文章目录
1 模块
1.1 sys模块

sys.path存储模块搜索路径,当导入模块时,先在当前目录下查找模块,如果没有,则去存储模块搜索路径中去寻找
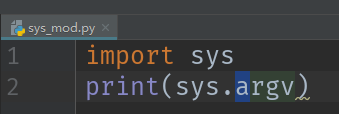

获取命令行输入参数
1.2 os模块

执行命令,成功返回0

执行系统命令将结果存储到cmd_res变量里
2 pyc
python是一门先编译后解释的语言,编译是自动完成的
当Python程序运行时,编译的结果保存在位于内存的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。当Python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,若找到,则直接载入,否则就重复上面的过程。因此可以说pyc文件是PyCodeObject的一种持久化保存方式。
3 数据类型
Python3 中有六个标准的数据类型:
- Number(数字)Python3 支持 int、float、bool、complex(复数)。在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
4 三元运算符
a,b,c=1,2,3
result=a if b<c else b
#如果b<c,result=1,否则result=2
5 Bytes
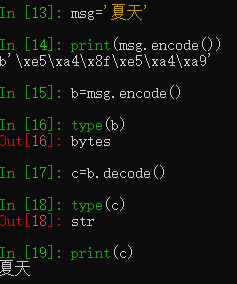
在Python3以后,字符串和bytes类型彻底分开了。字符串是以字符为单位进行处理的,bytes类型是以字节为单位处理的。
bytes数据类型在所有的操作和使用甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象。
bytes对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定。Python3中,bytes通常用于网络数据传输、二进制图片和文件的保存等等。可以通过调用bytes()生成bytes实例,其值形式为 b’xxxxx’,其中 ‘xxxxx’ 为一至多个转义的十六进制字符串(单个 x 的形式为:\x12,其中\x为小写的十六进制转义字符,12为二位十六进制数)组成的序列,每个十六进制数代表一个字节(八位二进制数,取值范围0-255),对于同一个字符串如果采用不同的编码方式生成bytes对象,就会形成不同的值.
b = b'' # 创建一个空的bytes
b = byte() # 创建一个空的bytes
b = b'hello' # 直接指定这个hello是bytes类型
b = bytes('string',encoding='编码类型') #利用内置bytes方法,将字符串转换为指定编码的bytes
b = str.encode('编码类型') # 利用字符串的encode方法编码成bytes,默认为utf-8类型
bytes.decode('编码类型') #:将bytes对象解码成字符串,默认使用utf-8进行解码。
对于bytes,我们只要知道在Python3中某些场合下强制使用,以及它和字符串类型之间的互相转换,其它的基本照抄字符串。
简单的省事模式:
string = b'xxxxxx'.decode() 直接以默认的utf-8编码解码bytes成string
b = string.encode() 直接以默认的utf-8编码string为bytes
6 列表
6.1 列表简介
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
t=['a','b','c','d']
>>>t=[0]
a
>>>t=[1:3]
['b','c']
6.2 列表使用
list = [ 'abcd', 786 , 2.23, 'word', 70.2 ]
tinylist = [123, 'word']
print (list) # 输出完整列表
print (list[0]) # 输出列表第一个元素
print (list[1:3]) # 从第二个开始输出到第三个元素
print (list[2:]) # 输出从第三个元素开始的所有元素
print (tinylist * 2) # 输出两次列表
print (list + tinylist) # 连接列表
#追加
names=['zhangsan','lisi']
names.append("小明")
#插入
#names=['zhangsan','lisi','小明']
names.insert(1,'小红')
#names=['zhangsan','小红','lisi','小明']
#删除
names.remove('小红')
del names[1]
names.pop()#删除最后一个
names.clear()#清空列表
del names#删除列表
print(names.index('小红'))#获取下标
print(names.count(‘小红’))#获取次数
#反转
names.reverse()
#排序
names.sort()
names2=[1,2,3,4]
names.extend(names2)#将names2列表添加到names列表里
#复制
names3=names2.copy()#复制一份如果列表里包含列表,列表里列表里改变了,复制的也会改变
a=['a','b','c',[1,2,3]]
b=a.copy()
a[3][0]=4
b=['a','b','c',[4,2,3]]
#浅copy应用在共同变量
#三种浅复制方法
b=copy.copy(a)
b=copy[:]
b=list(a)
#要完整复制使用copy模块
import copy
b=a.deepcopy()
for i in b:
print(i)
print(b[::2])#print(b[0:-1:2])
#打印下标和值,enumerate(b)结果是一个元组
for index,item in enumerate(b):
print(index,item)
#判断列表长度
print(len(b))
#打印红字
print('\033[31;1m红字\033[0m')
7 元组
#元组和list差不多,只是一旦创建无法改变
name=(1,2)
#只有index和count方法
8 字典
8.1 字典简介
字典是一种key-value的数据类型
语法:
info={
'name':'zhangsan',
'age':22
}
字典的特性:
dict是无序的,key必须是唯一的,所以天生去重
8.2 字典使用
#修改
info['name']="lisi"
#创建
info['grade']=80.5
#删除
del info['name']
info.pop('name')
info.popitem()#随机删除
#查找
print(info.get('name'))#没有返回None
#判断key是否存在
print('name' in info)
#获取所有值
print(info.values())
#获取所有keys
print(info.keys())
#先查找是否存在key为school,没有则创建有则返回
info.setdefault('school','清华大学')
#将字典合并有的话就更新
a={'bir':'7月22日'}
info.update(a)
#将一个字典转换成列表,键和值变为元组
info.items()
#创建一个字典并都初始化为后面的值,共享一个内存地址
c=dict.fromkeys(['name','age'],['zhangsan',22])
#字典的循环
for i in info:
print(i,info[i])#i为key
for k,v in info.items():
print(k,v)
9 集合
9.1 集合简介
集合(set)是一个无序不重复元素的序列。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)
9.2 集合使用
set_1=set([1,2,3,4,5])
set_2=set([2,4,6,7,8])
#获取交集
print(set_1.intersection(set_2))
print(set_1&set_2)
#并集
print(set_1.union(set_2))
print(set_1|set_2)
#差集(保留1里面有的2里面没有的)
print(set_1.difference(set_2))
print(set_1-set_2)
#判断set_1是否是set_2的子集
print(set_1.issubset(set_2))
#对称差集将两个集合合并成一个集合去除重复的
print(set_1.symmetric_difference(set_2))
print(set_1^set_2)
#判断集合是否有交集
print(set_1.isdisjoint(set_2))
#基本操作
#添加
set_1.add('20')
#添加多个
set_1.update([33,44])
#删除
set_1.remove('1')
#长度
len(set_1)
#x是否是set_11成员
x in set_1
#x not in set_1
x not in set_1
#测试是否s中的每一个元素都在set-1中
s.issubset(set_1)
s<=set_1
#删除并返回删除的元素
set_1.pop()
#删除固定元素
set_1.discard(1)
10 字符串
name="my \tname is zhangsan"
#首字母大写
print(name.capitalize())
#统计a个数
print(name.count('a'))
#居中
print(name.center(50,"-"))#居中不足用-补充
#判断字符串以什么结尾
print(name.endswith("an"))
#将tab转成多少个空格
prnt(name.expandtabs(tabsize=30))
#查找字符下标
print(name.find("y"))
#格式化map
print(name.format_map({'name':'xia'}))
#判断是否是字母或数字包含小数
print(name.isalnum())
#判断是否纯字母
print(name.isalpha())
#判断是否是十进制
print(name.isdecimal())
#判断是否是整数
print(name.isdigit())
#判断是不是一个合法的标识符(变量名)
print(name.isidentifier())
#判断是否全部小写
print(name.islower())
#判断是否全部大写
print(name.isupper())
#join将列表变为字符串
print(','.join(['1','2','3']))#结果为1,2,3
#长度不足50右边以*填充
print(name.ljust(50,'*'))
#长度不足50左边以*填充
print(name.rjust(50,'*'))
#去除空格和回车
print('\nalex'.strip())
#将字符串转换成对应值
p=str.maketrans('abcdef','123456')
print('a'.translate(p))
#结果为 1
#替换
print('a'.replace('a','b',1))
#找到最右边的值下标,前面有的忽略
print('alex lil'.rfind('l'))
#结果为7
#分割成列表
print('a b'.split(' '))
#大写变小写,小写变大写
pritn('abdcA'。swapcase())
#不够左边0填充
print('a'.zfill(50))