转载自:https://blog.csdn.net/yiyelanxin/article/details/72801005
在查询数据时如果有重复,我们都知道可以用distinct去重,但使用distinct只能去除所有查询列都相同的记录,如果有一个字段不同,distinct是无法去重的,但我们还想要实现这样的效果,这时我们可以用partition by。
1.使用ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2)先进行分组。(根据COLUMN1分组,在分组内部根据COLUMN2排序,结果就表示每组内部排序后的顺序编号,这个编辑在组内是连续且唯一的)
查询语句如下:
select a.CompanyID,a.UserName,a.AddTime,a.JF,
ROW_NUMBER() over(partition by a.CompanyID order by b.ID) as new_index FROM dbo.LB_Company a
left join dbo.LB_Certificate b on a.CompanyID = b.CompanyID where a.CompanyID in (361,414,447)
- 1
- 2
- 3
查询结果如下:
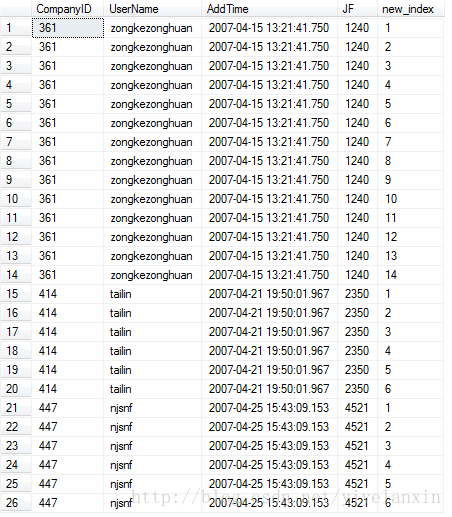
2.将上述结果作为一个表,外嵌查询select,使用条件new_index=1就可以查询出第个分组的第一条数据,从而达到去重的目的。
sql语句如下:
select * from(select a.CompanyID,a.UserName,a.AddTime,a.JF,
ROW_NUMBER() over(partition by a.CompanyID order by b.ID) as new_index FROM dbo.LB_Company a
left join dbo.LB_Certificate b on a.CompanyID = b.CompanyID where a.CompanyID in (361,414,447)
) t where t.new_index=1
- 1
- 2
- 3
- 4
查询结果如下:
