版权声明:派森学python,欢迎加群:923414804与博主一起学习 https://blog.csdn.net/weixin_44369414/article/details/86551455
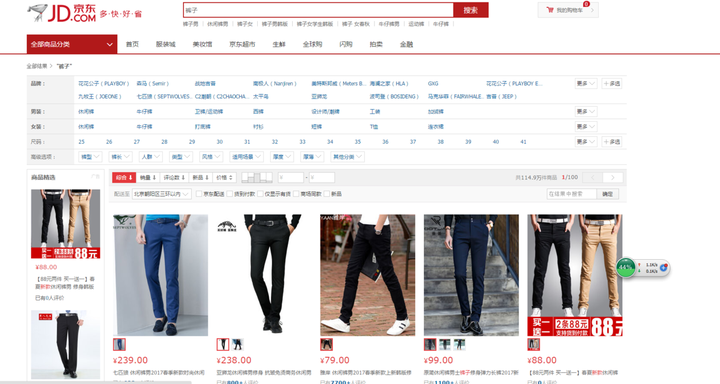
先说下这个网站,首先在首页随便输入一个想爬取的商品类别,观察到一般商品数目都是100页的,除非有些比较稀少的商品,如图
小编整理一套Python资料,有需要Python学习资料可以加学习群:923414804 ,在这寒冷的冬天,泡一壶热茶,看书学习,岂不快哉。
介 绍一下网站的分析过程,默认情况下在首页输入一件商品时,出来的搜索页面是只有30件商品的,屏幕的右侧下拉框拉到下面会触发一个ajax的请求,把剩下 的30个商品渲染出来,一般每页60个商品里面是有三个左右是广告的,也就是有效商品一般是57个。这里看一下这个AJAX请求,这个是爬取难点
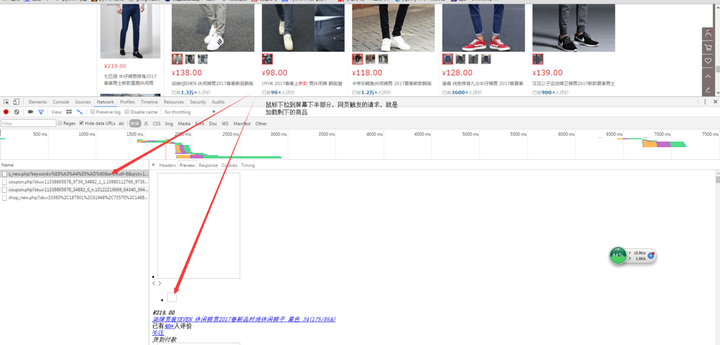
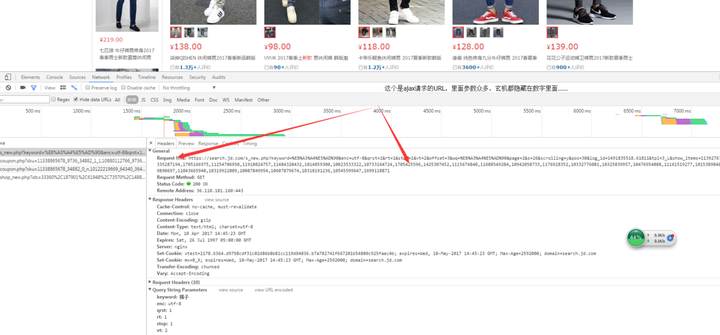
看一看这个请求头,我当时第一个感觉以为很多参数是可以去掉,拿到一个很简便的链接就可以了
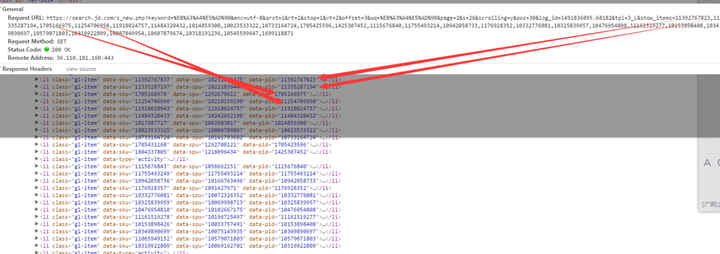
当 时没注意,删了很多参数直接请求,结果调试了很久,获得的商品在插进数据库去重的时候都是只剩网页的一般,细细观察了一下发现链接虽然不同,请求回来的商 品却是一样的,然后我再细细看了看这个ajax请求,鼓捣了好久,最终发现这个URL后面的每个数字都是每一件商品的ID,而这个ID隐藏在第一次刚打开 网页时候最初的那些商品里面,如图.........
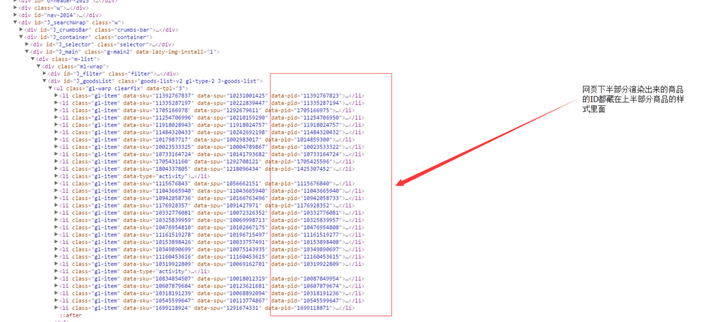
这里结合ajax请求的参数看,
扫描二维码关注公众号,回复:
4985849 查看本文章

然后我又从新改掉爬虫逻辑,改代码,又花了两个小时,好惨啊.......
然后终于可以一次提取完整的网页商品了,最后提示一下,京东网页第一页的商品里面页数page是显示1和2的,第二页是3和4,这个有点特殊,最后上一张爬虫主程序图
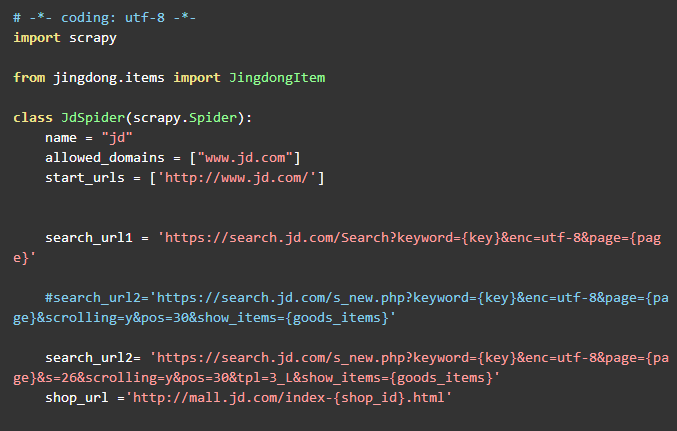
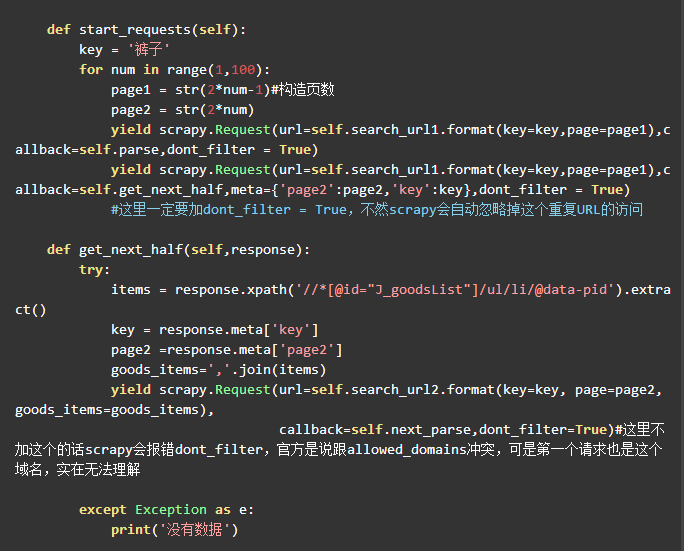
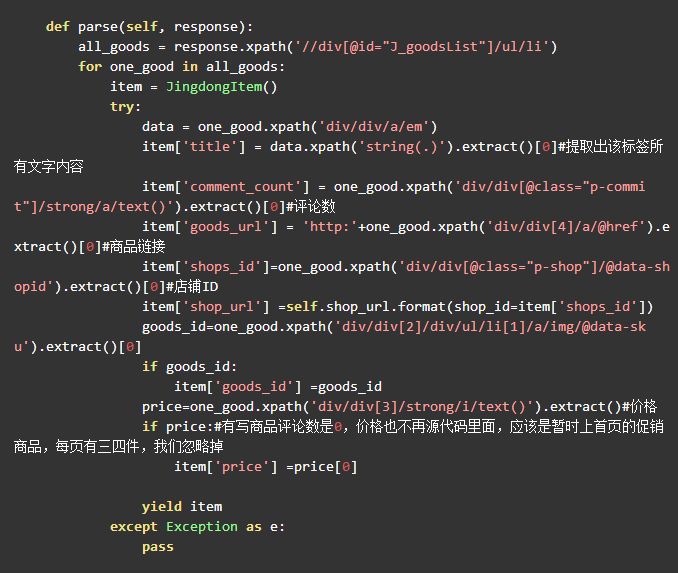

运行结果如图
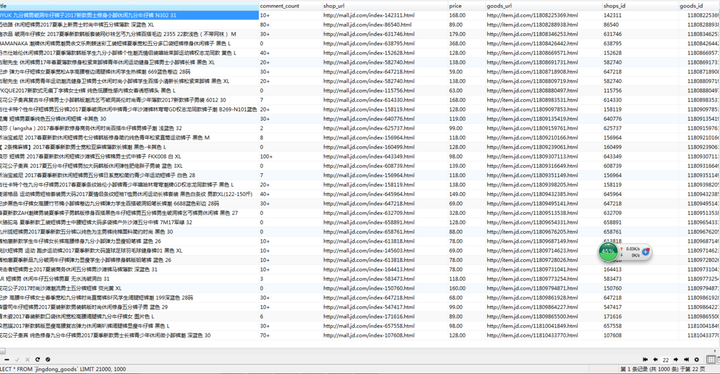
运行了几分钟,每页一千条,共爬了几万条裤子,京东的裤子真是多