一、Collection是什么
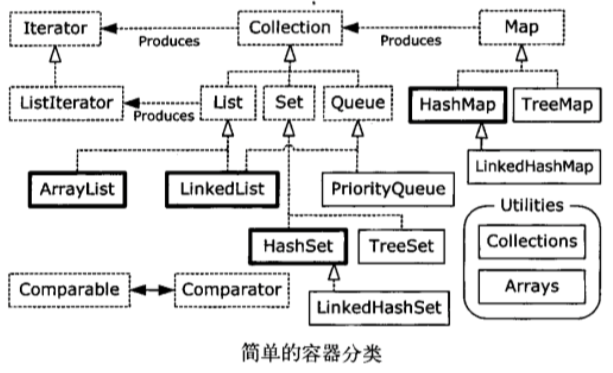
首先我们一起来探讨一下Collection究竟是什么个玩意,如上图所示List、Set、Queue、Map都指向Collection,它们都只是一个接口,并不是实现类。正因为有了Collection集合框架,使我们能方便的批量操作数据或对象。
二、List
List是有序的Collection,我们可以非常轻松的来控制数据插入的位置,并且也能根据其索引来访问List中的某个元素。
其实List实现类还是挺多的【AbstractList, AbstractSequentialList, ArrayList, CopyOnWriteArrayList, LinkedList, Stack, Vector】,但今天我们主要来讲讲常用的类ArrayList、LinkedList、Vector。
2.1 ArrayList
看名称就知道Arraylist是基于数组的链表,且线程不同步。我们可以看下其实现的add方法源码:
@Override
public boolean add(E object) {
Object[] a = array;
int s = size;
if (s == a.length) {
Object[] newArray = new Object[s +
(s < (MIN_CAPACITY_INCREMENT / 2) ?
MIN_CAPACITY_INCREMENT : s >> 1)];
System.arraycopy(a, 0, newArray, 0, s);
array = a = newArray;
}
a[s] = object;
size = s + 1;
modCount++;
return true;
}
2.2 Vector
Vector也是基于数组的链表,但是其线程是同步的【如下add方法被synchronized修饰】,其实现的add方法源码:
@Override
public synchronized boolean add(E object) {
if (elementCount == elementData.length) {
growByOne();
}
elementData[elementCount++] = object;
modCount++;
return true;
}
性能方面:Vector比Arraylist和Array都低;
线程方面:Vector线程同步,ArrayList线程不同步;
2.3 LinkedList
LinkedList与Vector、ArrayList有着明显的区别,其并不基于数组,所以对LinkedList元素进行增加、删除时,不需要批量移动其他元素。
其每个节点都包含以下两个信息:
1、该节点的数据
2、下一个节点的信息
小总结:基于Array的List(Vector、ArrayList)适合查询,LinkedList适合增删操作。
三、Set
Set是不包含重复的元素的无序Collection,并且Set都是基于Map实现的。
如果使用add()方法存入已存在的元素,则会覆盖之前的元素。
基于Set实现的类有AbstractSet, CopyOnWriteArraySet, EnumSet, HashSet, LinkedHashSet, TreeSet。
3.1 HashSet
我们可以先看下HashSet中的add()方法的源码:
transient HashMap<E, HashSet<E>> backingMap;
@Override
public boolean add(E object) {
return backingMap.put(object, this) == null;
}
其中backingMap为HashMap对象,我们应该知道HashMap是以键值对的形式来保存数据的,而在上述add()方法中,键为传入的对象,所以这就是Set不包含重复元素的最根本原因。
3.2 TreeSet
TreeSet是SortedSet的子类,它与HashSet最根本的区别在于:TreeSet是有序的,因为TreeSet是基于SortedMap来实现的。
四、Map
我们在聊Set的时候说道了HashMap,所以Map始终是以键值对形式存在的,并且其中的键是不允许重复的。
Map的常见实现有:HashMap和TreeMap。
如果我们要往HashMap中存入数据就可以使用put(Object key,Object value)方法,如果要取出数据也特别简单,使用get(Object key)方法。
在这里,我主要想聊聊HashMap和HashTable两个类的区别:
一、HashTable类是基于抽象类Dictionary的,而HashMap类是基于Map接口的实现;
二、HashTable类是同步的,这就保证了线程的安全,HashMap类是不同步的;
三、HashTable类元素不能为空,否则系统会抛空指针异常,而HashMap类value是可以为空的,当然啦,其中key也是可以为空的,但是如果我们这样设置,似乎毫无意义。
五、Queue
Queue(队列)先进先出,Stack(栈)后进先出。
方法名 方法含义 备注
add 增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常
remove 移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
element 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
offer 添加一个元素并返回true 如果队列已满,则返回false
poll 移除并返问队列头部的元素 如果队列为空,则返回null
peek 返回队列头部的元素 如果队列为空,则返回null
put 添加一个元素 如果队列满,则阻塞
take 移除并返回队列头部的元素 如果队列为空,则阻塞