaxis]
test_score = pipeline.score(X_test, y_test)
plt.plot(X_test, pipeline.predict(X_test), label="预测线")
plt.plot(X_test, true_fun(X_test), label="真实线")
plt.scatter(X_train, y_train, c='b', s=20, label="样本数据")
plt.xlabel("x")
plt.ylabel("y")
plt.xlim((0, 1))
plt.ylim((-2, 2))
plt.legend(loc="best")
plt.title(f"{name} 训练集:{train_score:.3f} 测试集:{test_score:.3f}")
plt.show()

why 要有模型持久化 ?
当我们训练好模型后,就可以使用模型进行预测。然而,这毕竟不像打印一个Hello World那样简单,当我们需要的时候,重新运行一次就可以了。在实际生产环境中,数据集可能非常庞大,如果在我们每次需要使用该模型时,都去重新运行程序,势必会耗费大量的时间。
为了方便以后能够复用,我们可以将模型保存,在需要的时候,直接加载之前保存的模型,就可以直接进行预测。其实,保存模型,就是保存模型的参数(结构),在载入模型的时候,将参数(结构)恢复成模型保存时的参数(结构)而已。
保存模型
注意:保存模型时,保存位置的目录必须事先存在,否则会出现错误。
from sklearn.datasets import load_diabetes
# return_X_y参数 对函数的返回内容有影响。默认为False。
# 当设置为True时,仅返回训练集数据,与训练集数据所对应的标签(只返回X与y)。
load_diabetes(return_X_y=True)
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 可以用来保存与恢复模型。
from sklearn.externals import joblib
X, y = load_diabetes(return_X_y=True)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.25, random_state=0)
lr = LinearRegression()
lr.fit(train_X, train_y)
# 对模型对象进行持久化操作。(保存模型对象。)
# 保存的目录必须事先存在,否则会出现错误。
joblib.dump(lr, "lr.model")
载入模型
我们可以载入之前保存的模型,进行预测。
# 从之前保存的模型文件中恢复模型的状态(模型的结构,参数等信息)
model = joblib.load("lr.model")
# model.coef_
# print(model.predict(test_X))
Return_x_y 对结果是有影响的,
看到是二进制,里面还是运用pickle



线性回归的类
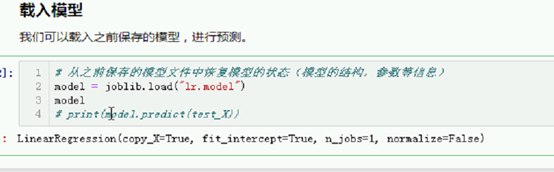
参数值出来了
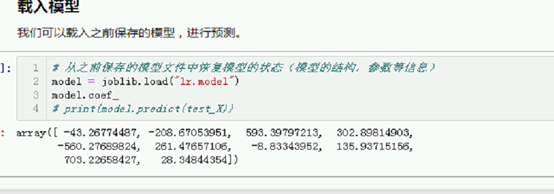

训练一次就行了。