漫威还是DC?
超人或者蝙蝠侠?
火影忍者亦或死神?
当然,所有这些讲的都是漫画!!!
当我们还是孩子的时候,总是迷恋漫画书,当翻到我们的英雄们开始行动时会激动不已。
大家总是争论谁是最厉害的超级英雄,认真地讨论他们的家族历史,或者梦想自己拯救高谭市。我们很多人用自己的童年创造了这样的难忘时刻。
时光流逝,但是仍然有人在寻找更多的漫画。
在这个数字时代,易用且超高速的互联网连接让人们可以不停地阅读/下载最喜欢的漫画书。然而每当我们尝试在手机上阅读漫画的时候,为了阅读上面的内容而锁定每一个分镜是个麻烦事。
每当你这样做的时候,是不是很渴望有把文本自动截取下来的超能力,以便漫画更清晰同时可以舒缓眼睛?
更多干货分享加python编程语言学习QQ群 515267276
如果你的答案是“是”,并且渴望学习Python中的新内容,那么本文将帮助你轻松地在手机或平板电脑上阅读漫画。

海绵宝宝漫画(白色部分被标记为“天沟(gutter)”)
让我们看看上面的“海绵宝宝”。 这张图片有7个分镜,为了方便在手机外阅读,我们可以把它分割成7张图片,它们将保存在指定目录下,
输出:每个分镜被保存到指定目录。

这里我将从上到下扫描图像的每一行,然后绘制一张黑白图。白色代表天沟,黑色代表其他颜色。接着我们将从左到右扫描图像,同时绘制黑白图。
此方法有助于我们获取每个分镜的分辨率,然后保存在硬盘中。
我们在SpyderV3.2上使用PythonV3.6,同时需要PIL/Pillow库(Python图像库)。
软件需求
· Anaconda v5.1
Anaconda的Windows、Mac或Linux版本可以在这里下载。
(https://www.anaconda.com/download/)

· Python 3.6
Python的Windows、Mac或Linux版本可以在这里下载。
(https://www.python.org/downloads/)
PIL/Pillow的Windows、Mac或Linux版本可以在这里下载。
(https://wp.stolaf.edu/it/installing-pil-pillow-cimage-on-windows-and-mac/)
Python代码:
下面的链接可以下载到全部的Python代码。
Python 2
Python2和PI(Python图像库)
https://github.com/mozillamonks/comicstrip/blob/master/comicstrip
Python3
这个版本使用Pillow而不是PIL(不支持Python3)
Pillow是PIL的分支,它在Python3上添加了一些用户友好的特性。
https://github.com/sohamsil/comicstrip/blob/master/comicstrip_Python3.6
第一步,导入依赖库!

天沟在大部分的漫画上都是空白的,让我们创建一个名为gcolor的变量,并将它设为255(RGB)。
同时定义天沟的长宽gwidth=10和gheight=10。

我们需要在天沟中去除噪音,并且数字化我们的图像。让我们定一个可以调整对比度的变量contrast并且将值设置为0.8。(你可以根据实际需要调整它)

在深入各个方法前,我们再创建一个名为barrier的变量用来帮助我们区分天沟和漫画的其余部分。
barrier取值范围在1到255之间,如果图像上的颜色比barrier小,则记为黑色,否则记为白色。这里我们将它设为210。

现在让我们开始理解我们的方法。_isGutterRow()方法判断指定行是不是天沟,返回TRUE或FALSE。

类似的我们为列定义另一个方法。_isGutterCol()会检查指定列是不是天沟,并返回TRUE或FALSE。

更多干货分享加python编程语言学习QQ群 515267276
每次遇到一行时,我们将它传到_getRow()方法中,进一步优化分镜的上下边界。在确认了分镜的上下边界所在行后,此方法返回上下边界对应行号。


_getRows()帮助我们追踪图像的所有行,并帮助我们确认分镜的行边界。它有两个参数:self代表图像文件和startRow代表开始行号。
_isGutterRow()方法检查指定行是不是天沟,_getRow()方法返回分镜的上下行号。

同“行”的方式一样,每次遇到一列,我们将它传到_getCol()方法中来确定分镜的边界。在确定分镜的左右边界后,此方法返回左右边界的行号。


_getCols()帮助我们跟踪图像中的每一列,并确认分镜的左右边界。此方法有三个参数:self代表图像文件,rt代表分镜的上边界和rb代表分镜的下边界。
_isGutterCol()方法检查指定列是不是天沟,_getCol()方法返回分镜的左右行号。

_getFrames()输入整张像图并返回其中所有的分镜。


_digitize()用于图像数字化,_prepare()用于图像的预处理。

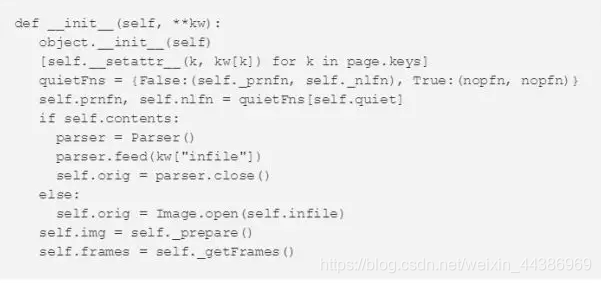
我们将定义page类的构造函数为__init__(),并根据我们将要使用的漫画页面的类型传递一个类的实例以及其他参数。
构造函数的参数说明如下:
-
startRow(默认值0):从哪一行开始分析。有一些漫画第一页的顶部有标题,我们需要忽略它。
-
lignore, ringore(两个的默认值均为0):被扫描的漫画在左右两边可能有不是纯白的部分,这会干扰天沟的检测。这两个参数告诉天沟检测算法如何调整左右边界,其中lignore表示左侧需忽略部分,rignore表示右侧需忽略部分。
-
contents(默认:True):
-
True=> infile:是漫画内容的字符串。
-
False=>infile:是漫画所在路径的字符串。
-
infile:表示漫画内容或漫画路径的字符串(由contents参数决定)
-
quiet:不打印任何状态信息。
-
debug:允许调试输出fwidth, fheight(分镜长宽的最小值)
将分镜导出到指定文件夹,文件名添加前缀和序号:



在终端上调用:
![]()
有效选项
-
版本,显示程序版本号,以及退出
-
显示简短的帮助信息,以及退出
-
不输出进度信息到stdout(默认 False)。
-
启用调试输出(默认 False)。仅用于调式。普通用户不必开启此选项。在使用-d选项的同时,开启-q选项有助于正常的进度显示不会干扰到调试输出。反之亦然。
-
输入文件的名称,为必需参数,可以是图像文件名。
输出文件前缀
分镜的文件名格式如下:
-
文件名前面的0会根据分镜的数量自动添加。如果你想要将文件保存在其他目录下,只需要在prefix上指定目录(例如: --prefix /tmp/foo-)
-
--left-ignore=PIXELS:在检测列时需要忽略的左边距。
更多干货分享加python编程语言学习QQ群 515267276
-
(默认值:0)有时候(特别上扫描的漫画图像)页面的中间部分会有阴影,导致天沟不是纯白的。这会干涉天沟检测算法无法正确识别天沟。这个参数告诉程序在检测天沟时,左边距有多少像素需要忽略。
注意:在输出最终分镜图像时并不会裁剪这部分图像-它只是代表在天沟检测时并不需要考虑的部分。
-
--right-ignore=PIXELS:在检测列时需要忽略的右边距。(默认值:0)同“--left-ignore",除了代表右边。
-
--startrow=PIXELS:每页从哪一行开始(除第一页之外)。对于扫描的漫画,天沟在顶部可能会有阴影,因此为干涉检测算法。这个参数告诉程序在检测行里需要跳过的行,从而让算法忽略阴影部分。
-
-- gutter-width=WIDTH:天沟宽度的最小值(默认15)。
-
-- min-width=WIDTH:分镜宽度的最小值(默认100)。这个值越精确,分镜提取算法速度越快。
-
-- min-height=HEIGHT:分镜高度的最小值(默认100)。这个值越精确,分镜提取算法速度越快。