一、什么是机器学习?

增加数据、调整算法。
三、算法是什么?
算法是公式、数据是公式的x、y;模型是参数。
模型是什么?
模型是参数:计算机计算模型的过程就是要找到最优解(误差最小)的过程。
四、线性回归(X、Y的变化符合一条直线;回归到平均值)
简单的线性回归: Y=a+bx
多元线性回归:Y=W1*X1+W2*X2+W3*X3+...Wn*Xn+W0
通过数据对模型的求解求出的结果并不是完美解,而是最优解。
线性回归主要用来干嘛的?线性回归主要用来预测,通过已知的数据训练出一个模型,当有新的变量x值传入的时候,我们通过训练出来的模型求出y。
应用案例

charges列(Y)是保险公司的花销,而age、sex、bmi、children等列是影响charges的因素;也就是特征(X)。
代码分析
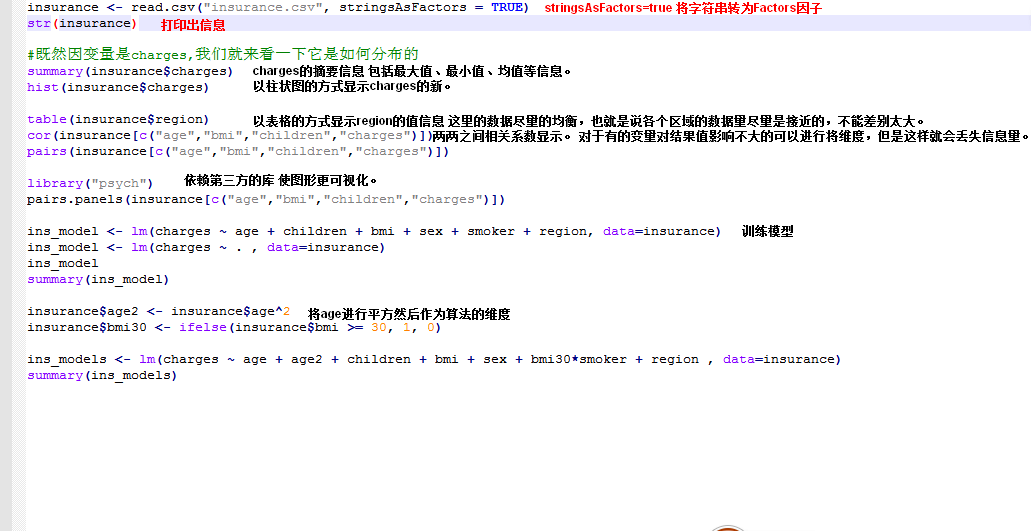
getwd()方法显示默认csv文件的目录、可以使用setwd("path")设置csv文件的目录;如setwd("D:/workspaceR")然后将csv文件放置到此目录下。
运行结果分析:

五、神经网络(预测)
一只猫大约有10亿个神经元,一只老鼠大约有7500个神经元,一只蟑螂大约有100万个神经元,许多人工神经网络包含的神经元要少的多,通常几百个,我们在不久的将来随时能创建一个人工的大脑是没有危险的。
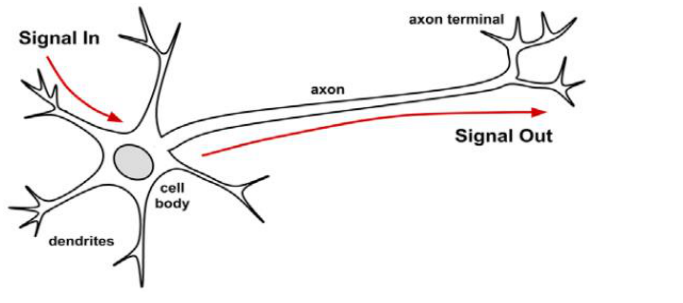
从生物神经元到人工神经元
--激活函数:将神经元的净输入信号转换成单一的输出信号,以便进一步在网络中传播。
--网络拓扑:描述了模型中神经元的数量以及层数和它们的连接的方式。
--训练算法:指定如何设置连接权重,以便抑制或增加神经元在输入信号中的比重。
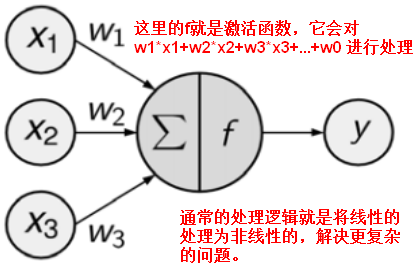
激活函数
Threshold函数(可以进行阈值化操作)
Sigmoid函数(常被用作神经网络的阈值函数,将变量映射到0,1之间)
网络拓扑层
单层网络
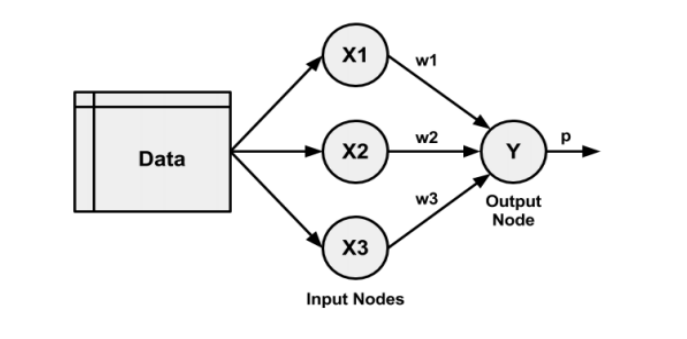
多层网络
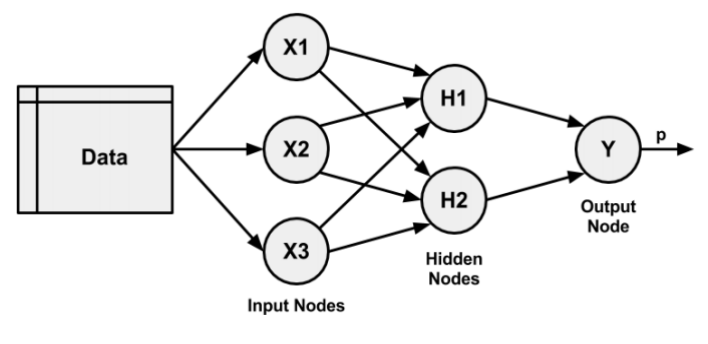
案例
已有的数据
代码分析
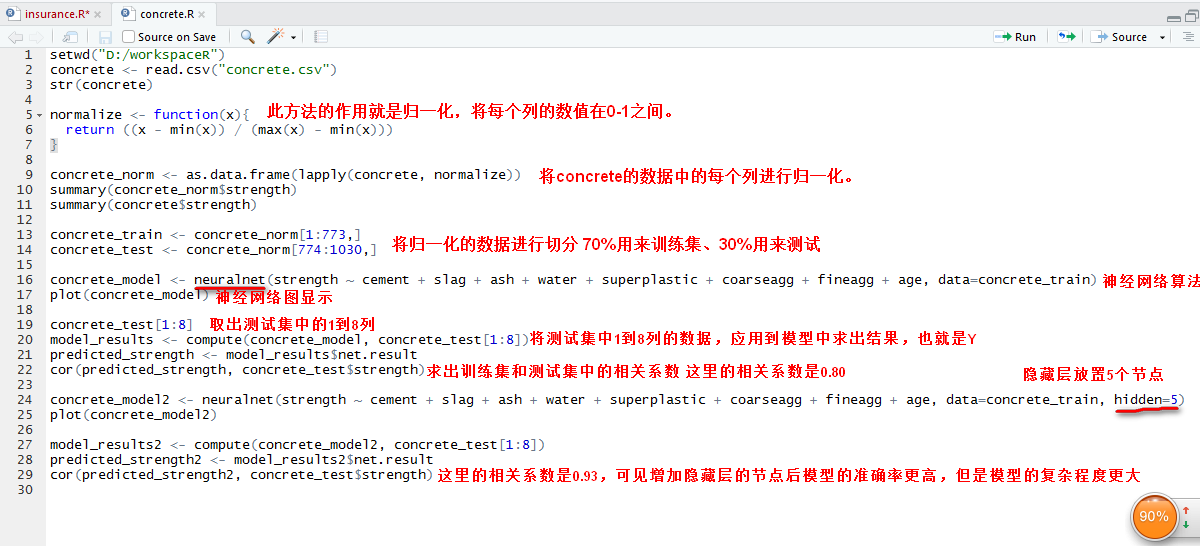
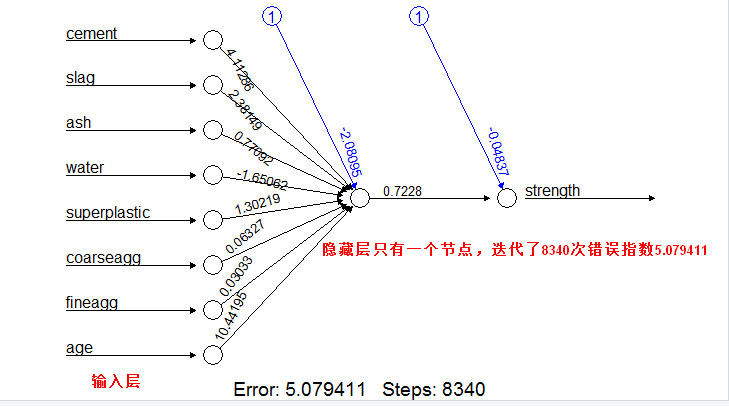
隐藏层一个节点的plot()结果
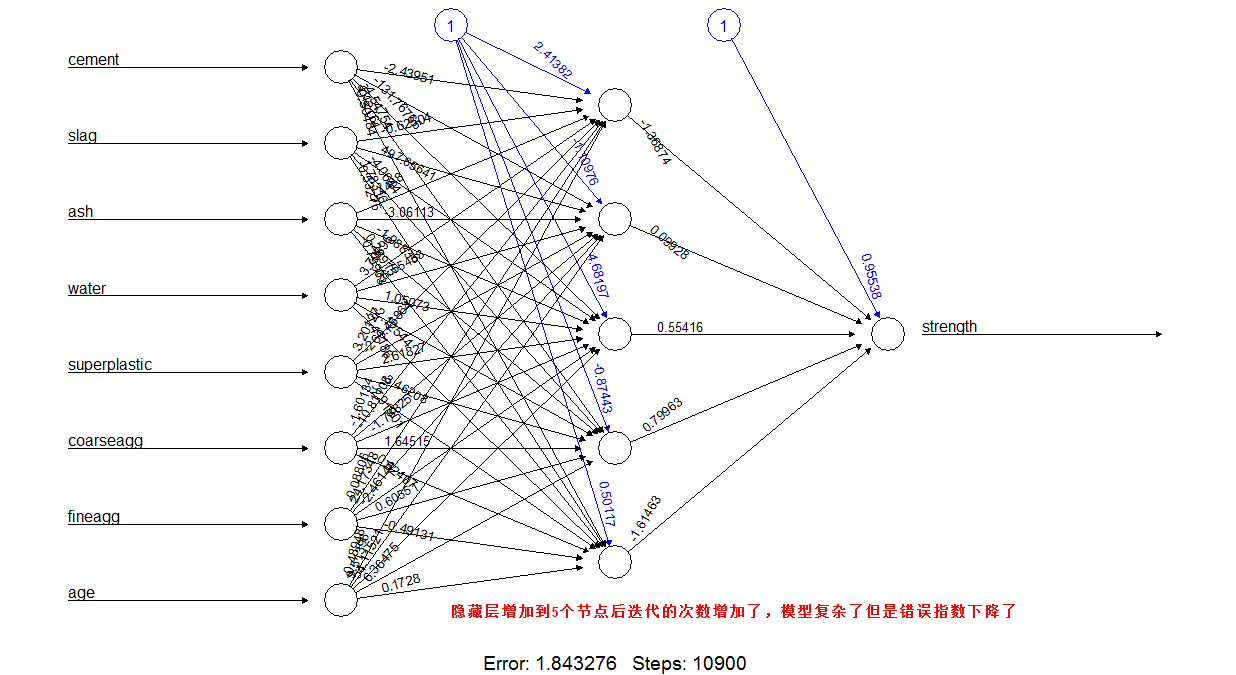
隐藏层多个节点的输出
六、关联规则
{花生酱,果酱}->面包 :这个关联规则通俗的语言来表达就是如果购买了花生酱和果酱,那么很有可能会购买面包。
{啤酒}->尿布:
支持度和置信度
一个项集或者规则度量法的支持度是指其在数据中出现的频率。
置信度是指该规则的预测能力或者准确度的度量。

Apriori算法(数据的挖掘)
1)它是一种挖掘关联规则的频繁项集算法.
2)Apriori原则指的是一个频繁项集的所有子集也必须是频繁的,如果{A,B}是频繁的,那么{A}和{B}都是频繁的。
3)根据定义。支持度表示一个项集出现在数据中的频率,因此如果知道{A}不满足所期望的支持度阈值,那么就没有必要考虑{A,B}或者任何包含{A}的项集,这些项集绝对不可能是频繁的。
Apriori算法的分为两个阶段
--识别所有满足最小支持度阈值的项集。
--根据满足最小支持度阈值的这些项集来创建规则。
例如:
迭代1需要评估一组1项的项集,迭代2评估2项集,以此类推。在迭代中没有产生新的项集,算法终止。之后,算法会根据产生的频繁项集,根据所有可能的子集产生关联规则。
案例:
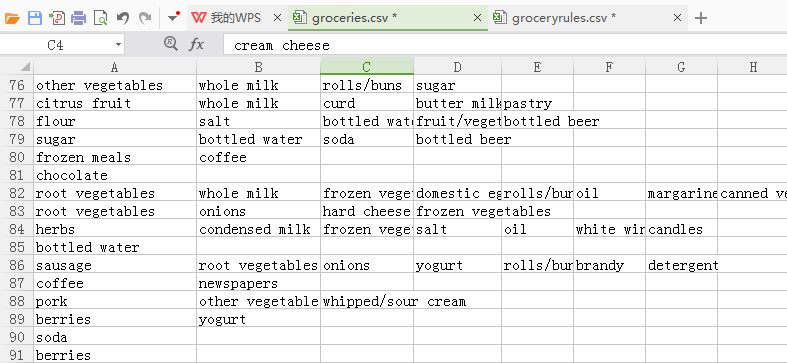
上述表中的一条数据代表一个消费者的消费信息;根据这些数据可以找出商品的关联规则,帮助商品的合理摆放。
代码实现

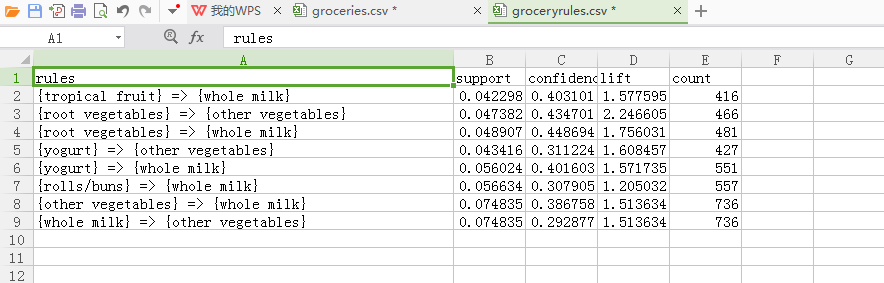
运行结果
最后产生了8条规则
七、贝叶斯算法
机器学习算法中,有一种利用概率的原则进行分类的朴素贝叶斯算法,正如气象专家预测天气一样,朴素贝叶斯算法就应用先前事件的有关数据来估算未来事件发生的概率。
理解朴素贝叶斯
P(B|A) = P(A|B)*P(B) / P(A)
案例
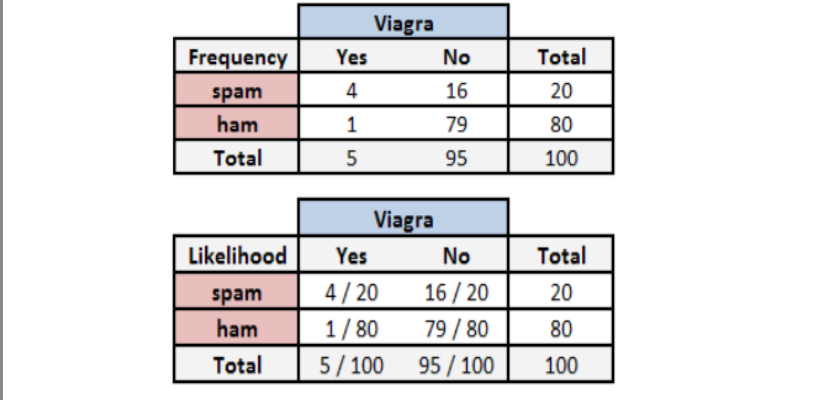
垃圾邮件(spam)与Viagra之间的关系
在这里我们计算出邮件中只要出现Viagra单词是垃圾邮件的概率。 这样的话,就可以根据概率的大小进行判断此邮件是否归类于垃圾邮件。
这里我们定义为垃圾邮件是事件A,邮件出现Viagra单词是事件B,求出邮件中出现Viagra单词并且是垃圾邮件的概率是多少???
P(A)=20/100 P(B)=5/100 P(B|A)=4/20
P(A|B)=P(B|A)*P(A)/P(B)=(4/20*20/100)/(5/100)=0.8
电子邮件中含有单词Viagra,那么该电子邮件是垃圾邮件的概率为80%。所以,任何含有单词Viagra的消息都需要被过滤掉。
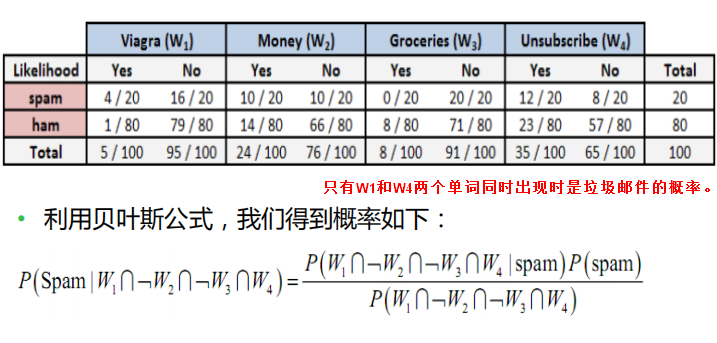
当有额外更多的特征的时候,这一概念如何被使用?



总结
机器学习的几个点
1)预测
训练模型
多元线性回归
神经网络
2)分类
训练模型
贝叶斯分类
拉普拉斯估计
3)聚类
4)推荐
基于物品的协同过滤
5)关联规则(Apriori)
支持度
置信度
Apriori算法
6)降维
八、逻辑回归(主要用于分类)
逻辑回归其实就是多元线性回归的归一化。
多元线性回归 z=w1*x1+w2*x2+w3*x3+...wn*xn+w0
逻辑回归 y=1/1+e^(-z)
九、scikit-learn
在机器学习和数据挖掘的应用中,scikit-learn是一个功能强大的python包。在数据量不是过大的情况下,可以解决大部分问题。
scikit-learn中的常用算法

下面的案例采用的是分类中的逻辑回归算法进行音乐的分类。上面邮件分类(文本)采用的是贝叶斯算法。不同的场景使用不同的算法使结果更加准确。
案例:音乐的分类(数据->算法->模型,当有新的数据输入时带入模型输出分类号进行数据的分类)
--数据集(音乐数据)
--算法使用(scikit-learn中的logistic regression)
--期望结果(输入一首歌,可以对输入的歌曲进行分类)
多元线性回归进行缩放(归一化)就是逻辑回归。即:多元线性回归 z=w1*x1+w2*x2+w3*x3+...wn*xn+w0 逻辑回归 y=1/1+e^(-z) 其结果处于0-1之间。
逻辑回归本质上是作为二分类,数据大于0.5是一个类别,小于0.5的是一个类别。但是多分类问题也可以通过分解成多个二分类(以后在讨论)。
1)采样数据集(均匀)
分类型存在文件夹中(每首歌的时间是30s)
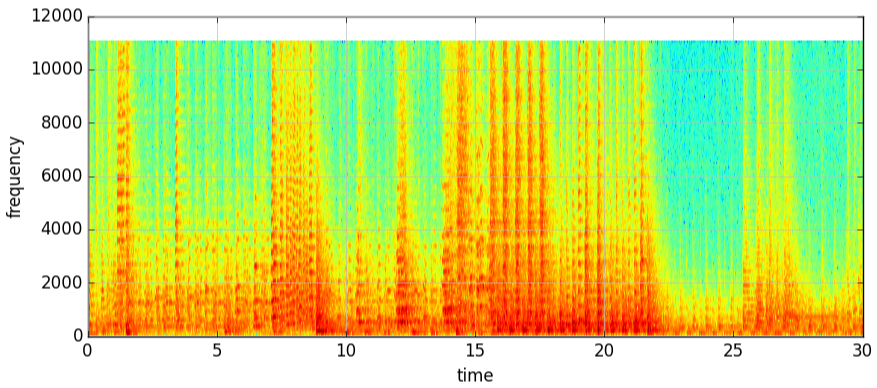
以先把一个wma文件读入python,然后绘制它的频谱图(spectrogram)来看看是什么样的jazz
计算机本身不能听懂音乐,因此需要把音乐转为数字来供计算机进行处理。
一首歌曲区别于另一首歌曲的方式有好多,比如,演唱者,作曲人,歌曲的音调等。
这里我们通过音乐的频率的方式区别音乐到底属于哪个类型。
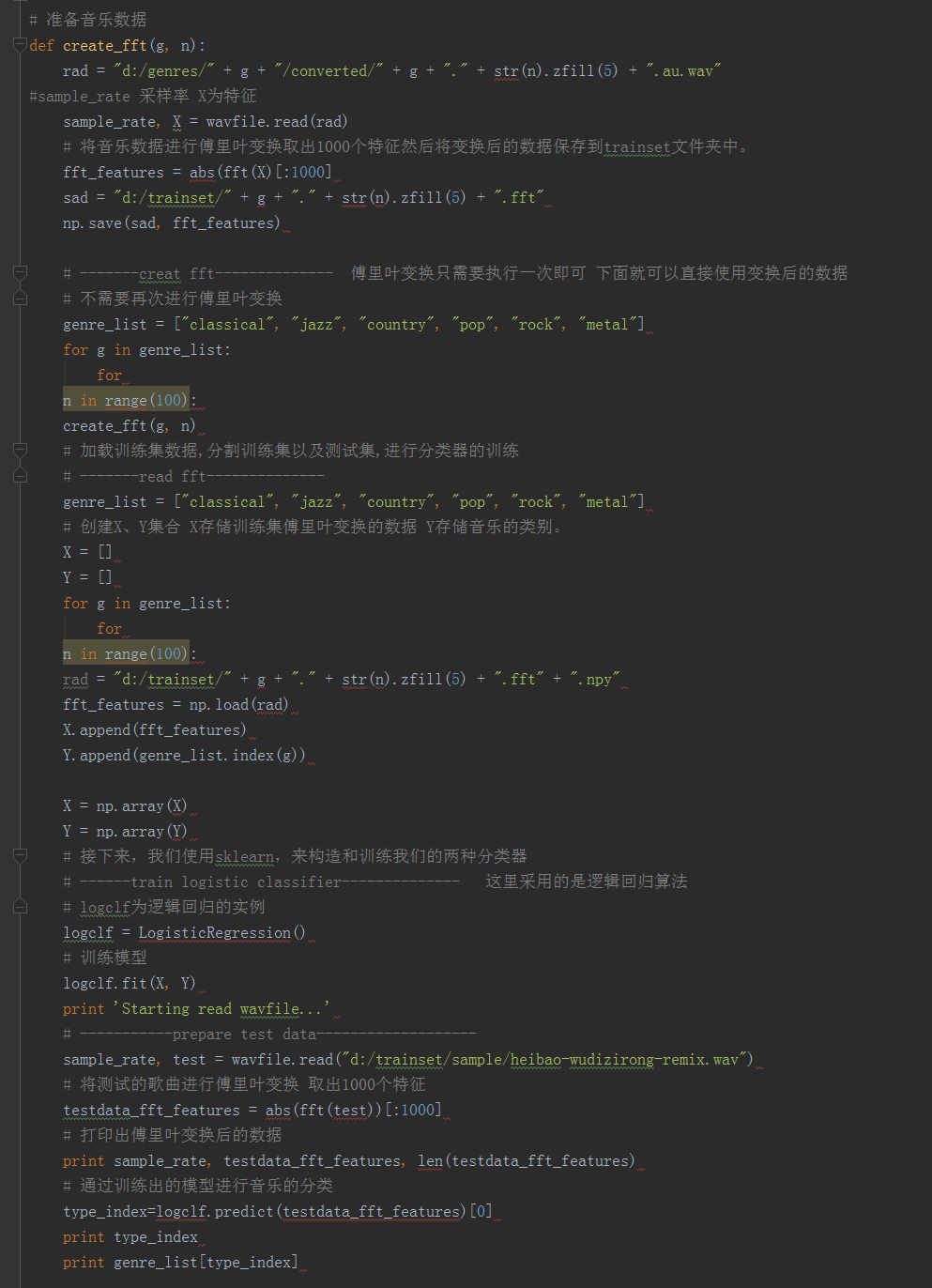
代码实现

傅里叶变换
可以把time domain上的数据,例如一个音频,拆成一堆基准频率,然后投射到frequency domain上
上述的内容只是机器学习的了解,真正在公司做机器学习的时候,使用的是大数据中的SparkMLlib。