文章目录
函数 function
函数时可以重复执行的语句块,可以重复使用。
作用:
- 用于封装语句块,提高代码的重用性
- 定义用户级别的函数
函数定义(创建)语句 def 语句的语法:
def 函数名(形参列表):
语句块
说明:
函数的名字就是语句块的名称;函数名的命名规则与变量名相同(函数名必须为标识符(字母或下划线开头));函数有自己的名字空间,在函数外部不可以访问函数内部的变量,在函数内部可以访问函数外部的变量,通常让函数处理外部数据需要用参数给函数传入一些数据;函数的参数列表可以为空;语句部分不能为空,如果为空需要填充pass语句
示例:
def say_hello():
print("hello world")
print("hello cat")
print("hello dog")
say_hello()
函数的调用
函数名(实际调用传递参数列表)
注:实际调用传递参数以后称为实参
说明:函数调用是一个表达式,如果没有return语句,此函数执行完毕后返回None对象,如果函数需要返回其他的对象需要用到return语句
示例:
def mymax(a, b):
print("a=", a)
print("b=", b)
if a > b:
print(a, ">", b)
else:
print(a, "<=", b)
mymax(10, 2)
return 语句
语法:
return [表达式]
[] 代表可以省略
作用:用于函数中,结束当前函数的执行,返回到调用该函数的地方,同时返回一个对象的引用关系
说明:(1) return语句后跟的表达式可以省略,省略后相当于return None
(2) 如果函数没有return语句,则函数执行完最后一条语句后返回None(相当于在最后加了一条return None语句)
(3) 函数调用一定会返回一个对象的引用
函数的参数传递
传递方式:
- 位置传参:
示例:
def myfun(a, b, c):
pass
myfun(1, 2, 3)
说明:实际参数和形式参数通过位置进行传递来匹配;实参个数必须与形参个数相同
2. 序列传参:序列传参是指在函数调用过程中,用*将序列拆解后按位置传参的方式进行参数传递
示例:
def myfun(a, b, c):
pass
s = [1, 2, 3]
myfun(*s) # *表示把s拆开, 等同于myfun(s[0], s[1], s[2])
s2 = "ABC"
myfun(*s2)
- 关键字传参:关键字传参是指传参时,按照形参的名称给形参赋值,实参和形参按名称进行匹配
示例:
def myfun(a, b, c):
pass
myfun(b=22, c=33, a=11) # 等同于myfun(11, 22, 33)
说明:实参和形参可以不按位置匹配
4. 字典关键字传参:是指实参为字典,将字典用**拆解后进行关键字传参
示例:
def myfun(a, b, c):
pass
d = {'c': 33, 'b': 22, 'a': 11}
myfun(**d) # 拆解字典后再传参,相当于myfun(d['a'], d['b'], d['c'])
# 以下是错误的用法
d1 = {'c': 33, 'b': 22, 'a': 11, 'd': 44}
myfun(**d1)
说明:字典的键名和形参名必须一致;字典键名必须为字符串;字典的键名要在形参中存在
函数的综合传参
函数传参方式,在能确定形参能唯一匹配到相应实参的情况下可以任意组合
示例:
def myfun(a, b, c):
pass
myfun(100, *[200, 300]) #正确
myfun(*"AB", 300) # 正确
myfun(100, c=300, b=200) # 正确
myfun(1, **{'b': 2, 'c': 3}) # 正确
myfun(**{'b': 2, 'c': 3}, a=1) # 正确
myfun(b=2, c=3, 1) # 错误,不能确定1给那个参数
说明:传参时先位置传参,后关键字传参
函数的形参(如何接受实参)
函数的缺省参数
语法:
def 函数名(形参名1=默认实参1, 形参名2=默认实参2, …):
…
示例:
def info(name, age=1, address="未填写"):
print(name, age, address)
info('xiaomaomao', 2)
info('xiaoxiaomao', 20, '北京')
info('cat')
说明:(1)缺省参数必须自右至左依次存在,如果一个参数有缺省参数,则其右侧的所有参数都必须有缺省参数
如:
def test(a, b=10, c): # <—是错的,b是缺省参数,则c必须是缺省参数
pass
(2) 缺省参数可以有0个或多个,甚至全部都有缺省参数。
函数的形参定义方式
- 位置形参
语法:
def 函数名(形参名1, 形参名2, …):
语句块 - 星号元组形参
语法:
def 函数名(*元组形参名):
语句块
作用:收集多合的位置传参
说明:元组形参名通常用‘args’
示例:
def func(*args):
print("参数个数是:", len(args))
print("args=", args)
func(1, 2, 3, 4)
func("hello", "world", 1, 2, 3)
- 命名关键字形参
语法:
def 函数名(*, 命名关键字形参):
语句
或
def 函数名(*args, 命名关键字形参):
语句
作用:所有的参数都必须用关键字传参或字典关键字传参
示例:
def fn(*, d, e):
print(d)
print(e)
fn(d=100, e=200) # 合法
fn(1, 2) # 不合法,不能用位置传参
def fm(*args, d, e):
print(args)
print(d)
print(e)
fm(1, 2, d=100, e=200)
fm(*'AB', **{'e': 20, 'd': 10})
- 双星号字典形参
语法:
def 函数名(**字典形参名):
语句
作用:收集多余的关键字传参
说明:通常字典形参名定位:“kwargs”
示例:
def func(**kwargs):
print("关键字参数个数是:", len(kwargs))
print("kwargs:", kwargs)
func(name='xiaoxiaomao', age=1)
func()
函数的形参说明:缺省参数,位置形参,星号元组形参,命名关键字形参和双星号字典形参可以混合使用
函数参数自左向右顺序为:位置形参,星号元组形参,命名关键字形参,双星号字典形参
示例:
def f1(a, b, *args, c, **kwargs):
pass
f1(1, 2, 3, 4, d=6, c=5, e=7) # 合法
f1(*"hello", d=6, **{'c':5, 'e':7}) # 合法
函数的不定长参数
def fn(*args, **kwargs):
pass
可以接受任意位置传参和关键字传参
示例:
def fn(*args, **kwargs):
print(args)
print(kwargs)
fn()
fn(1, 2, 3, 4)
fn(1, 2, a=5, b=6)
全局变量和局部变量
局部变量:定义在函数内部的变量称为局部变量(函数的形参也是局部变量);局部变量只能在函数内部使用;局部变量在函数调用时才能够被创建,在函数调用之后自动销毁。
全局变量:定义在函数外部,模块内部的变量称为全局变量;全局变量所有的函数都可以直接访问(但函数内部不能将其直接赋值)
示例:
a = 100 # 全局变量
b = 200 # 全局变量
def fx(c): # fx 也是全局变量
d = 300 # 局部变量
print(a, b, c, d) # 在函数内部可以访问全局变量
fx(300) # 100 200 300 300
print('a=', a) # a=100
print('b=', b) # b=200
print('d=', d) # 函数外部不能访问函数内部的局部变量
局部变量说明:
(1) 在函数内首次对变量赋值是创建局部变量,再次为变量赋值是修改局部变量的绑定关系
(2) 在局部变量内部的赋值语句不会对全局变量造成影响
(3) 局部变量只能在其被声明的函数内部访问,而全局变量可以在整个模块范围内访问
globals 和 locals 函数
globals() 返回当前全局作用域内变量的字典
locals() 返回当前局部作用域内变量的字典
示例:
a = 1
b = 2
c = 3
def fn(c, d):
e = 300
print("locals()返回:", locals())
print("-------------------------")
for k, v in globals().items():
print(k, '---->', v)
print(c) # 100
print(globals()['c']) # 3 全局变量c的值
fn(100, 200)
# 上面代码会返回如下结果
'''
locals()返回: {'e': 300, 'd': 200, 'c': 100}
-------------------------
__name__ ----> __main__
__doc__ ----> None
__package__ ----> None
__loader__ ----> <_frozen_importlib_external.SourceFileLoader object at 0x1041f24e0>
__spec__ ----> None
__annotations__ ----> {}
__builtins__ ----> <module 'builtins' (built-in)>
__file__ ----> Desktop/test/pythonTest/test02.py
__cached__ ----> None
a ----> 1
b ----> 2
c ----> 3
fn ----> <function fn at 0x104177e18>
100
3
'''
函数变量
函数名是变量,它在创建函数时绑定一个函数。
示例:
def f1():
print("f1被调用")
fx = f1
fx()
def f1():
print("hello")
def f2():
print("world")
f1, f2 = f2, f1 # 交换两个变量的绑定关系
f1() # world
一个函数可以作为另一个函数的参数传递
示例:
def f1():
print("hello")
def f2():
print("world")
def fx(fn):
print(fn)
fn()
fx(f1)
# <function f1 at 0x10af83e18>
# hello
def fx(a, fn):
return fn(a)
L = [5, 9, 4, 6]
print("最大值是:", fx(L, max)) # 最大值是: 9
print("最小值是:", fx(L, min)) # 最小值是: 4
print("和是:", fx(L, sum)) # 和是: 24
函数可以返回另一个函数(即:另一个函数可以返回一个函数)
示例:
def get_fx():
s = input("请输入您要做的操作:")
if s == '求最大':
return max
elif s == '求最小':
return min
elif s == '求和':
return sum
L = [2, 4, 6, 8, 10]
print(L)
f1 = get_fx()
print(f1(L))
函数的嵌套定义
函数的嵌套定义是指一个函数里用def语句来创建其他的函数
示例:
def fn_outer():
print("fn_outer被调用!")
def fn_inner():
print("fn_inner被调用")
fn_inner()
fn_inner()
print("fn_outer调用结束")
return fn_inner
fn_outer()
print("-------------------")
fx = fn_outer()
fx() # 调用fn_outer内部创建的函数
# 上面函数返回以下结果
fn_outer被调用!
fn_inner被调用
fn_inner被调用
fn_outer调用结束
-------------------
fn_outer被调用!
fn_inner被调用
fn_inner被调用
fn_outer调用结束
fn_inner被调用
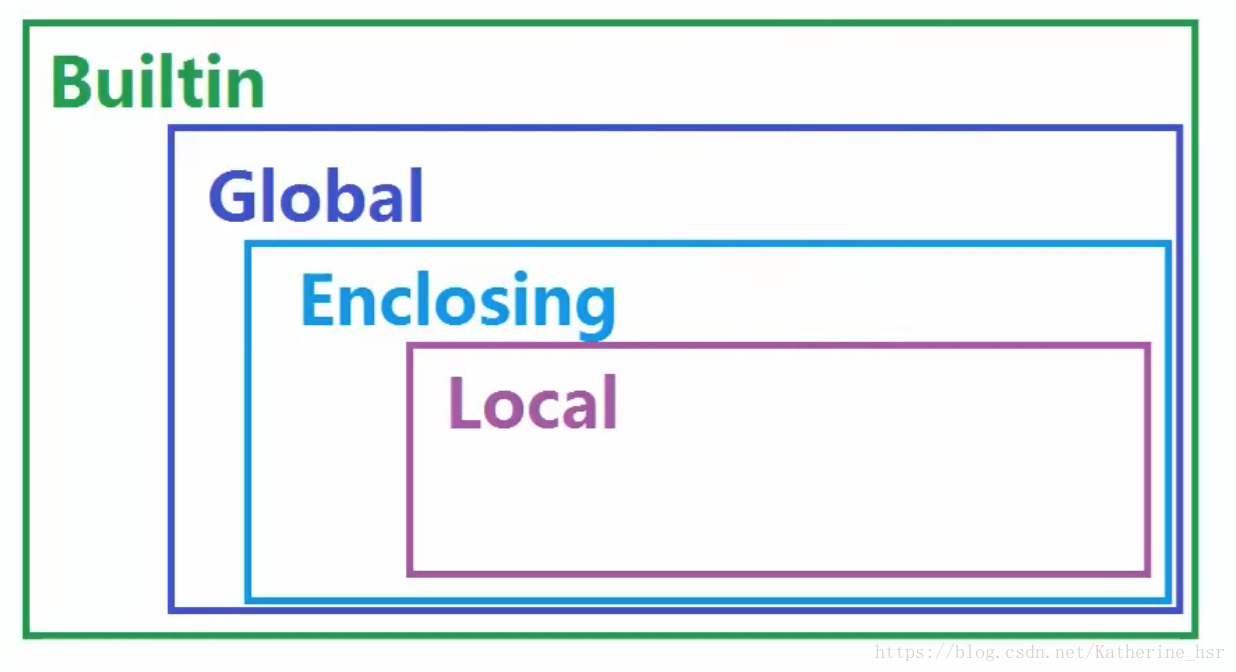
python 作用域
作用域也叫名字空间,是访问变量时,查找变量名的范围空间
python中的四个作用域:
局部作用域(local function L)
外部嵌套函数作用域(enclosing function locals E)
函数定义所在模块(文件)的作用域(global/mudule G)
python内置模块的作用域(Builtin/python B)
示例:
v = 100 # 全局作用域
def fun1():
v = 200 # 外部嵌套函数的作用域
print("fun1内的v=", v)
def fun2():
v = 300 # 局部作用域
print("fun2内的v=", v)
fun2()
fun1()
print("全局作用域v=", v)
# 上面代码运行得到如下结果:
fun1内的v= 200
fun2内的v= 300
v= 100
几种作用域关系如下:
变量名查找规则:
L->E->G->B
在默认情况下,对变量名赋值会创建或改变作用域内的变量。
global 语句
作用:(1) 告诉解释器,global语句声明的一个或多个变量,这些变量的作用域为模块级的作用域,也称为全局变量
(2) 全局声明(global)将赋值变量映射到模块内部的作用域。
语法:global 变量1, 变量2, …
示例:
v = 100
def fn():
global v
v = 200
fn()
print(v) # 200
global说明:(1)全局变量如果要在函数内部被赋值,则必须经过全局声明(f否则会被认为是局部变量)。(2)全局变量在函数内部不经过声明就可以直接访问。(3) 不能先声明局部的变量,再用global声明为全局变量,此做法不符合规则。(4) global 变量列表里面的变量不能出现在此作用域内的形参列表里面。
nonlocal 语句
作用:告诉解释器,nonlocal声明的变量不是局部变量,也不是全局变量,而是外部嵌套函数内的变量
语法:nonlocal 变量名1, 变量名2, …
示例:
var = 100
def f1():
var = 200
print("f1里面的var=", var)
def f2():
nonlocal var
var = 300 # 修改f1里的var
print("f2里面的var", var)
f2()
print("f2调用结束后f1里的var值为", var)
f1()
print("全局var=", var)
#程序运行后打印出以下结果:
f1里面的var= 200
f2里面的var 300
f2调用结束后f1里的var值为 300
全局var= 100
nonlocal 说明:
(1) nonlocal 语句只能在被嵌套函数内部进行使用
def f1():
nonlocal var # 错误的,因为没有外部嵌套函数
var = 200
(2) 访问nonlocal变量将对外部嵌套函数的作用域的变量进行操作
(3) 当有两层或两层以上的函数嵌套时,访问nonlocal变量只对最近一层的变量进行操作
def f1():
v = 100
def f2():
v = 200
def f3():
nonlocal v # 只对f2里的v进行操作
v = v + 1
f3()
print("f2最后的v=", v)
f2()
print("f1最后的v=", v)
f1()
(4) nonlocal语句的变量列表里面的变量名,不能出现在此函数的参数列表中
def f1():
v = 200
def f2(v):
nonlocal v # 出错,v已在形参列表中
v = v + 1
f2(20)
f1()
lambda 表达式
作用:创建一个匿名函数对象,同def类似,但不提供函数名
语法:lambda [参数1, 参数2, …]: 表达式
[]中的内容可以省略
示例:
myadd = lambda x, y: x+y
print("2 + 3 =", myadd(2, 3))
lambda x: x**2 + 5
(2)
fx = lambda x: True if (x**2 + 1) % 5 == 0 else False
print(fx(3))
lambda语法说明:
(1) lambda 只是一个表达式,它用来创建一个函数对象
(2) 当lambda表达式调用时,先执行冒号后(:)的表达式,并返回表达式的结果的引用
(3) lambda表达式创建的函数只能包含一条“表达式”
(4) lambda比函数简单,并且可以随时创建和销毁,有利于减小程序的偶合度
eval() 和 exec() 函数
eval()函数:
格式:eval(source, global=None, locals=None)
作用:把一个字符串当成一个表达式来执行,返回表达式执行后的结果
示例:
x = 100
y = 200
a = eval("x + y")
print(a) # 300
L = eval("list(range(10))")
print(L) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
exec()函数:
作用:把一个字符串当成程序来执行
格式:exec(source, globals=None, locals=None)
示例:
x = 100
y = 200
s = 'z = x + y; print(z); del z; print("删除成功")'
exec(s)
# 300
# 删除成功
eval()和exec()的两个参数globals和locals
这两个参数是用来设置‘表达式’或‘程序’运行的全局变量和局部变量
示例:
x = 100
y = 200
s = 'print(x, y, x + y)'
exec(s) # 100, 200, 300
exec(s, {'x': 10, 'y': 20}) # 10, 20, 30
exec(s, {'x': 10}, {'x': 1, 'y': 2}) # 1, 2, 3
exec(s, {'x': 10}, {'y': 2}) # 10, 2, 12
函数式编程
函数式编程是指用一系列函数决定问题
函数是一等公民,函数本身可以赋值给变量,赋值后变量绑定函数,允许将函数本身作为参数传入另一个函数,允许返回一个函数
函数的可重入性:可重入是指一个函数传的参数一定,则结果必须一定
要求:def定义的函数不要访问除了局部变量以外的变量
示例:
# 以下是不可重入的函数
y = 200
def myadd(x):
return x + y
print(myadd(10)) # 210
y = 300
print(myadd(10)) # 310
# 以下是可重入的函数
def myadd(x, y):
return x + y
print(myadd(10, 20)) # 30
高阶函数 High Order Function
满足下列一个条件的函数就称为高阶函数:
(1) 函数接受一个或多个函数作为参数传入
(2) 函数返回一个函数
示例:
def f1(fx, x, y):
return fx(x, y)
python 中内建(builtins)的高阶函数: map, filter, sorted
map 函数
map(func, *iterables) 用函数和对可迭代对象中的每一个元素作为参数计算出新的可迭代对象,当最短的一个可迭代对象不再提供数据时,此可迭代对象生成结束。
示例:
def pow2(x):
return x**2
for x in map(pow2, range(1, 10)):
print(x)
for x in map(pow, range(1, 10), range(4, 0, -1)):
print(x)
print(sum(map(lambda x: x**2, range(1, 10))))
print(sum(map(pow, range(1, 10), range(9, 0, -1))))
filter 函数
格式:filter(func, iterable)
作用:筛选可迭代对象iterable中的数据,返回一个可迭代对象,此可迭代对象将对iterable进行筛选
说明:函数func将对每个元素进行求值,返回False则将此数据丢弃,返回True则保留此数据
示例:
def isodd(x): # 断x是否为奇数
return x % 2 == 1
for x in filter(isodd, range(10)):
print(x)
even = [x for x in filter(lambda x: x % 2 == 0, range(10))] # 筛选出1-10中的偶数
print(even)
# 返回1-100之中所有的素数
def isprime(n):
for x in range(2, n):
if n % x == 0:
return False
break
return True
prime = [x for x in filter(isprime, range(100))]
print(prime)
sorted 函数
作用:将原可迭代对象的数据进行排序,生成排序后的列表
格式: sorted(iterable, key=None, reverse=False)
说明:iterable 可迭代对象;key 函数是用来提供一个参考值,这个值将作为排序的依据;reverse 标志用来设置是否降序排序
示例:
L = [5, -2, -4, 0, 3, 1]
L2 = sorted(L) # [-4, -2, 0, 1, 3, 5]
L3 = sorted(L, reverse=True) # [5, 3, 1, 0, -2, -4]
L4 = sorted(L, key=abs) # [0, 1, -2, 3, -4, 5]
names = ['Tom', 'Jerry', 'Spike', 'Tyke']
l = sorted(names, key=len)
# names = ['Tom', 'Jerry', 'Spike', 'Tyke']
# 让names排序,排序的依据是字符串的反序 ‘omT’ 'yrreJ' 'ekipS' 'keyT'
# 排序后:
# L2 = ['Spike', 'Tyke', 'Tom', 'Jerry']
names = ['Tom', 'Jerry', 'Spike', 'Tyke']
def fx(name):
return name[::-1]
L2 = sorted(names, key=fx)
# 方法2
L2 = sorted(names, key=lambda n: n[::-1])
递归函数 recursion
函数直接或间接的调用自身
示例:
# 直接调用自身
import time
def story():
time.sleep(1)
print("story")
story() # 直接调用自身
story()
# 间接调用自身
def fa():
fb()
def fb():
fa()
fa()
递归说明:递归一定要控制递归的层数,当符合某一条件时要终止递归;几乎所有的递归都能用while循环来代替
控制递归层次的示例:
def fx(n):
print("递归进入第", n, "层")
if n == 3:
return
fx(n + 1)
print("递归退出第", n, "层")
fx(1)
print("程序结束")
递归的优缺点:
优点:递归可以把问题简单化,让思路更为清晰,代码更简洁
缺点:递归因系统环境影响大,当递归深度太大时,可能会得到不可预知的结果
def mysum(x):
if x == 1: # 设置递归的终止点
return 1
return x + mysum(x-1)
v = mysum(10)
print(v)
下面示例一个递归遍历列表的的经典案例:
# 已知有列表 L = [[3, 5, 8], 10, [[13, 14], 15, 18], 20]
# 写一个函数print_list(lst)打印出所有元素print_list(L)
# 写一个函数sum_list(lst)返回这个列表中所有元素的和
def print_list(lst):
for x in lst: # x可能绑定列表,也可能绑定整数
if type(x) is list:
print_list(x)
else:
print(x)
L = [[3, 5, 8], 10, [[13, 14], 15, 18], 20]
print_list(L)
def sum_list(lst):
sum = 0
# 在此处累加所有元素,包括列表
for x in lst:
if type(x) is list:
sum = sum + sum_list(x)
else:
sum = sum + x
return sum
print(sum_list(L))
闭包 closrue
将内嵌函数的语句和这些顺序执行环境打印在一起时,得到的对象称为闭包(closure)
闭包必须满足三个条件:(1) 必须有一个内嵌函数 (2) 内嵌函数必须引用外部函数中的变量 (3) 外部函数返回值必须是内嵌函数
示例:
def make_power(y):
def fx(arg):
return arg ** y
return fx
pow2 = make_power(2)
print('3的平方是:', pow2(3))
pow3 = make_power(3)
print("3的立方是:", pow3(3))
# 用参数返回相应的数学函数示例
# y = ax^2 + bx + c
def make_function(a, b, c):
def fx(x):
return a*x**2 + b*x +c
return fx
#创建一个 y=4^2 + 5x2 + 6的函数
fx1 = make_function(4, 5, 6)
print(fx1(2))