第一个人工智能小程序:找金币
一、小程序概述
该小程序用于演示强化学习中基于模型的动态规划方法。程序运行界面包括:网格、金币、陷阱、小人。其中网格是基础环境,随机在某个网格中放置一枚金币,在某些网格中设置陷阱(网格红色表示有陷阱),经过强化学习后,放置小人到非陷阱网格中,小人会避开陷阱去寻找到金币。
无陷阱网格小人找金币游戏示意图:
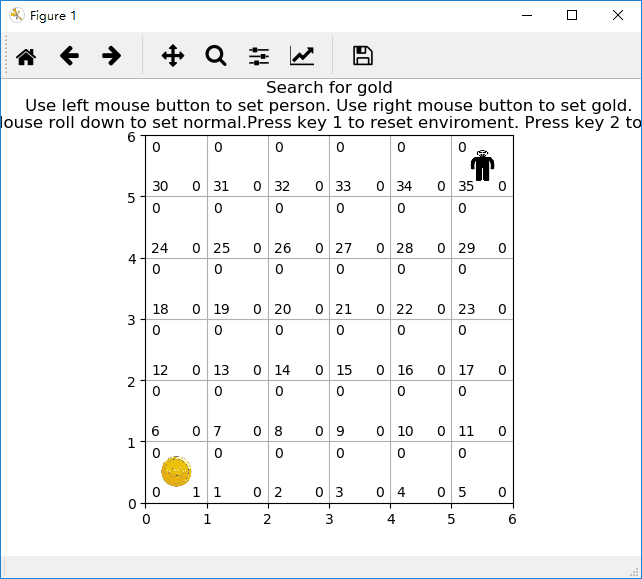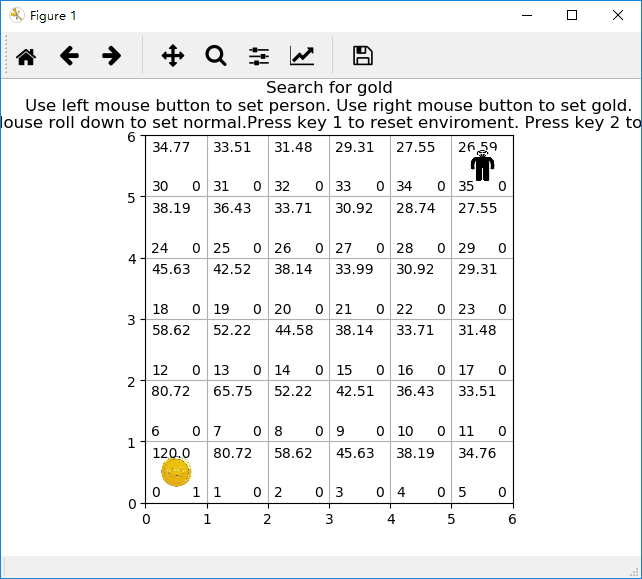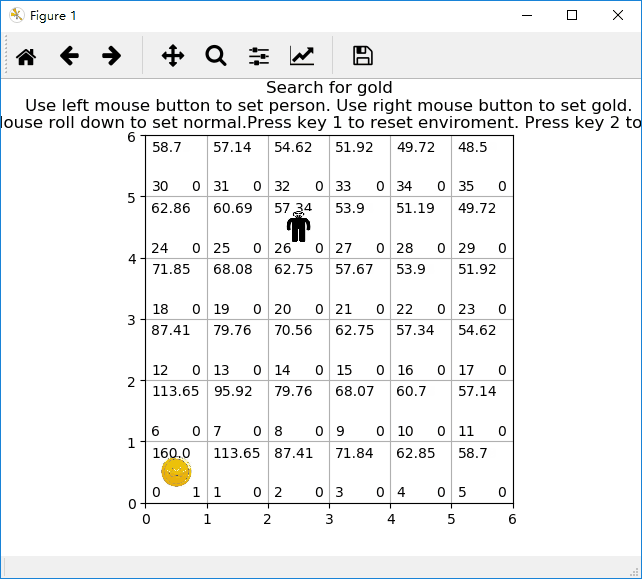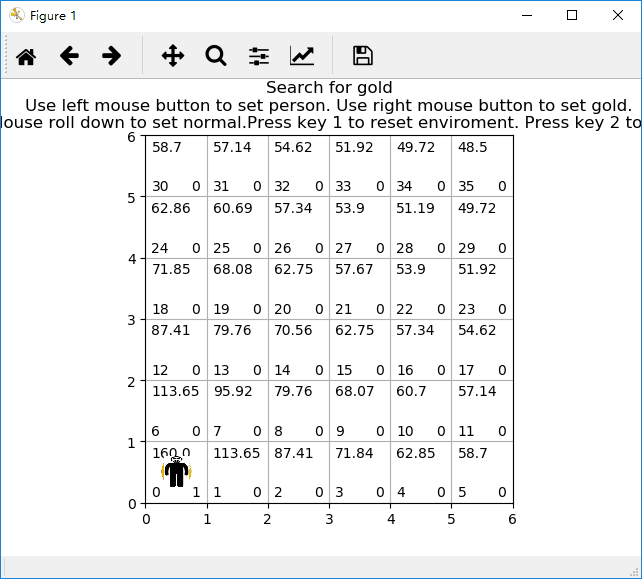
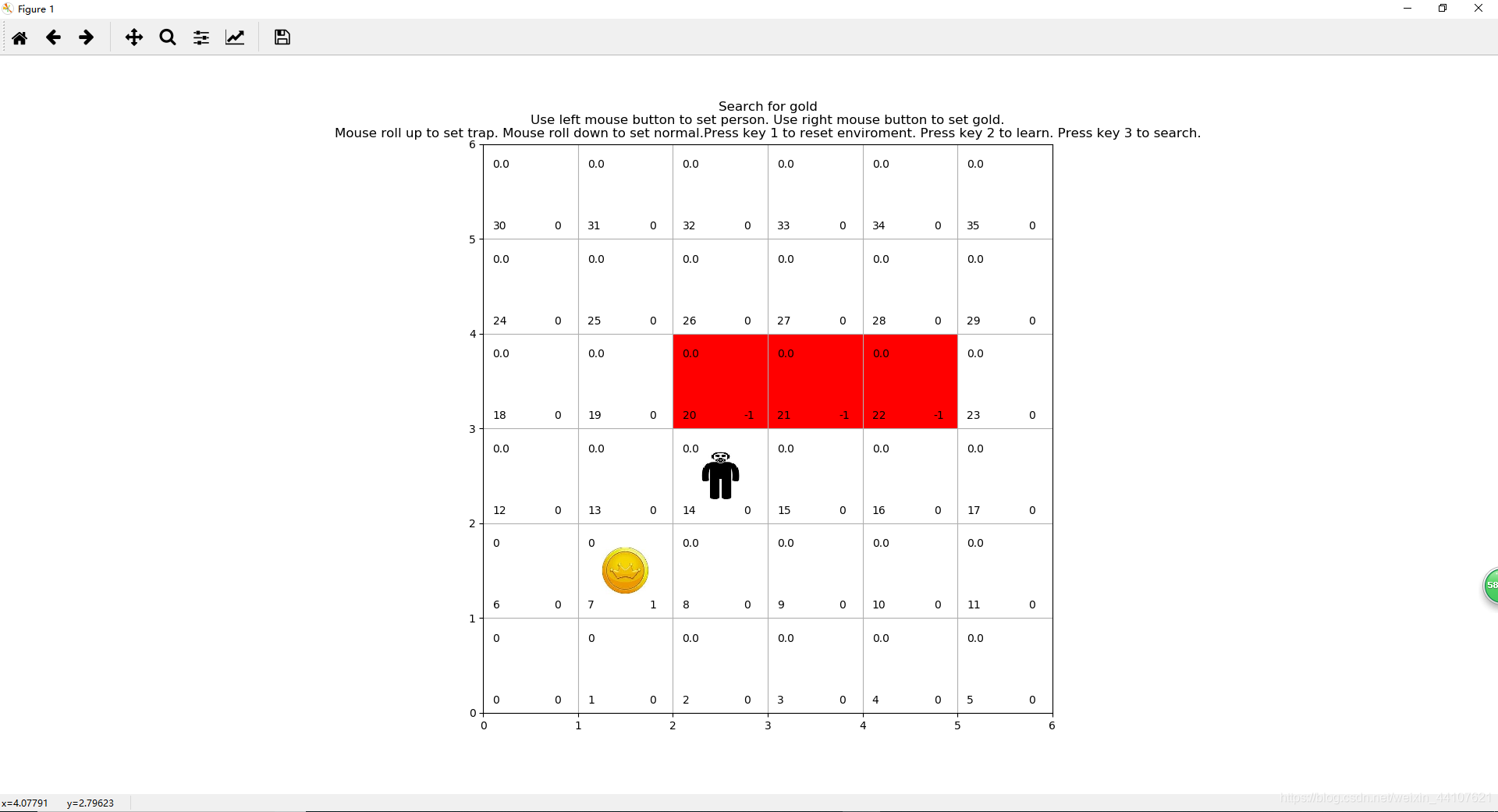
有陷阱网格小人找金币游戏示意图:
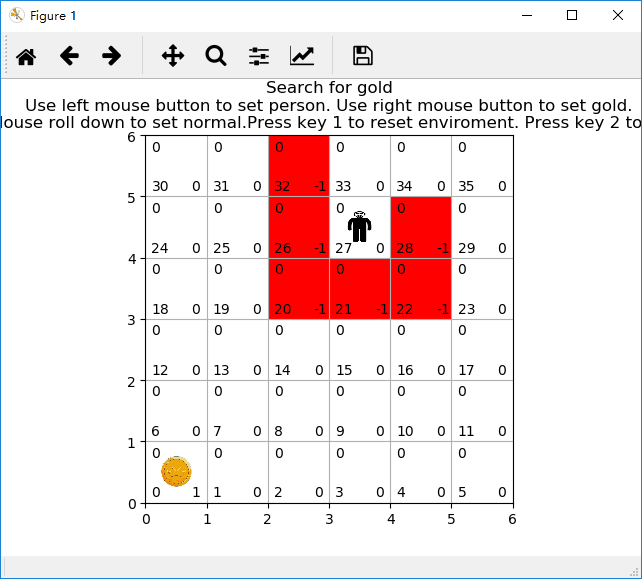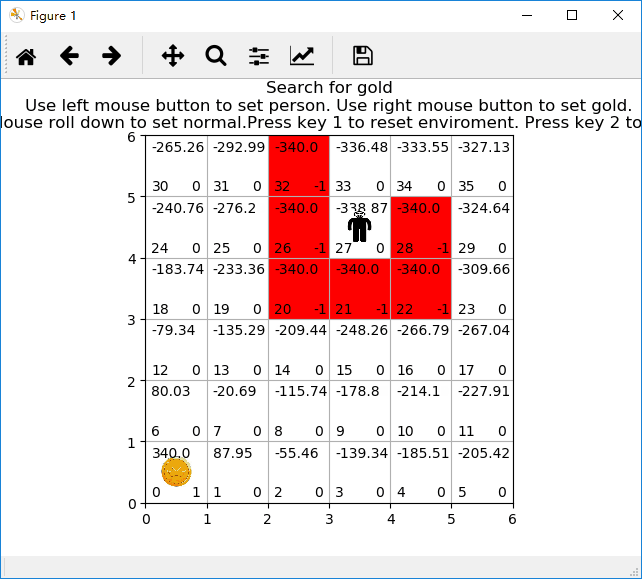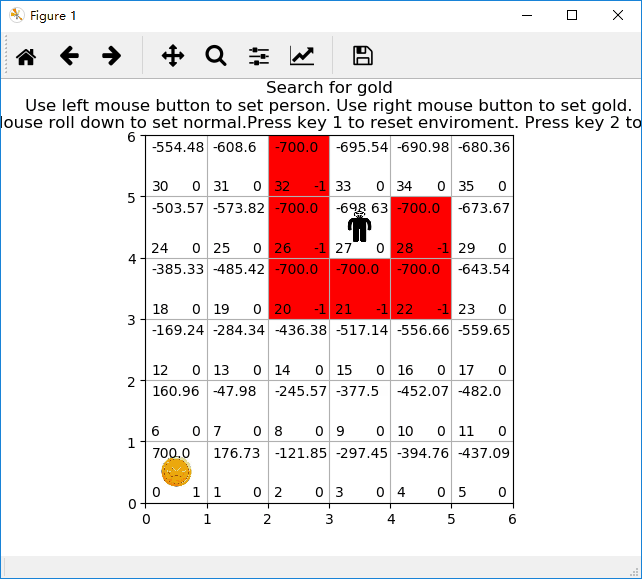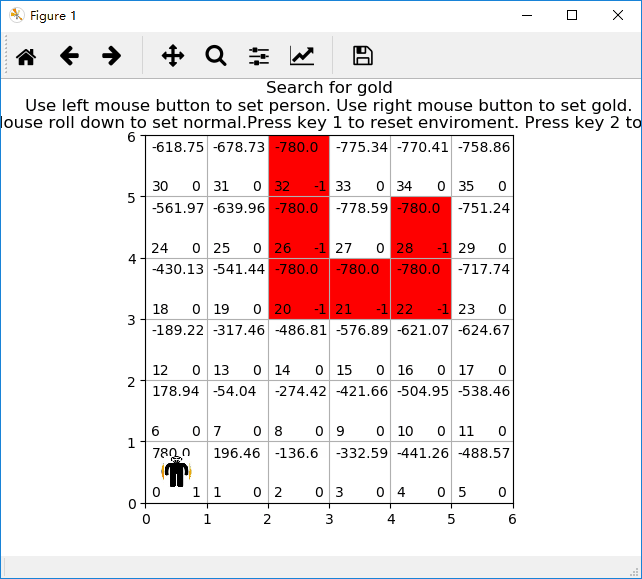
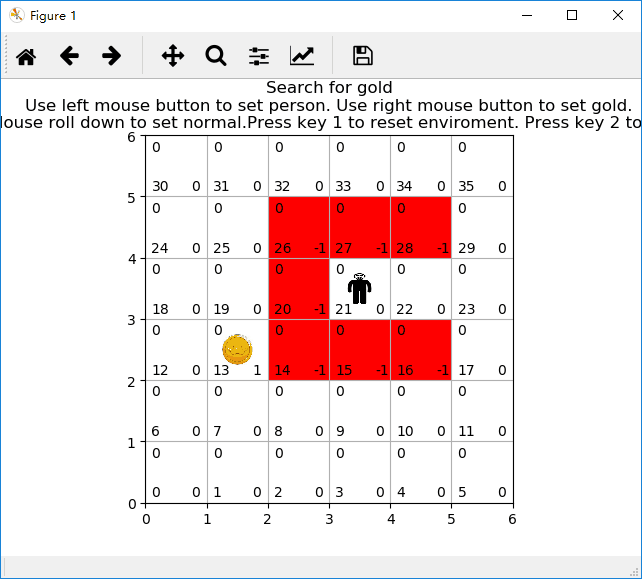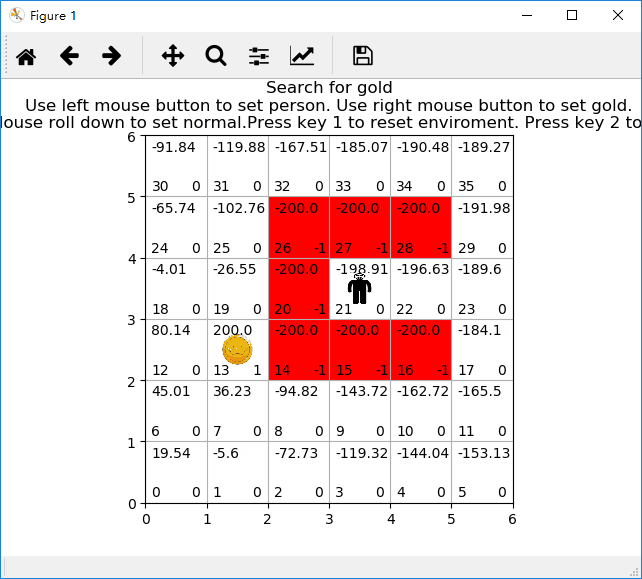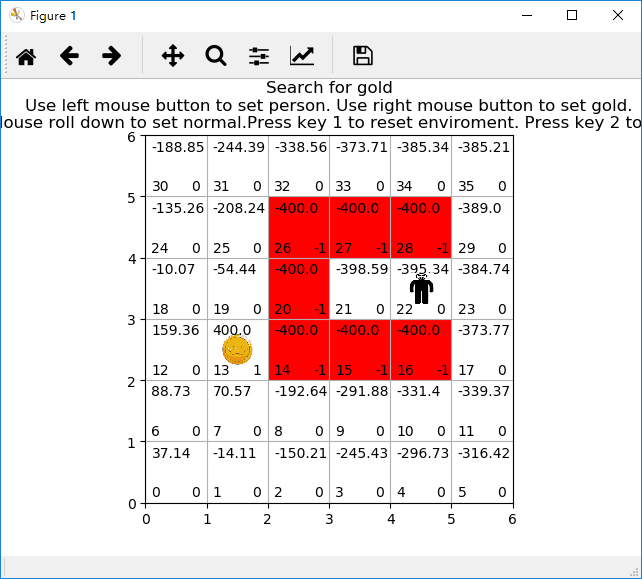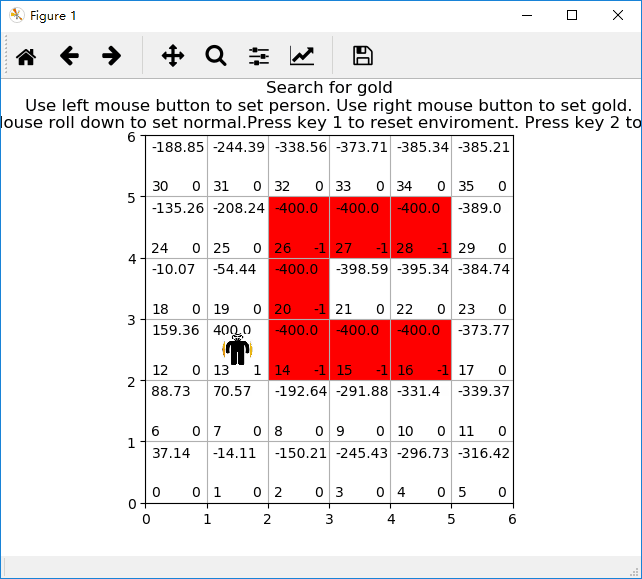
二、写程序
由于刚开始学习python,代码写得比较low,见笑了。
1. 启动开发环境和软件
运行Anaconda Navigator程序,点击【home】,选定我们上次安装的运行环境【hdrai】,运行【spyder】。(运行环境创建安装方法见“人工智能运行开发环境搭建”)

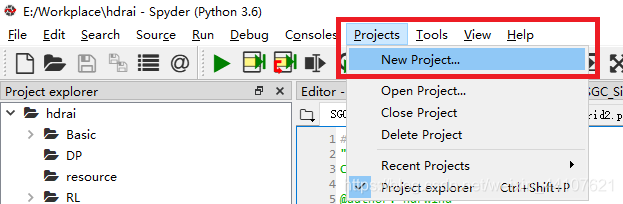
2. 新建工程
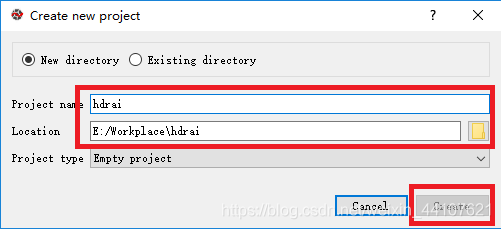
依次点击【Projects】-【New Project】,弹出新建工程界面,输入工程名称(这里我们建的工程名称为“hdrai”),选择工程所在父目录,点击【Create】完成创建(这里因为我们已经创建过hdrai了,所以Create按钮是灰色的)。
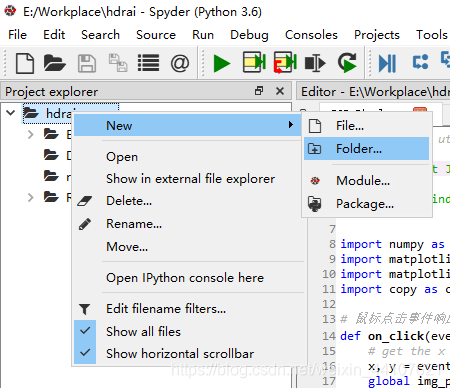
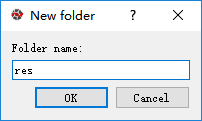
鼠标右键点击目录【hdrai】,依次选择【New】–【Folder】,新建一个子目录【res】。
将下面两幅图另存为goldcoin.png和person.png,放到上面新建的res目录下。


3. 写代码
点击【New file】,复制下面代码到新文件中,保存文件到与res目录同级目录中,设定文件名(这里我设定文件名为SGC_Simple.py)。
import numpy as np
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import copy as cp
# 鼠标点击事件响应函数
def on_click(event):
# get the x and y coords, flip y from top to bottom
x, y = event.x, event.y
global img_person, img_gold, startstate, goldposition, count, pi
if event.inaxes is not None:
x = int(event.xdata)
y = int(event.ydata)
if event.button == 1: # 鼠标左键
img_person.set_extent((x+0.3,x+0.7,y+0.25,y+0.75))
startstate[0] = x
startstate[1] = y
print(startstate)
if event.button == 3: # 鼠标右键单击
img_gold.set_extent((x+0.25,x+0.75,y+0.25,y+0.75))
update_rewards(goldposition[0], goldposition[1], 0)
update_values(goldposition[0], goldposition[1], 0)
update_rewards(x, y, 1)
goldposition[0] = x
goldposition[1] = y
print(goldposition)
plt.draw()
# 'scroll_event'事件响应函数
def on_scroll(event):
global count
if event.inaxes is not None:
global rewards
x = int(event.xdata)
y = int(event.ydata)
if event.button == 'up': # 鼠标滚轮上滚
plt.fill([x,x,x+1,x+1],[y,y+1,y+1,y], 'r')
update_rewards(x, y, -1)
if event.button == 'down': # 鼠标滚轮下滚
plt.fill([x,x,x+1,x+1],[y,y+1,y+1,y], 'w')
update_rewards(x, y, 0)
plt.draw()
print(rewards)
# 键盘事件响应函数
def on_press(event):
if event.key == '1':
print('重置')
reset_values()
if event.key == '2':
print('开始训练')
start_learning()
if event.key == '3':
print('开始寻找金币')
start_search()
# 设置网格状态标识文字
def set_text_state():
offset = 0.1 # 文字位置偏移量
global count
for i in range(count):
for j in range(count):
plt.text(j+offset, i+offset, str(i*count+j),fontsize=10)
# 更新值函数,并更新显示
def update_values(x, y, value):
global values,values_text
values[x][y] = value
values_text[x][y].set_text(str(value))
# 更新回报,并更新显示
def update_rewards(x, y, reward):
global rewards, rewards_text, pi, count
rewards[x][y] = reward
rewards_text[x][y].set_text(str(reward))
# 开始训练
def start_learning():
global values, count, pi, rewards, pi_adv
# 开始策略评估k次
k = 20 # 迭代次数
for i in range(k):
vtmp = cp.deepcopy(values) # 深拷贝当前值函数到一个临时对象
for y in range(count):
for x in range(count):
# 获取'left','right','up','down'四个动作后对应的状态变化
l = x - 1
r = x + 1
u = y + 1
d = y -1
if l < 0: l = 0
if r >= count: r = count - 1
if d < 0: d = 0
if u >= count: u = count - 1
# 如果是放金币或陷阱的格子,则动作后保持原地不动
reward = rewards[x][y]
if reward == 1 or reward == -1:
l = x
r = x
u = y
d = y
# 获取当前状态对应的策略,计算值函数
p = pi[(x,y)]
v = (p[0]*(rewards[l][y] + vtmp[l][y])
+ p[1]*(rewards[r][y] + vtmp[r][y])
+ p[2]*(rewards[x][u] + vtmp[x][u])
+ p[3]*(rewards[x][d] + vtmp[x][d]))
v = round(v, 2) # 保留2位小数
update_values(x, y, v)
plt.draw()
# 策略改善
pi_adv = cp.copy(pi)
for y in range(count):
for x in range(count):
# 如果是放金币或陷阱的格子,则动作后保持原地不动
reward = rewards[x][y]
if reward == 1 or reward == -1: continue
# 比较'left','right','up','down'四个动作后对应的值函数大小
l = x - 1
r = x + 1
u = y + 1
d = y - 1
if l < 0: l = 0
if r >= count: r = count - 1
if d < 0: d = 0
if u >= count: u = count - 1
ar = [values[l][y], values[r][y], values[x][u], values[x][d]]
po = np.where(ar == np.max(ar))
pi_adv[(x,y)] = [0.0 for i in range(4)]
if po[0][0] == 0: pi_adv[(x,y)][0] = 1.0
if po[0][0] == 1: pi_adv[(x,y)][1] = 1.0
if po[0][0] == 2: pi_adv[(x,y)][2] = 1.0
if po[0][0] == 3: pi_adv[(x,y)][3] = 1.0
# 开始寻找金币,采用贪婪策略
def start_search():
global startstate, count, goldposition, pi_adv, img_person
re = 0
while startstate[0] != goldposition[0] or startstate[1] != goldposition[1]:
re = re + 1
if re > 100: break
ss = pi_adv[(startstate[0],startstate[1])]
action = np.where(ss == np.max(ss))
print(pi_adv[(startstate[0],startstate[1])])
if action[0][0] == 0:
startstate[0] = startstate[0] - 1
if action[0][0] == 1:
startstate[0] = startstate[0] + 1
if action[0][0] == 2:
startstate[1] = startstate[1] + 1
if action[0][0] == 3:
startstate[1] = startstate[1] - 1
img_person.set_extent((startstate[0]+0.3,startstate[0]+0.7,startstate[1]+0.25,startstate[1]+0.75))
print(re, action[0], startstate)
plt.draw()
plt.pause(0.3)
# 重置值函数和回报
def reset_values():
global count, goldposition
for y in range(count):
for x in range(count):
plt.fill([x,x,x+1,x+1],[y,y+1,y+1,y], 'w')
update_rewards(x, y, 0)
update_values(x, y, 0)
update_rewards(goldposition[0], goldposition[1], 1)
plt.draw()
# 设置count值,用于构建count*count大小的网格
count = 6
# 设置状态空间,标识号显示在网格的左下角
states = [[j*count + i for i in range(count)] for j in range(count)]
# 设置回报
rewards = [[0 for i in range(count)] for j in range(count)]
rewards_text = [[0 for i in range(count)] for j in range(count)]
# 设置值函数,大小显示在网格的左上角
values = [[0.0 for i in range(count)] for j in range(count)]
values_text = [[0 for i in range(count)] for j in range(count)]
# 设置初始策略和改善的策略
pi = dict()
pi_adv = dict()
# 给值函数和策略赋初值
for j in range(count): # 纵坐标
for i in range(count): # 横坐标
vt = plt.text(i+0.1, j+0.75, str(values[i][j]),fontsize=10)
values_text[i][j] = vt
rt = plt.text(i+0.75, j+0.1, str(rewards[i][j]),fontsize=10)
rewards_text[i][j] = rt
pi[i,j] = [0.25 for ii in range(4)]
print(states)
print(rewards)
print(pi[(1,2)])
# 设置动作空间
actions = ['left','right','up','down']
# 挖金小人初始位置
startstate = [0,1]
# 金币位置
goldposition = [0,0]
update_rewards(goldposition[0], goldposition[1], 1)
# 金币图像全局变量
img_gold = mpimg.imread(r'res/goldcoin.png') # 读取金币图片
img_gold = plt.imshow(img_gold,extent=(0.25,0.75,0.25,0.75)) # 放置金币图片
img_gold.set_zorder(1) # 设置图像叠加顺序
# 小人图像全局变量
img_person = mpimg.imread(r'res/person.png') # 读取小人图片
img_person = plt.imshow(img_person, extent=(1+0.3,1+0.7,0.25,0.75)) # 放置到初始位置
img_person.set_zorder(99) # 设置图像叠加顺序
# 开始画图
plt.xlim(0,count) #设置x轴
plt.ylim(0,count) #设置y轴
title = ('Search for gold\n'
+ 'Use left mouse button to set person. '
+ 'Use right mouse button to set gold.\n'
+ 'Mouse roll up to set trap. '
+ 'Mouse roll down to set normal.'
+ 'Press key 1 to reset enviroment. '
+ 'Press key 2 to learn. '
+ 'Press key 3 to search.'
)
plt.title(title) # 设置标题
set_text_state() # 在网格左下角显示状态标识号
plt.grid() # 画网格线
plt.show() # 显示图
plt.connect('button_press_event', on_click) # 鼠标左键事件
plt.connect('scroll_event', on_scroll) # 鼠标滚轮事件
plt.connect('key_press_event', on_press) # 键盘事件
4. 运行程序
点击【Run file】运行程序。
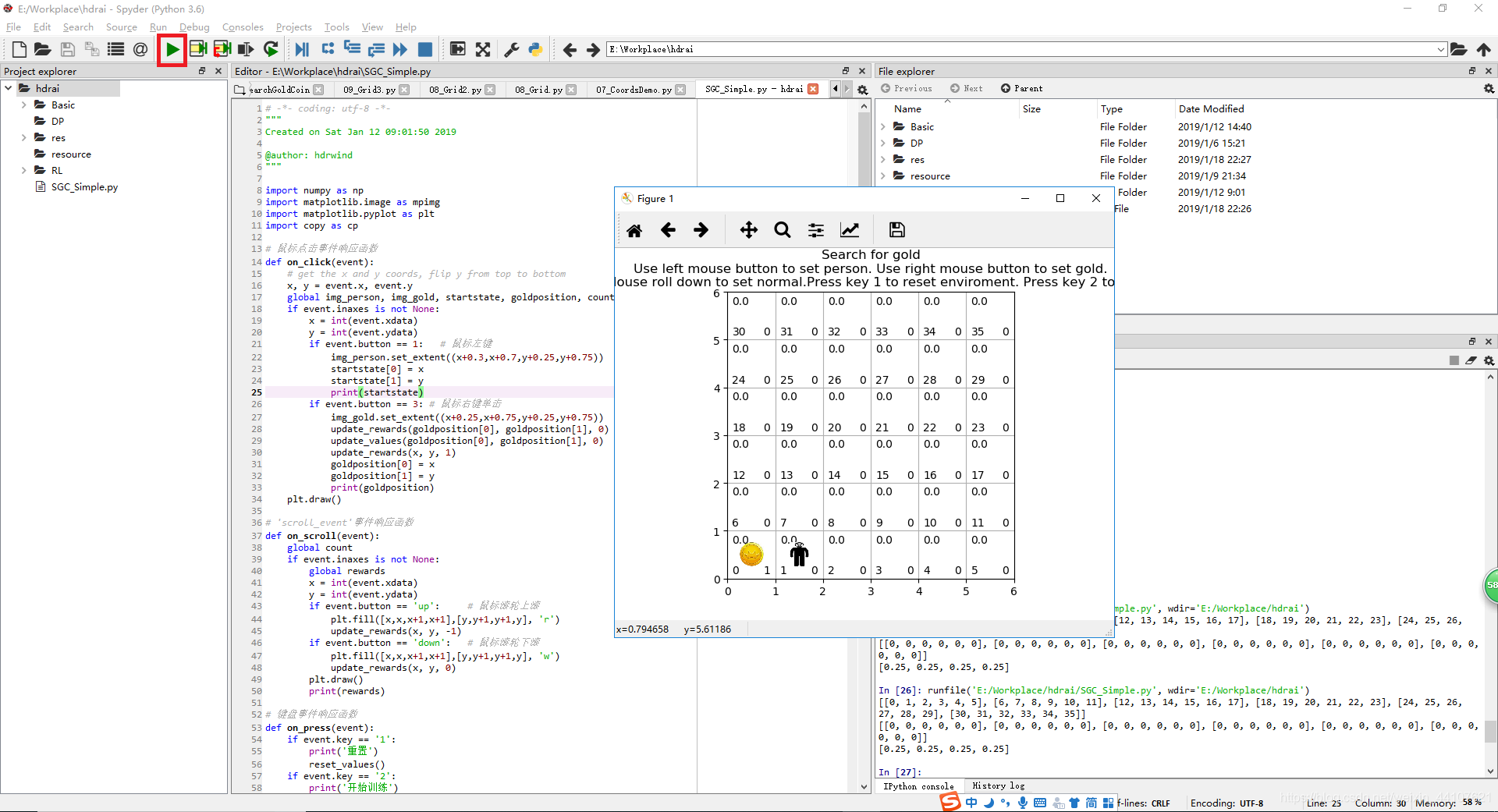
三、玩小游戏
该小游戏操作包括:
- 鼠标左键——设定小人的位置
- 鼠标右键——设定金币的位置
- 向上滚动鼠标滚轮——在鼠标当前位置网格放置陷阱
- 向下滚动鼠标滚轮——取消鼠标当前位置网格的陷阱
- 键盘1——重置所有环境
- 键盘2——开始强化学习,可多次按2来增加学习次数
- 键盘3——小人开始寻找金币
四、后记
第一次用python写程序,用了很长时间去学习matplotlib和numpy等组件。这个小程序属于强化学习的入门程序,只是对“基于模型的动态规划”的一个具体实现,还未涉及到gym和tensorflow等组件的应用。