感觉好久不写帖子了,一直忙别的事,终于得闲宽松几日,我又回来了哈哈哈哈哈~~~
没错,沉寂了一段时间,我又进步了!(嗯先夸下自己。。。)这几天,本小白摸了摸深度学习slam,特此记录一下。本帖只包含下载运行无原理解析,大神请绕走哈
网上找了几个深度slam的开源算法,最终选择了无监督的 SfMLearner 下手。这个算法通过对单目照片数据集(作者用的KITTI)进行学习,可以估计出抓取的单张图片的深度,以及相邻帧的位姿变换。我只测试了单目深度估计,没有测试位姿的,不过过程大同小异,还有,我知道 KITTI 包含了很多传感器数据,但是这里只用了单目的进行训练,杠精请收敛
1. 概念
之前对于深度学习的理解仅限于这四个字,故小白我很能体会屏幕前的各小白们,所以简单说两句(仅个人简单理解,不承担任何法律责任噢)。
深度学习网络是前馈神经网络的一种,只不过包含了很多隐藏层,所以不甘平庸的它就给自己加了 深度 两个字。跟普通神经网络一样,它也是通过n万次的迭代来将网络参数调整至最佳,也要通过反向传播算法来完成。
ok,深度学习就说这么多,再多就露馅儿啦 [笑哭]
2. 环境
首先的首先,如果笔记本是NVIDIA显卡,那么可以方便地用GPU跑深度学习,不过需要安装 CUDA、CUDNN,一定要选择跟自己显卡型号对应的版本。
我安装的是CUDA8.0,,,参考的是这两个帖子:
https://blog.csdn.net/wf19930209/article/details/81879514
https://blog.csdn.net/qq_41962120/article/details/80821113
首先呢,需要安装 python、tensorflow,以及需要的一些依赖(具体有哪些忘了。。。当时没记录)
作者推荐的是 tensorflow1.0,我在训练的时候出现问题,程序不能运行,所以查了下资料改用了新一点点的版本,所以我的配置是:
显卡:GEFORCE GTX 1050 Ti
CUDA:8.0
系统:Ubuntu16.04(双系统,不是虚拟机)
Python:2.7
tensorflow:1.2.1
我用python2.7安装tensorflow的时候报错,说要先安装另外一个东西,装了那个之后再装tensorflow就没问题了。
安装 tensorflow 的指令很简单:
pip install tensorflow-gpu==1.2.1
这句指令安装的是 支持GPU 的 tensorflow 版本,如果没有能用 CUDA 的 NVIDIA 显卡,就装普通的 CPU 版本:
pip install tensorflow==1.2.1
3. 下载源码
下载源码到指定文件夹,我是放在了 ~/home 下:
cd ~/home git clone https://github.com/tinghuiz/SfMLearner
代码是用 python 写的,所以不需要编译,直接就可以进行运行、测试。
作者用的是 KITTI 数据集训练的,所以我也用的 KITTI,具体操作如下:
进入作者给的链接,填写邮箱地址;
然后会收到一封邮件,里面给了下载链接,下载下来不是数据集而是一个压缩包;
将压缩包解压,运行里面的 sh 文件就可以下载相应的包了
但是用作者给的下载方法我是下不下来,不知道你们网络行不行。我最后是在Windows下用迅雷下的,速度500k往上:
前几步一样,只不过我不是直接运行的 sh 文件,而是把里面的网址 copy 了下来,在Windows里面用迅雷下载到移动硬盘,然后再回到Linux里面搞的。
下载数据的网址命名格式如下:
对于相机参数包:https://s3.eu-central-1.amazonaws.com/avg-kitti/raw_data/2011_09_26_calib.zip
‘2011_09_26’ 为日期,更改后就可以下载别的包了,如 2011_09_30_calib.zip 等
对于像片数据包:https://s3.eu-central-1.amazonaws.com/avg-kitti/raw_data/2011_09_26_drive_0002_sync.zip
像片数据包不但要改日期还要改序列编号,注意 ‘_sync’ 不能少,如 2011_09_26_drive_0009_sync.zip、2011_09_30_drive_0016_sync.zip
你可以把那些包都下下来,也可以根据需要只下一部分,想确定下哪一部分,把这个帖子后面的内容看明白了就知道了。我自己是只下了 _09_26 的。
4. 图片测试
这里我们是要用作者已经训练好的模型进行单张图片深度估计,首先我们需要下载作者的模型文件:
bash ./models/download_depth_model.sh
这个脚本会自动下载并进行解压,得到的模型编号为 190532,作者用的框架是 tensorflow,一个模型由三个文件构成。为了避免看的眼花,我在 model 下新建了个文件夹 kitti_depth_model,然后把这三个文件移进去了。前面我也说了,我只测试了深度估计,所以没有下载位姿估计的模型,想下载的话就运行 download_pose_model.sh
下载好后就可以用这个模型文件进行测试了,作者提供了一个简单图片测试的程序,文件名为 demo.ipynb,这是一个网页端服务器运行的文件格式,需要在自己系统上装上 jupyter notebook,然后启动 jupyter notebook 就会打开一个网页,在这个网页中可以运行 .ipynb 文件。
我个人不喜欢这种方式,我还是喜欢踏踏实实的 python 脚本,所以我把程序改了下,存在一个叫 demo.py 的文件里,放在 SfMLearner 目录下,内容为:
#!/usr/bin/env python from __future__ import division import os import numpy as np import PIL.Image as pil import tensorflow as tf import matplotlib.pyplot as plt import cv2 from pylab import * from SfMLearner import SfMLearner from utils import normalize_depth_for_display img_height=128 img_width=416 ckpt_file = 'models/kitti_depth_model/model-190532' fh = open('misc/sample.png', 'rb') I = pil.open(fh) I = I.resize((img_width, img_height), pil.ANTIALIAS) I = np.array(I) sfm = SfMLearner() sfm.setup_inference(img_height, img_width, mode='depth') saver = tf.train.Saver([var for var in tf.model_variables()]) with tf.Session() as sess: saver.restore(sess, ckpt_file) pred = sfm.inference(I[None,:,:,:], sess, mode='depth') plt.figure() plt.subplot(121) cv2.imshow("source",I) plt.subplot(122) cv2.imshow("result",normalize_depth_for_display(pred['depth'][0,:,:,0])) cv2.waitKey()
命令行进入 SfMLearner,运行:
python demo.py
可以看到如下结果,一个是深度估计的图像,一个是 ‘源图’,哈哈为啥我引起来,因为它好像不是源图,,颜色好像有点不一样,你可以跟 misc 里的图片对比一下,不过我确实么有对它进行什么处理。。。。这个不重要,不必深究

5. 数据集测试
从这儿开始,才是正片!下面就要看你对哪个感兴趣了,是用作者训练好的模型跑数据集,还是打算自己训练再用自己的模型跑数据集。前面也已经提到过了,可以根据需要下载数据集,且听我慢慢道来~~~~~~~
这部分介绍的是用作者训练好的模型跑数据集,既是已训练好的,那么就不必下一堆数据去训练了,可以只挑一两个下载进行测试,过过瘾就行啦
但也不是随便下一个就好,试想一下,如果你用了数据集 A、B 进行训练,那么测试的时候还用 A 或者 B 是不是就不合适了?所以我们要用另外一个 C 去测试才行。训练集、验证集、测试集的概念请自行百度。
作者提供了一个文件 data/kitti/test_scenes_eigen.txt,里面定义了可用于测试的数据序列,所以,你只需从这里面挑一两个下载即可。
假设我们只挑一个子数据集 2011_09_26_drive_0002,那么我只需要下载:
https://s3.eu-central-1.amazonaws.com/avg-kitti/raw_data/2011_09_26_calib.zip
https://s3.eu-central-1.amazonaws.com/avg-kitti/raw_data/2011_09_26_drive_0002_sync.zip
下载之后解压,将 3 个 calib 文件放到 2011_09_26_drive_0002_sync 同级目录,且确保上级目录为 2011_09_26,结构大致如下:

可以看到,我是把数据集整体放到了桌面上。
运行程序之前,还要对程序进行一点修改,因为作者的原程序是同时加载所有测试集,只要缺一个就报错无法运行。
首先修改 /data/kitti/test_files_eigen.txt,这里面详细描述了每个子测试集中包含的图片,程序运行时,会加载这个文件中的图片路径。修改前先备份!!!
我们这里只下了一个 2011_09_26_drive_0002,所以只保留 2011_09_26/2011_09_26_drive_0002_sync 开头的行,其它全部删掉。保存退出。
然后修改程序 data/kitti/kitti_raw_loader.py,这个程序负责加载图片等文件。将第 27 行左右 :
self.date_list = ['2011_09_26', '2011_09_28', '2011_09_29', '2011_09_30', '2011_10_03']
修改为:
self.date_list = ['2011_09_26']
保存退出。
这个时候如果直接运行程序,是看不到图片的。是的,这个作者并没有在程序中添加显示图片的功能,,,,,奇葩吧?!!
修改 test_kitti_depth.py:
首先在前面 import 相关模块:
import cv2
import matplotlib.pyplot as plt
第 38 行左右,with 前添加:
plt.ion()
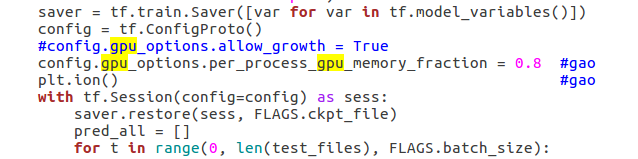
68 行左右,pred_all.append(pred['depth'][b,:,:,0]) 下面添加:
plt.subplot(211)
plt.imshow(scaled_im, cmap='gray')
plt.subplot(212)
plt.imshow(pred['depth'][b,:,:,0], cmap='gray')
plt.pause(0.05)
75 行左右,np.save(output_file, pred_all) 下面添加:
plt.close()
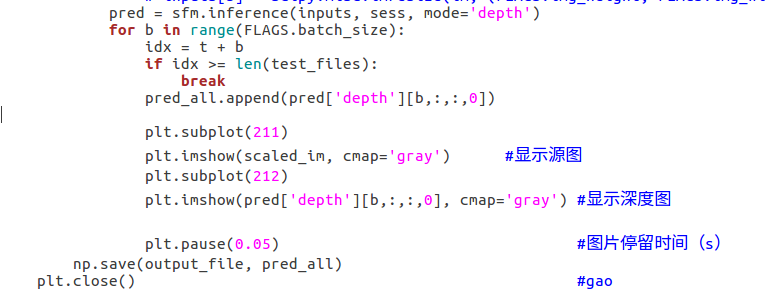
保存退出,然后就可以运行程序了:
python test_kitti_depth.py --dataset_dir /home/gao/Desktop/ --output_dir /home/gao/SfMLearner/gao_first --ckpt_file /home/gao/SfMLearner/models/kitti_depth_model/model-190532
其中 ‘dataset_dir’ 的值即为 '2011_09_26' 的位置,’output_dir‘ 用于保存×××(我也不知道这是啥哈哈哈),'ckpt_file' 为模型文件所在位置,最后一定要加上模型编号,作者估计这个问题太简单了就没说,害得我迷糊了好久
运行效果如下:
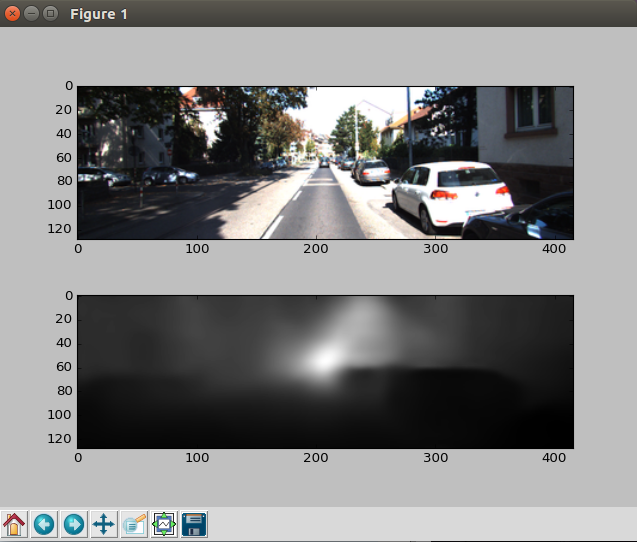
如果运行程序,报GPU的错,大概意思为显卡显存不够,那么就修改程序 test_kitti_depth.py:
36 行左右,注释掉 ’config.gpu_options.allow_growth = True‘,下面添加:
config.gpu_options.per_process_gpu_memory_fraction = 0.8
这是对 GPU 进行设置,避免程序毫无节制地占用显卡内存。
6. 训练模型
这里介绍的是训练自己的模型。
首先需要下载用于训练的数据集,上一部分也说了 test_scenes_eigen.txt 中的子数据集是作者用于测试的,所以如果不想改这个文件,那么你就去下载这个文件里面没有提到的子数据集进行训练。
因为训练程序运行时,不会加载 test_scenes_eigen.txt 中的子数据集,比如 2011_09_26,假如我就要用 2011_09_26 进行训练,当然可以,不过要改一下 test_scenes_eigen.txt,也不难,只需要把 2011_09_26_drive_0002 这一行删掉就行了。修改之前别忘了备份噢!!
理论上讲,深度模型的训练绝不是这样一个小子数据集就能做的很好的,它需要大量数据,这里仅以 2011_09_26 为例示意一下过程而已。
训练之前需要对原数据集进行一下处理,这跟作者的网络设计有关,我的 2011_09_26 还是放在桌面上,命令行进入 SfMLearner 执行:
python data/prepare_train_data.py --dataset_dir=/home/gao/Desktop/ --dataset_name='kitti_raw_eigen' --dump_root=/home/gao/Desktop/2011_09_26_formatted --seq_length=3 --img_width=416 --img_height=128 --num_threads=4
其中,’dataset_dir‘ 为 2011_09_26 位置,’dump_root‘ 为处理后的数据存放位置,其它按作者意思来就行。
注意了,如果没有将 2011_09_26 从 test_scenes_eigen.txt 中删掉,是不会处理成功的噢!
处理成功后,会在指定的文件夹下生成处理后的数据,我的是桌面上的 2011_09_26_formatted,它下面会有 2011_09_26_drive_0002_sync_02、2011_09_26_drive_0002_sync_03,将 2011_09_26_formattedtrain.txt、2011_09_26_formattedval.txt 改名为 train.txt、val.txt,然后移到 2011_09_26_drive_0002_sync_02 同级目录,大概这样纸:
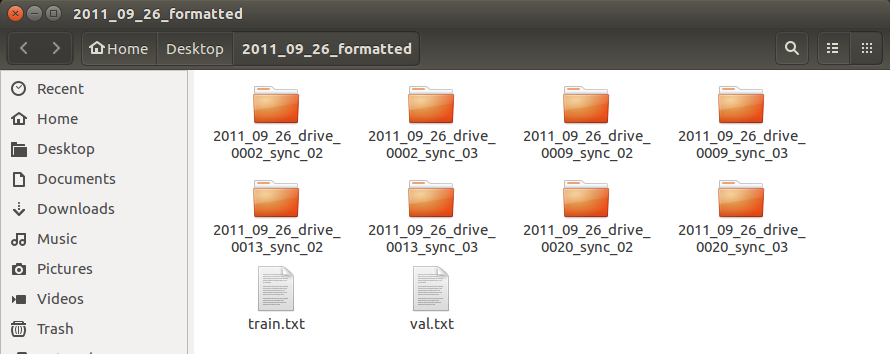
我是之前自己做的时候同时处理了 09、13、20,所以才会多了 6 个文件夹,忽略就好。
训练数据已备好,可以开始训练咯,命令行进入 SfMLearner 执行:
python train.py --dataset_dir=/home/gao/Desktop/2011_09_26_formatted/ --checkpoint_dir=/home/gao/SfMLearner/gao_checkpoints/ --img_width=416 --img_height=128 --batch_size=4
其中,’dataset_dir‘ 为训练数据位置,’checkpoint_dir‘ 为保存模型的位置,其它按作者意思来
程序会默认保存最近的 10 次模型(可以在程序中进行修改),每个模型 3 个文件
训练时大概长这样:
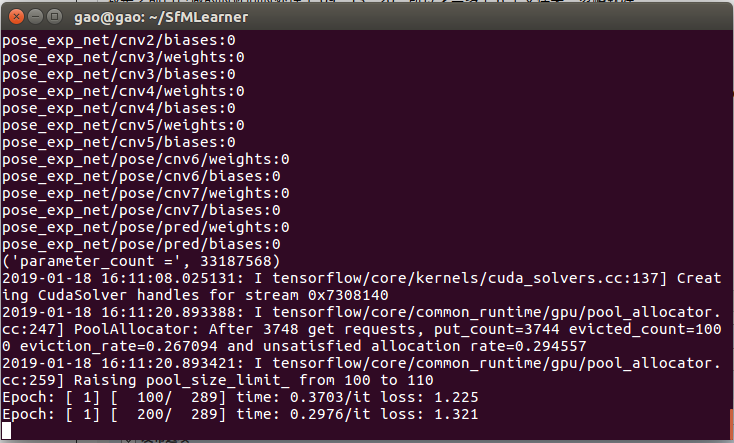
epoch、global_step 等概念自行百度。
另外,运行训练程序时,可能也会出现 GPU 内存不够的问题,编辑 SfMLearner.py:
第 224 行左右,注释掉 ’onfig.gpu_options.allow_growth = True‘,下面添加:
config.gpu_options.per_process_gpu_memory_fraction = 0.8

保存退出,重新运行训练程序。
7. 用自己训练的模型运行数据集
方法同第5部分,只需修改一下模型路径和编号即可:
python test_kitti_depth.py --dataset_dir /home/gao/Desktop/2011_09_26_2/ --output_dir /home/gao/SfMLearner/gao_second --ckpt_file /home/gao/SfMLearner/gao_checkpoints/model-115311
这里我把路径改了一下,我测试时的数据集放在桌面的 2011_09_26_2 下,然后我的模型保存的位置是 /home/gao/SfMLearner/gao_checkpoints/,为了避免与作者训练的模型输出混淆, output_dir 我也改了一下。
我用 02、09、13、20 训练了一下午+一晚上,400 次 epoch,然后用 84 测试的
效果哈哈哈哈哈哈哈哈哈哈哈哈极差![微笑]