tensorflow给我的感觉就是定义了一系列的计算方法和流程,但是网络的构建还是需要自己去定义的。比如隐藏层的个数,隐藏层的神经元的数量等等。所以,首先定义一个添加隐藏层的函数。
1. 添加隐藏层
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
'''
添加一个隐藏层
:param inputs: 该层的输入
:param in_size: 输入size
:param out_size: 输出size
:param activation_function: 激励函数
:return: 输出结果, w, b
'''
# 随机初始化w
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# 初始化bias为0.1
bias = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# 计算w*x+b
Wx_plus_b = tf.matmul(inputs, Weights) + bias
# 如果没有激励函数,就直接返回wx+b
if activation_function == None:
out_puts = Wx_plus_b
# 如果有激励函数,则使用激励函数激励后再输出
else:
out_puts = activation_function(Wx_plus_b)
return out_puts, Weights, bias
在上面的函数中,我们定义了四个输入参数,inputs是该层的输入数据,in_size表示输入数据的大小,也就是上一层神经元的个数,out_size表示该层神经元的输出,也就是该层神经元的个数,activation_function就是激励函数,默认为None。
2. 生成实验数据
在本实验中,我们生成了一条添加了噪声的二次曲线:

import numpy as np
def createData():
# 创建从-1到1之间的300个数据,并转换为列向量
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]
noise = np.random.normal(0, 0.05, x_data.shape) # 生成噪声
y_data = np.square(x_data) - 0.5 + noise # x^2-0.5 + noise
return x_data, y_data
3. 定义网络结构
def main():
# 获取生成数据
x_data, y_data = createData()
# 定义输入输出,即输入输出神经元都是一个
xs = tf.placeholder(tf.float32, [None, 1], name='x-input')
ys = tf.placeholder(tf.float32, [None, 1], name='y-input')
# 创建第一个隐藏层,该层的输入就是x,一个输入,定义该层有10个神经元,激励为relu
layer1, weights1, bias1 = add_layer(tf.cast(x_data, tf.float32), 1, 10, activation_function=tf.nn.relu)
# 创建输出层,输出层的输入就是隐藏层的输出,所以输入的size为10,而输出size为1
# 输出曾没有定义激励函数
prediction, weights2, bias2 = add_layer(layer1, 10, 1)
# 计算损失函数,计算的是均方误差
loss = tf.reduce_mean(tf.reduce_sum(tf.square(y_data - prediction), reduction_indices=[1]))
# 定义训练操作,训练的目的就是采用一个优化器(这里是梯度下降),最小化均方误差
train = tf.train.GradientDescentOptimizer(0.3).minimize(loss)
# 顶初始化变量操作,在2017-03-02后使用global_variables_initializer()
# 代替initialize_all_variables()
init = tf.global_variables_initializer()
### ------- Training start ------ ###
with tf.Session() as sess: # 开启一个会话
sess.run(init) # 初始化所有变量
# 开始训练,迭代轮数为1000轮
for step in range(1000):
sess.run(train, feed_dict={xs: x_data, ys: y_data})
# 每迭代50轮就输出一下当前的loss
if step % 50 == 0:
print(step, 'loss=', sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
# 训练完成,输出各层的参数
print('training finished! The parameters are:\n',
'Wrights1=', sess.run(weights1), '\n',
'bias1=', sess.run(bias1), '\n',
'Wrights2=', sess.run(weights2), '\n',
'bias1=', sess.run(bias1),)
### ------- Training start ------ ###
在上面的代码中,我们定义了一个1X10X1结构的神经网络,采用的损失函数是均方误差,优化器采用的梯度下降,学习率设置为0.3。经过多轮迭代后,输出参数为:
Wrights1= [[-0.8419331 -0.11334516 1.2193328 -0.7890344 -1.2332425 0.40209204
-0.39713663 0.04796262 -0.74344707 -0.11859597]]
bias1= [[-0.32630572 -0.42274514 -0.41647813 -0.7892685 -0.13873461 -0.42988452
-0.39751637 0.3350995 -0.4698821 0.49600926]]
Wrights2= [[ 0.7110287 ]
[ 1.1935027 ]
[ 1.0481343 ]
[-0.5998492 ]
[ 0.40031695]
[ 0.9401001 ]
[-0.57735807]
[-0.3572133 ]
[ 0.7643545 ]
[-0.6908059 ]]
bias1= [[-0.32630572 -0.42274514 -0.41647813 -0.7892685 -0.13873461 -0.42988452
-0.39751637 0.3350995 -0.4698821 0.49600926]]
4. 可视化
在训练的过程中,我们希望可以看到loss的变化曲线或者当前训练的曲线。所以这里就需要用到可视化。
4.1 loss曲线
在训练开始前,我们要生成一张图片:
plt.figure(1)
plt.ion() # 开启interactive mode 成功的关键函数
其中,ion()这个函数表示可以连续画图。
然后我们在训练的循环中求出每轮迭代的loss,并用散点图的方式画出这个loss:
with tf.Session() as sess:
sess.run(init)
for step in range(1000):
# 训练
sess.run(train, feed_dict={xs: x_data, ys: y_data})
# 求取该轮的loss
loss_value = sess.run(loss, feed_dict={xs: x_data, ys: y_data})
# 画图
plt.scatter(step, loss_value)
生成的图片如下所示:

比较值得注意的是,添加了画图之后,程序运行速度变得特别慢,所以一般还是将loss保存来,最后统一画图会比较好。如果是做演示的画,这样还是比较好看的。
关于更多的动态绘图的资料,我推荐这篇文章:python中plot实现即时数据动态显示方法。
4.2 显示当前训练曲线
与4.1一样,我们需要在开始训练之前,生成一张图,画出需要训练的数据点“
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter(x_data, y_data)
plt.ylim((-0.75, 0.75))
plt.ion() # 开启interactive mode
plt.show()
然后在训练过程中,每迭代50轮就画出当前训练出来的曲线:
with tf.Session() as sess:
sess.run(init)
for step in range(2001):
sess.run(train, feed_dict={xs: x_data, ys: y_data})
if step % 50 == 0:
try:
ax.lines.remove(lines[0])
except Exception:
pass
prediction_value = sess.run(prediction, feed_dict={xs: x_data})
lines = ax.plot(x_data, prediction_value, 'r-', lw=5)
plt.pause(0.2)
这里使用了try-except,主要是为了避免在第一次的时候报错,每次循环进来后,先用ax.lines.remove()清除上一条曲线,然后再画出当前的训练曲线,如下所示:
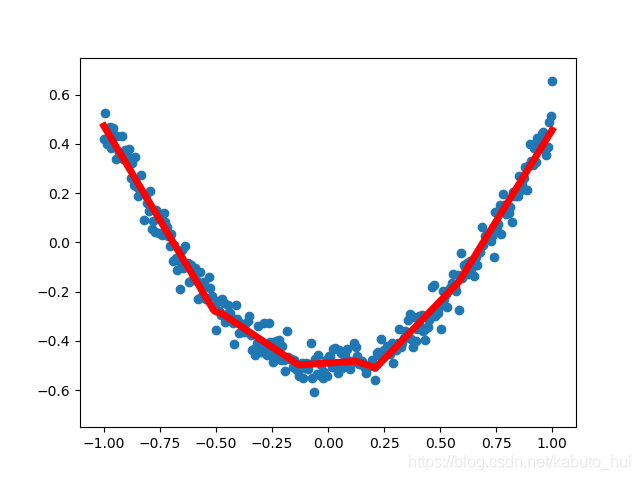
这样在训练的过程中就能观察拟合曲线的变化。
【注意】:这种可视化会影响训练的速度,如果不是出于演示的需要,最好在使用的时候不加入可视化。