Tip:博客又有几天没写了,主要是准备期末考试(心累),不过每天还是坚持在牛客网上刷题,虽然很多题目正确率并不是太高,但是还是能学到很多东西。目前主要刷的还是java方面的题目,今天来总结总结最近的错题。
1.有关hashMap跟hashTable的区别,说法正确的是?ABCD
A.HashMap和Hashtable都实现了Map接口
B.HashMap是非synchronized,而Hashtable是synchronized
C.HashTable使用Enumeration,HashMap使用Iterator
D.Hashtable直接使用对象的hashCode,HashMap重新计算hash值,而且用与代替求模
解析:
HashTable和HashMap区别
①继承不同。
public class Hashtable extends Dictionary implements Map
public class HashMap extends AbstractMap implements Map
②
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
③
Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
④两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
⑤
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
⑥
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
- 关于访问权限说法正确 的是 ? ( )
A.类定义前面可以修饰public,protected和private
B.内部类前面可以修饰public,protected和private
C.局部内部类前面可以修饰public,protected和private
D.以上说法都不正确
解析:
对于外部类来说,只有两种修饰,public和默认(default),因为外部类放在包中,只有两种可能,包可见和包不可见。
对于内部类来说,可以有所有的修饰,因为内部类放在外部类中,与成员变量的地位一致,所以有四种可能
3.以下哪一个不是赋值符号?
A.+=
B.<<=
C.<<<=
D.>>>=
.>>为带符号右移,右移后左边的空位被填充为符号位
.>>>为不带符号右移,右移后左边的空位被填充为0
.没有<<< 因为<<后右边总是补0
4.说明输出结果。
package test;
import java.util.Date;
public class SuperTest extends Date{
private static final long serialVersionUID = 1L;
private void test(){
System.out.println(super.getClass().getName());
}
public static void main(String[]args){
new SuperTest().test();
}
}
A.SuperTest
B.SuperTest.class
C.test.SuperTest
D.test.SuperTest.class
1.首先 super.getClass() 是父类的getClass()方法,其父类是Date,它的getClass()方法是继承自Object类而且没有重写,
所以就是调用object的getClass()方法。而看一下getclass的方法 所以可以知道是返回当前运行时的类。
2.在调用getName()方法而getName()是:包名+类名
5.下面哪些情况下需要使用抽象类?
A当一个类的一个或多个方法是抽象方法时
B当类是一个抽象类的子类,并且不能为任何抽象方法提供任何实现细节或方法体时
C当一个类实现多个接口时
D当一个类实现一个接口,并且不能为任何抽象方法提供实现细节或方法体时
解析:
1.A选项。一个类中有抽象方法则必须申明为抽象类。
public abstract class HaveAbstractMethod {
public abstract void method1();}
2.B选项。 我建一个接口,然后一个抽象类implements这个接口,并override的所有方法。然后我在建一个类extends这个抽象类,并且不能为任何抽象方法提供任何细节或方法体时,这时这个类必须是抽象类。
public interface MyInterface { public void method1();}
public abstract class MyAbstractClass implements MyInterface{
@Override
public void method1() { } }
public abstract class ChildAbstractClass extends MyAbstractClass{
@Override
public abstract void method1();
}
3.D选项。我建一个接口,然后一个类implements这个接口,并且不能为任何抽象方法提供任何细节或方法体时,这个类必须是抽象类,并override的所有方法。然后我在建一个普通类extends这个抽象类,就可以为所欲为了 。这种情况就是java设计模式中的适配器模式。
public interface MyInterface { public void method1();}
public abstract class MyAbstractClass implements MyInterface{
@Override
public void method1() { } }
public class MyNormalClass extends MyAbstractClass{
@Override
public void method1() {System.out.println("from method1");}
6.关于ThreadLocal类 以下说法正确的是
A.ThreadLocal继承自Thread
B.ThreadLocal实现了Runnable接口
C.ThreadLocal重要作用在于多线程间的数据共享
D.ThreadLocal是采用哈希表的方式来为每个线程都提供一个变量的副本
E.ThreadLocal保证各个线程间数据安全,每个线程的数据不会被另外线程访问和破坏
解释:
选DE.
1、ThreadLocal的类声明:
public class ThreadLocal
可以看出ThreadLocal并没有继承自Thread,也没有实现Runnable接口。所以AB都不对。
2、ThreadLocal类为每一个线程都维护了自己独有的变量拷贝。每个线程都拥有了自己独立的一个变量。
所以ThreadLocal重要作用并不在于多线程间的数据共享,而是数据的独立,C选项错。
由于每个线程在访问该变量时,读取和修改的,都是自己独有的那一份变量拷贝,不会被其他线程访问,
变量被彻底封闭在每个访问的线程中。所以E对。
3、ThreadLocal中定义了一个哈希表用于为每个线程都提供一个变量的副本:
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
}
所以D对。
7.执行以下程序后的输出结果是()
public class Test {
public static void main(String[] args) {
StringBuffer a = new StringBuffer("A");
StringBuffer b = new StringBuffer("B");
operator(a, b);
System.out.println(a + "," + b);
}
public static void operator(StringBuffer x, StringBuffer y) {
x.append(y); y = x;
}
}
A. A,A
B. A,B
C. B,B
D. AB,B
解释:
StringBuffer a = newStringBuffer(“A”);
StringBuffer b = newStringBuffer(“B”);
此时内存中的状态如下图所示:

public static void operator(StringBuffer x, StringBuffer y) {
x.append(y); y = x;
}
进入如下方法后,内存中的状态为:
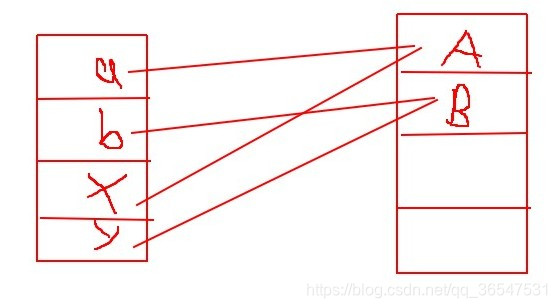
x.append(y);
这条语句执行后,内存的状态为:
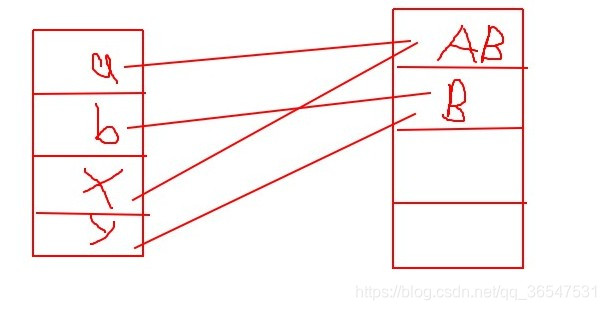
y = x;
这条语句执行后,内存的状态为:
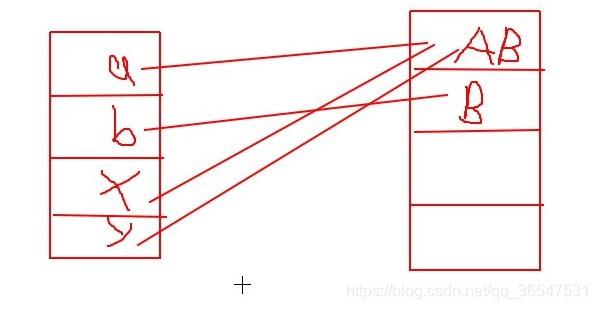
当operator方法执行完毕后内存中的状态为:因为方法执行完毕,局部变量消除。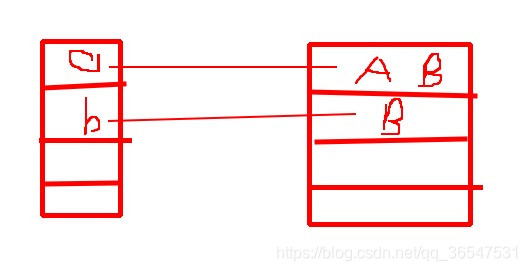
有内存中的状态,可以知道最后的结果。
- 下列在Java语言中关于数据类型和包装类的说法,正确的是()
A.基本(简单)数据类型是包装类的简写形式,可以用包装类替代基本(简单)数据类型
B.long和double都占了64位(64bit)的存储空间。
C.默认的整数数据类型是int,默认的浮点数据类型是float。
D.和包装类一样,基本(简单)数据类型声明的变量中也具有静态方法,用来完成进制转化等。
A,包装和基本类型不是同一个概念
B,long和double都占了64位(64bit)的存储空间
C,默认的浮点数据类型是double,如果要指明使用float,则需要在后面加f
D,基本数据类型是没有静态方法的,但是基本数据类型的包装类却有
9.下面哪几个函数 public void example(){…} 的重载函数?()
A.public void example(int m){…}
B.public int example(){…}
C.public void example2(){…}
D.public int example(int m,float f){…}
java重载的时候以参数个数和类型作为区分,方法名相同,返回类型可以相同也可以不同,但不以返回类型作为区分,所以b也是错的,因为b的参数列表和原来的一样,
10.final、finally和finalize的区别中,下述说法正确的有?
A.final用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
B.finally是异常处理语句结构的一部分,表示总是执行。
C.finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源的回收,例如关闭文件等。
D.引用变量被final修饰之后,不能再指向其他对象,它指向的对象的内容也是不可变的。
选AB
A,D考的一个知识点,final修饰变量,变量的引用(也就是指向的地址)不可变,但是引用的内容可以变(地址中的内容可变)。
B,finally表示总是执行。但是其实finally也有不执行的时候,但是这个题不要扣字眼。
- 在try中调用System.exit(0),强制退出了程序,finally块不执行。
- 注:finally块语句唯一不执行的情况:异常处理代码catch中执行System.exit(1)退出Java虚拟机 ;
C,finalize方法,这个选项错就错在,这个方法一个对象只能执行一次,只能在第一次进入被回收的队列,而且对象所属于的类重写了finalize方法才会被执行。第二次进入回收队列的时候,不会再执行其finalize方法,而是直接被二次标记,在下一次GC的时候被GC。
放一张图吧

一.final
如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承。因此一个类不能既被声明为 abstract的,又被声明为final的。将变量或方法声明为final,可以保证它们在使用中不被改变。被声明为final的变量必须在new一个对象时初始化(即只能在声明变量或构造器或代码块内初始化),而在以后的引用中只能读取,不可修改。被声明为final的方法也同样只能使用,不能覆盖(重写)。
二.finally
在异常处理时提供 finally 块来执行任何清除操作。如果抛出一个异常,那么相匹配的 catch 子句就会执行,然后控制就会进入 finally 块(如果有的话)。
三.finalize
方法名。Java 技术允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是在 Object 类中定义的,因此所有的类都继承了它。子类覆盖 finalize() 方法以整理系统资源或者执行其他清理工作。finalize() 方法是在垃圾收集器删除对象之前对这个对象调用的。注意:finalize不一定被jvm调用,只有当垃圾回收器要清除垃圾时才被调用。