1.线性表基本概念

数据元素与数据项:
一个数据元素包括多个数据项:例如单个数据元素由年龄,姓名,ID组成。
2.数组初始化
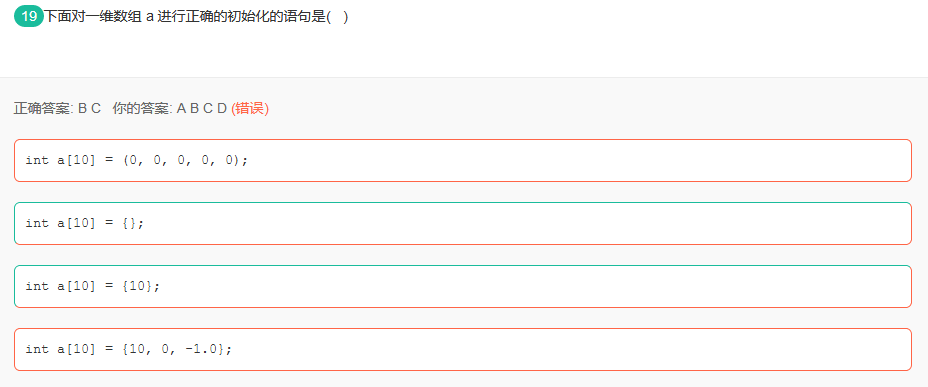
注意B选型,在C语言中是不能那样初始化的,语法错误。在C++中,是正确的,默认填充0。这样的题就烦得很,没法做。
而D选型,在C语言中是正确的,牛客网错了,我在VS中运行了的。
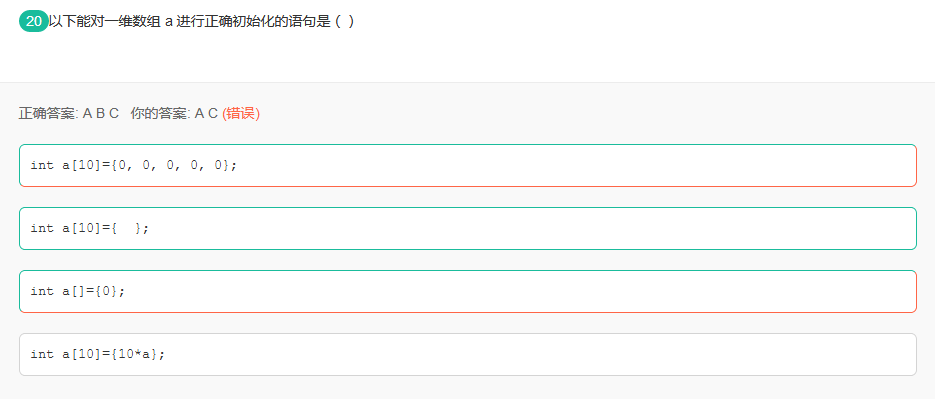

指针没有乘法
2.2二维数组初始化问题

不管他是不是爪哇,就看D选项,在C语言中不行,右边第二个中括号不能为空,在C++中可以。

3.稀疏矩阵

设m*n 矩阵中有t 个非零元素且t<<m*n,这样的矩阵称为稀疏矩阵。很多科学管理及工程计算中,常会遇到阶数很高的大型稀疏矩阵。如果按常规分配方法,顺序分配在计算机内,相当浪费内存的。为此提出另外一种存储方法,仅仅存放非零元素。但对于这类矩阵,通常零元素分布没有规律,为了能找到相应的元素,所以仅存储非零元素的值是不够的,还要记下它所在的行和列。于是采取如下方法:将非零元素所在的行、列以及它的值构成一个三元组(i,j,v),然后再按行优先(或列优先)存储这些三元组,这种方法可以节约存储空间。
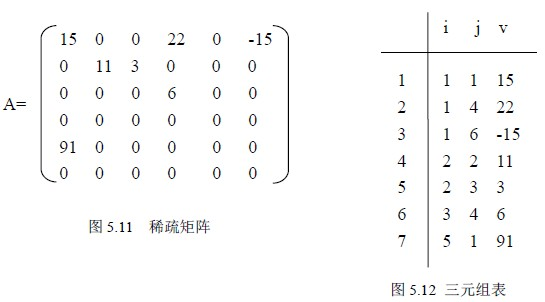
三元素数据结构定义示意:
#define MAXSIZE 10
typedef struct
{
int i, j;//行,列坐标
int v;//元素值
}Triple;
typedef struct
{
int row, column,t;//矩阵的行列值、非0元素个数
Triple data[MAXSIZE];
}SPMatrix;十字链表表示法
稀疏矩阵转置(三元组):
稀疏矩阵的三元组表示中,元素的排列是有规则的,一般是先行后列。所以在对稀疏矩阵进行转置后,也要重排三元组的顺序。
- 将矩阵的行列值互换
- 将每个三元组中的i和j互换
- 重排三元组之间的次序。
//稀疏矩阵的三元组存储,基本操作:建立,输出,转置
#include<stdio.h>
#define MAXSIZE 10
typedef struct
{
int i, j;//行,列坐标
int v;//元素值
}Triple;
typedef struct
{
int row, column,t;//矩阵的行列值、非0元素个数
Triple data[MAXSIZE];
}SPMatrix;
void CreateSPMatrix(SPMatrix *m)
{
printf("请输入矩阵的行数、列数、非0元素个数:\n");
scanf("%d,%d,%d", &m->row, &m->column, &m->t);
for (int i = 0; i < m->t; i++)
{
printf("请输入第%d个元素的行号、列号及值:\n",i+1);
scanf("%d,%d,%d", &m->data[i].i, &m->data[i].j, &m->data[i].v);
}
}
void OutputSPMatrix(SPMatrix *m)
{
int k = 0;
for (int i = 1; i <= m->row; i++)
{
for (int j = 1; j <= m->column; j++)
{
if (i == m->data[k].i && j == m->data[k].j)
{
printf("%d\t", m->data[k].v);
k++;
}
else
{
printf("%d\t", 0);
}
}
printf("\n");
}
}
//矩阵转置
void TransposeSPMatrix2(SPMatrix *m,SPMatrix *t)
{
t->row = m->column;
t->column = m->row;
t->t = m->t;
if (m->t)
{
int index = 0;
for (int i = 1; i <= m->column; i++)
{
for (int j = 0; j < m->t; j++)
{
if (i == m->data[j].j)
{
t->data[index].i = m->data[j].j;
t->data[index].j = m->data[j].i;
t->data[index].v = m->data[j].v;
index++;
}
}
}
}
}
//矩阵转置
void TransposeSPMatrix(SPMatrix *m)
{
SPMatrix t;
t.row = m->column;
t.column = m->row;
t.t = m->t;
if (m->t)
{
int index = 0;//新矩阵存入元素下标
for (int i = 1; i <= m->column; i++)//遍历原矩阵的列
{
for (int j = 0; j < m->t; j++)//遍历原矩阵中所有元素
{
if (i == m->data[j].j)//找到当前列中元素
{
t.data[index].i = m->data[j].j;
t.data[index].j = m->data[j].i;
t.data[index].v = m->data[j].v;
index++;
}
}
}
}
*m = t;
}
int main(void)
{
SPMatrix m;
CreateSPMatrix(&m);
OutputSPMatrix(&m);
printf("-------------------\n");
SPMatrix t;
/*TransposeSPMatrix2(&m,&t);
OutputSPMatrix(&t);*/
TransposeSPMatrix(&m);
OutputSPMatrix(&m);
}
参考:https://blog.csdn.net/songhui1024/article/details/49705843
https://blog.csdn.net/gaoxiangnumber1/article/details/44967763
https://www.cnblogs.com/Harley/p/5978868.html
https://blog.csdn.net/tiredoy/article/details/24435443
3.2稀疏矩阵压缩存储后失去随机存取功能

采用三元组存储后,要访问原矩阵中坐标为(i,j)的元素,需按顺序扫描三元组矩阵,判断i和j是否相等。
4.对称矩阵存储
对称矩阵只用存上三角矩阵或者下三角矩阵即可,原来需要存储n*n个元素,现在只需要n*(n+1)/2个存储单元,大约节约了一半的存储单元。
5.广义表表尾

解释:
(1)《数据结构》对广义表的表头和表尾是这样定义的:
如果广义表LS=(a1,a2...an)非空,则 a1是LS的表头,其余元素组成的表(a2,a3,..an)是称为LS的表尾。
根据定义,非空广义表的表头是一个元素,它可以是原子也可以是一个子表,而表尾则必定是子表。例如:LS=(a,b),表头为a,表尾是(b)而不是b.另外:LS=(a)的表头为a,表尾为空表().
(2)非空广义表,除表头外,其余元素构成的表称为表尾,所以非空广义表尾一定是个表
不管你愿不愿意,你都得给表尾加个括号()。所以一定是表,不能是原子。
6.具有记忆功能的数据结构
想象一下浏览网页:打开A网页,A入栈,从A中打开B网页,B入栈,从B中打开C网页,C入栈,然后点击浏览器左上角返回键,从C网页返回到B网页,就是C出栈,B变为栈顶。
7.能被2,3,5整除的数问题

这种题经常见到:
可以翻译为x个数中能被2整除的有x/2个,能被3整除的有x/3个,能被5整除的有x/5个,但这些数有重复的,求第1500个这样的数x是多少?
用了一个集合公式:AUBUC=A+B+C-AB-AC-BC=ABC
x/2+x/3+x/5-x/6-x/10-x/15+x/30=1500,解出来就可以了,但是这里是整除,不好解。解出来是2045。
伪:(22/30)x=1500
换种思路,找最小公倍数,
很明显,最小公倍数为30,[1,30]以内满足条件的数有22个,22怎么看了,就上上面等式通分后的分子,
1500/22=68,1500%68=4;就是说第1500个数经过了68个周期,然后取下一个周期中的第4个数。一个周期前4个数为2,3,4,5,
所以结果为30*68+5=2045。
反过来,它有时问2045个数内有多少个满足这样的数?
2045/30=68;2045%30=5
68*22+4=1500
8.合并两个已排序数组需要的最大比较次数
最坏的情况就是两个序列为交叉的时候,例如1,3,5,7,9;2,4,6,8,10。
思路:挖2n个坑,每次比较两个序列最大的数,将最大的数放入坑中,在进行下一次比较。
1,3,5,7,9
2,4,6,8,,10
第1次:
9和10比较,10入坑
第2次
9和8比较,9入坑
......
第9次
2入坑
共需要2n-1次。
9.对一维数组名取地址是int *[n]类型

&a的类型是数组指针int *[5],&a+1就指向了a最后一个元素的下一个元素,(int *)(&a+1)将int *[5]类型转换为了int *类型,所以*(p-1)就是a的最后一个元素9。
#include<stdio.h>
int main(void)
{
int a[5] = { 1,3,5,7,9 };
int *p = (int *)(&a + 1);
printf("%d, %d", *(a + 1) , *(p - 1));
}
10.char和int傻傻分不清楚
int main(void)
{
char a = 'A';
int b = 65;
char c = 65;
int d = 'A';
printf("%c %d\n", a, a);
printf("%c %d\n", b, b);
printf("%c %d\n", c, c);
printf("%c %d\n", d, d);
}
11.关联数组

关联数组就是Python中字典。
12.内外循环问题

一般情况下,我们把大循环放在里面,小循环放在里面,这样根据局部性原理,可以减少CPU跨循环的次数。
这题当中,如果改为同一个数自加,应该是pa比pb快。
而这题当中a[NUMA]太大了为1000万,可以会产生缺页情况(访问失败而重新分配地址),导致运行速度下降。
13.数组和链表对比

关于A选项,数组大约进行N/2次比较,链表要N次操作。
14.数组通常具有的两个基本操作

MDZZ,索引是来干扰你的。数组一般不进行插入和删除。
15.见多了就习惯了

16.见多了就习惯了

17.邻接表表示的深度优先搜索

使用的递归,用到了栈。
18.逻辑结构和物理结构区分
19.链队列删除操作

当队列中只有一个元素时,需要改变队尾指针。
20.链表反转

21.双循环链表
带尾节点的单循环链表方便在末尾插入节点,但是不方便删除尾节点。
22.队列与进程调度问题

以前看的操作系统搞忘记了,进程在内存中占3页,就是分配的空间是3页。内存中没有的就产生缺页,开始的1,2,3也缺页。
23.栈的应用
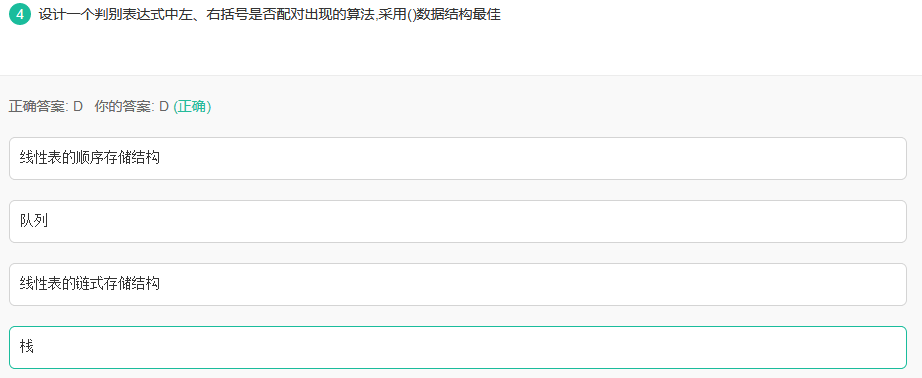
思路:([{入栈,}来了,判断栈顶是不是{,是出栈。。。
24.转义字符\ddd
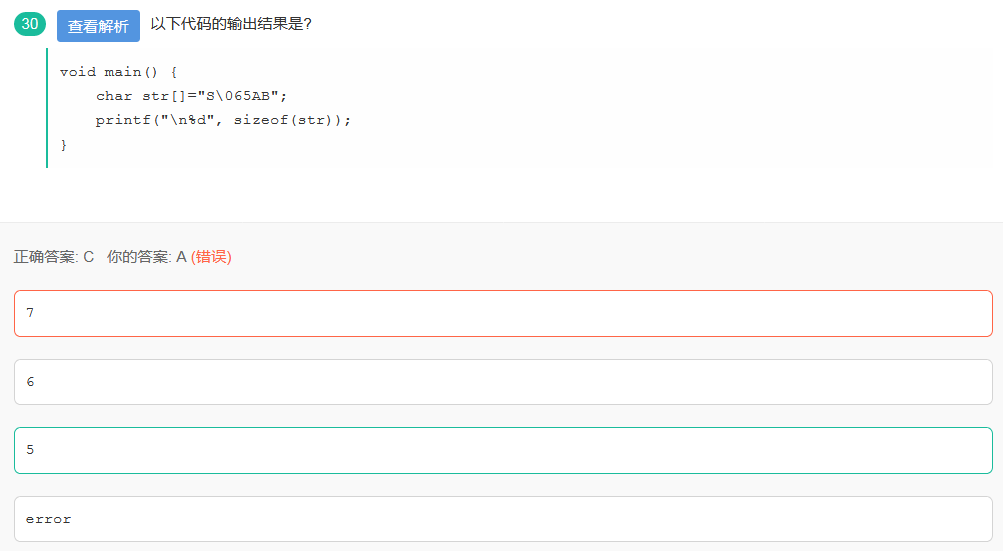
\ddd中 ddd对应 1~3位八进制数。所以\065就是一个字符,sizeof(str)=5,strlen(str)=4。
如果是16进制数,就是: \xhh
25B树

B树要求所有叶子节点都在同一层,而三路搜索树不要求
26栈的应用

栈的应用:
1、符号匹配;
2、表达式求值;
3、实现函数调用
27二叉排序树

二叉排序树的中序遍历一定是有序的。 直接选A
28完全二叉树共有700结点,该二叉树有多少个叶子结点?


29霍夫曼树
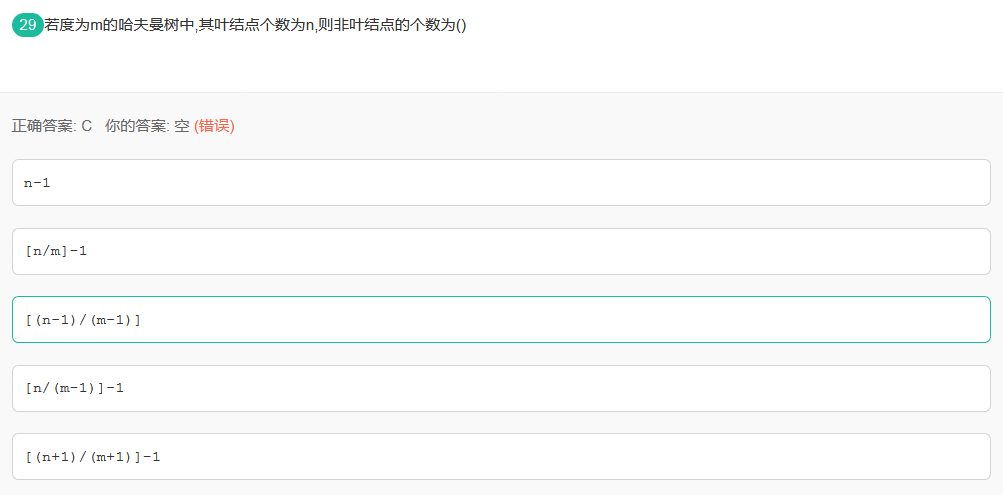
平时所说的霍夫曼树是指最优二叉树,也叫做严格二叉树,但是霍夫曼树不局限于二叉树,也存在于多叉树中,即度为m的霍夫曼树,也叫最优m叉树,严格m叉树。
霍夫曼树,每个节点的度要么为0(叶子节点),要么为m(分支节点)
本题中,设非叶节点树为x,所以有m*x+1=n+x,x=(n-1)/(m-1)。
30C语言本身没有输入输出语句

C语言本身并不提供输入输出语句,输入和输出操作都是有函数实现的。
也就是说printf和scanf并不是C语言的关键字,而只是函数的名字,他们不是C语言文本中的组成成分。
31sizeof(void)
32宏
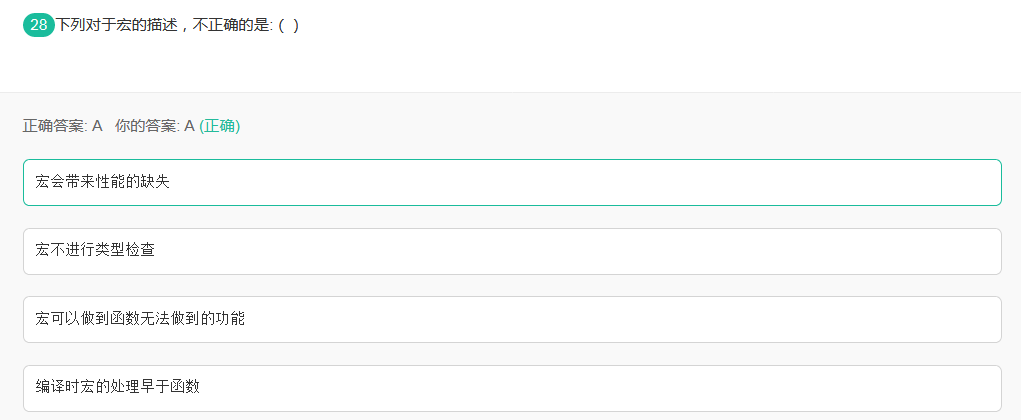
不管A选型,记住B选型,宏不进行类型检查。
#define i="k" 1
33.符号常量
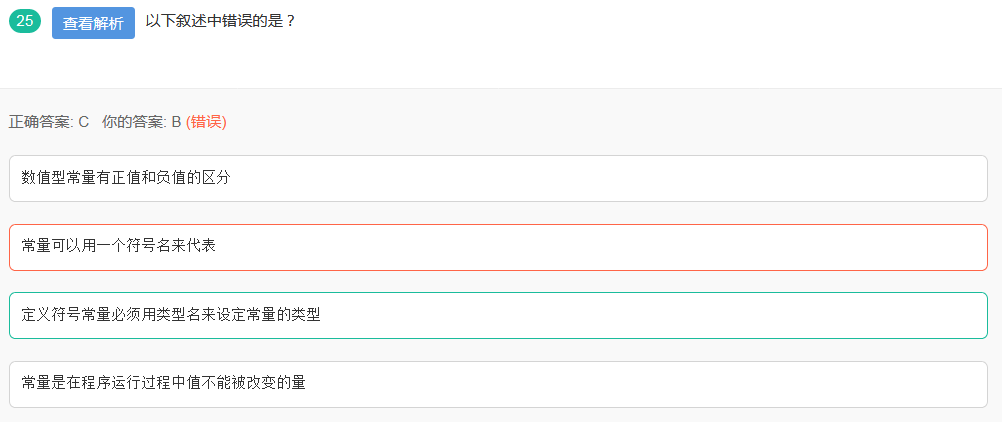
以前只集的const定义的是符号常量,今天做到这个题目,百度了一下,发现#define定义的也是符号常量。
符号常量:
1.#define N 10
2.const int a = 10;
33.枚举
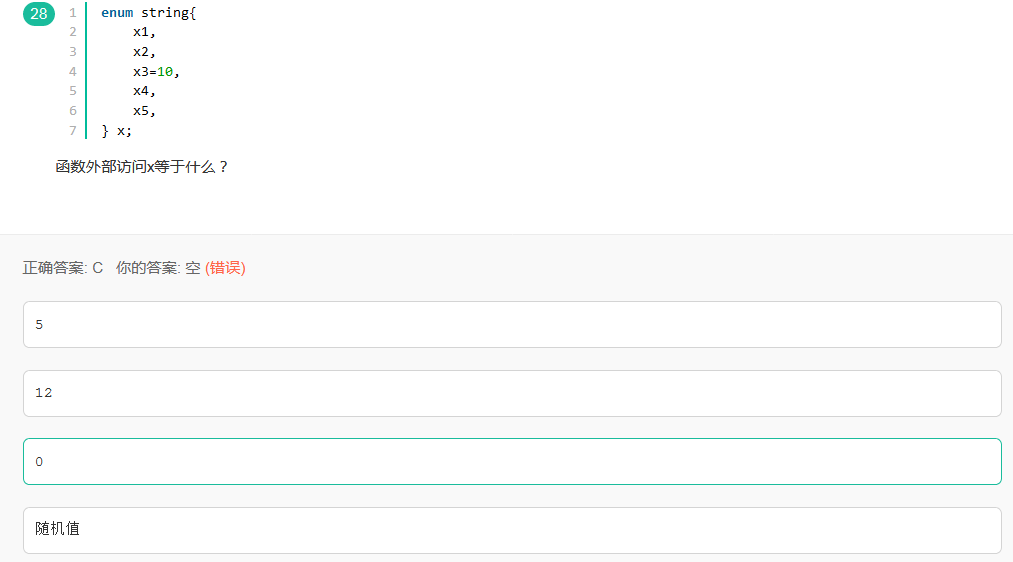
C++中为0
#include<stdio.h>
enum string{x1,x2,x3=10,x4,x5};
void main()
{
printf("%d %d %d %d %d\n", x1, x2, x3, x4, x5);//0,1,10,11,12
}C语言定义全局变量,还不能像下面这样定义int b = a;会报错。 C++中可以。
#include<stdio.h>
enum string{x1,x2,x3=10,x4,x5};
int a = 5;
int b = a;
void main()
{
printf("%d %d %d %d %d\n", x1, x2, x3, x4, x5);
}34.下面哪个语句无法通过编译?
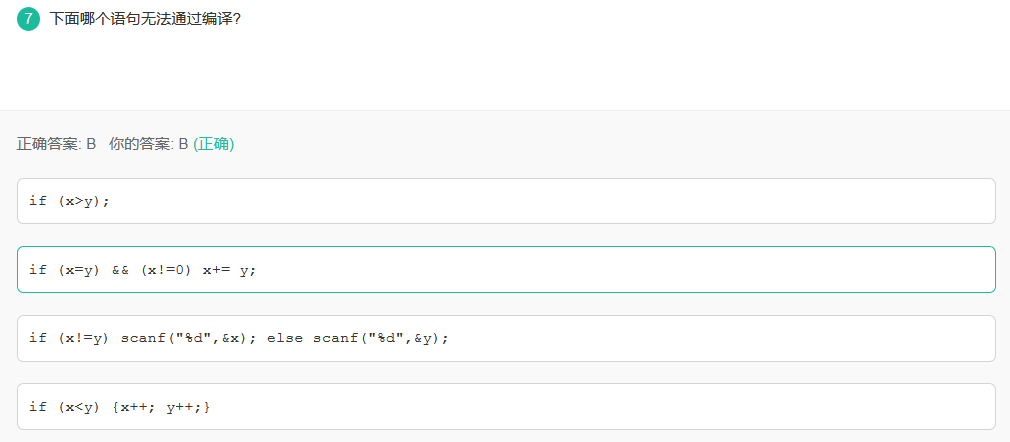
当时做这个看了好一会,后来看网友解释,才发现,B选型错在这里:应该是if((x=y)&&(x!=0)) x+=y;
35.设顺序表的长度为n。下列算法中,最坏情况下比较次数小于n的是()。

关于A选项, 直接先假设第一个是最大项,然后和后面的每个数据比较,就是n-1呀。
36八进制
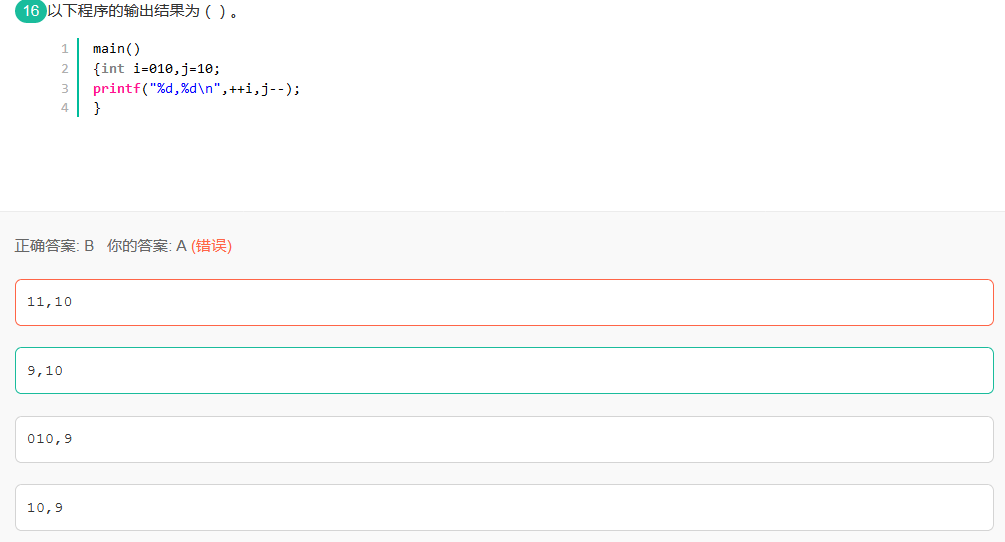
0开头的是八进制。
37无符号整型
#include<stdio.h>
int main()
{
unsigned short i = -1;
printf("%d\n", i);//65535
}38
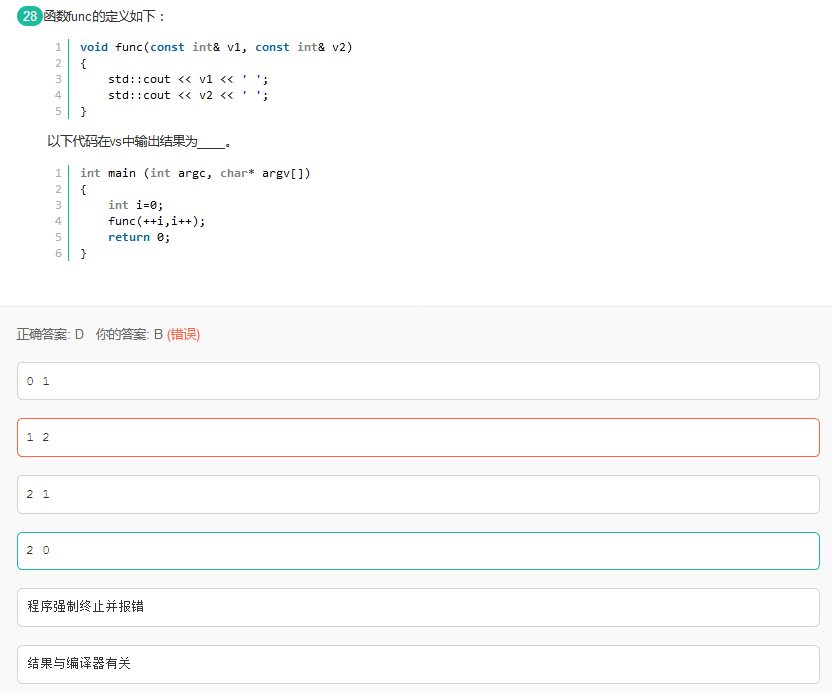
未定义行为: 函数各参数的求值顺序
例如: printf("%d,%d\n",++n,power(2,n)); //错误
在不同的编译器可能产生不同的结果,这取决于n的自增运算和power调用谁在前谁在后。
39.二叉排序树性质


左子树上所有的值都小于该节点的值,右子树上所有的值都大于该节点的值。
40.具有八个结点的二叉树共有多少种()?
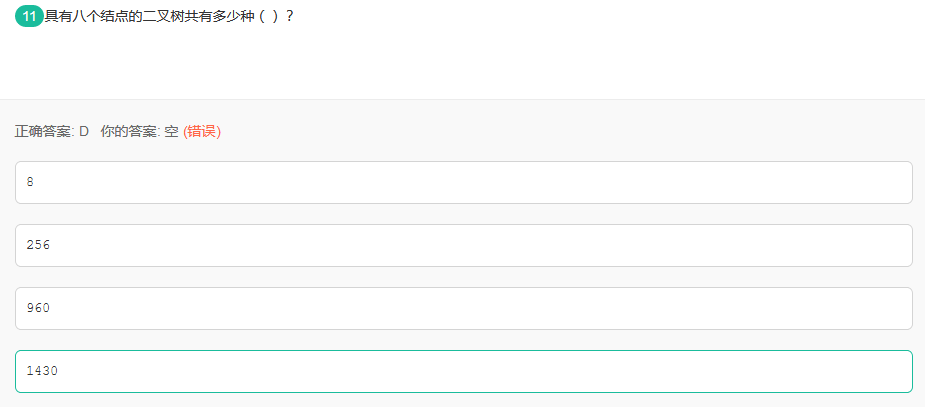
卡特兰数:

41.二叉树转换为森林



42. 已知int i=1, j=2;,则表达式i+++j的值为( )。
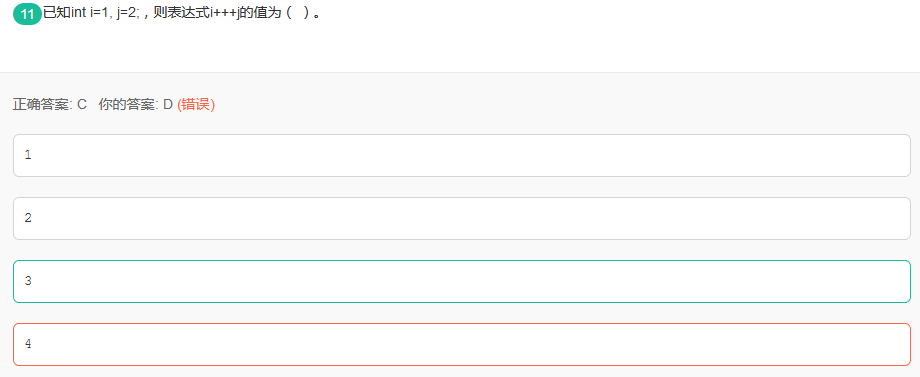
这是因为C/C++编译器在对程序编译时,会从左到右尽可能多的将字符组合成一个运算符或标识符
43语句 while(!E);中的表达式!E 等价于()。

这题稍不注意就容易做错,哈哈。
44scanf
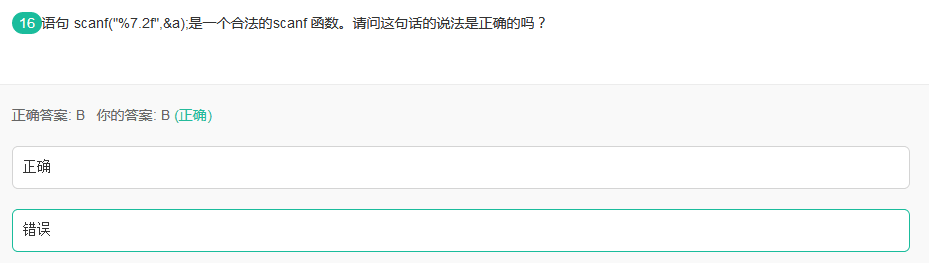
scanf不能指定输入精度,可以指定长度。
比如%m.nf是不允许的,但是可以%mf。m为整数。
45
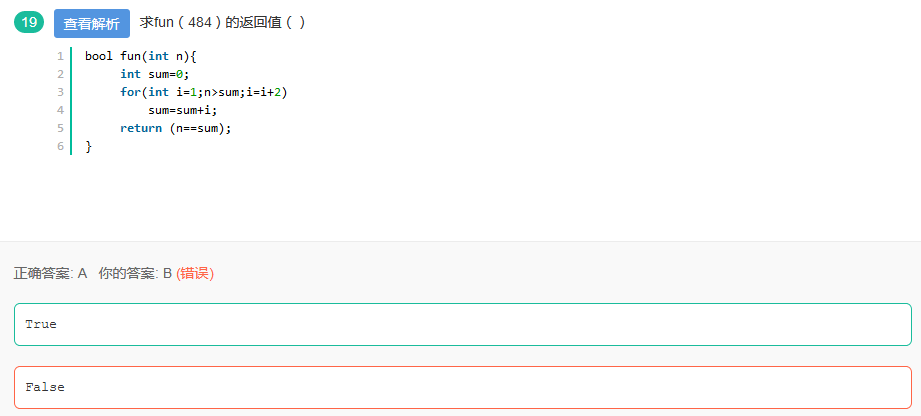
这题有点意思,京东的笔试题。
46

这题都做错,以前的东西真是忘得差不多了。
47贪心算法
贪心算法:在对问题求解时,每次都做出在当前看来是最好的选择,不是从整体上考虑。它是通过局部最优来达到全局最优,不保证全局最优。
K算法和P算法都是贪心算法,D算法也是,KMP,F算法不是。

48m叉树问题
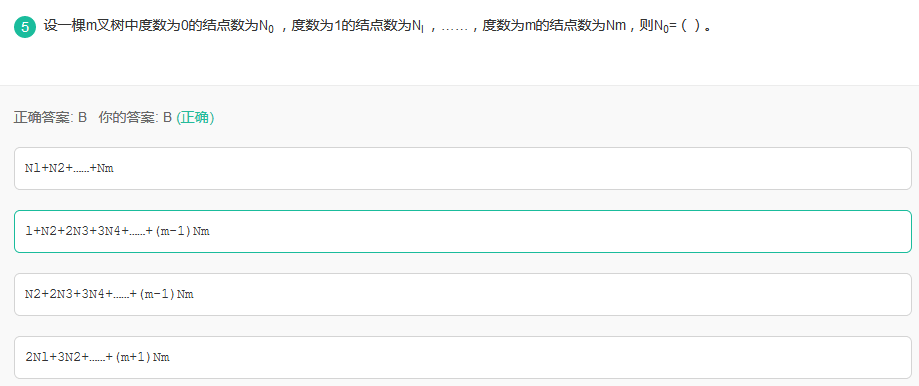
简单:N0+N1+N2+..+Nm = N1+2N2+..+mNm+1
49完全二叉树
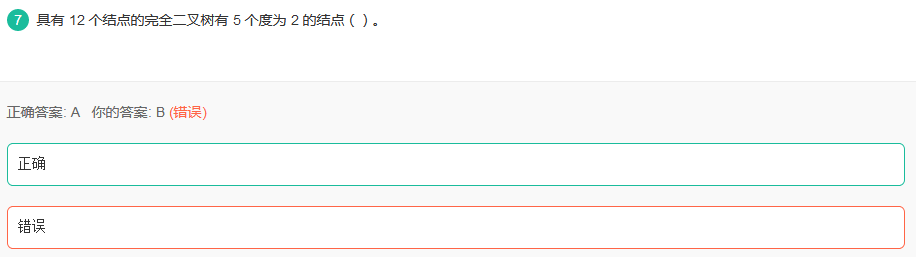
最后一个非分支节点为12/2=6,分直节点个数12-6=6,2度节点个数6-1=5。
50前序遍历和后序遍历相反
