0. 组合数据类型的基本概念
定义: 能够表示多个数据的类型称为组合数据类型。
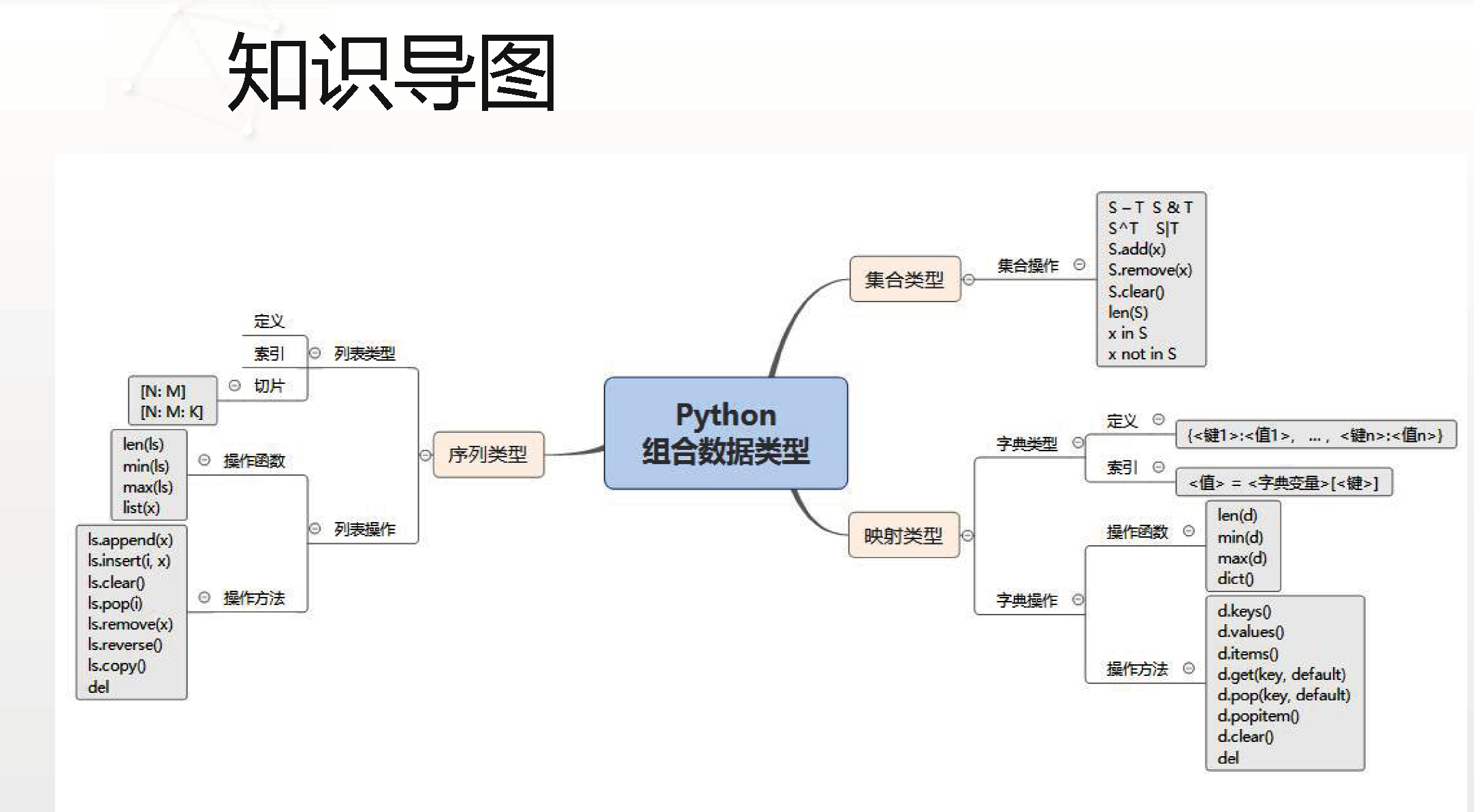
组合数据类型分类: 集合类型;序列类型;映射类型。
集合类型: 是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
序列类型: 是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他,可重复。序列类型的典型代表是字符串类型和列表类型。
映射类型是:“键-值”数据项的组合,每个元素是一个键值对,表示为(key, value)。映射类型的典型代表是字典类型。
0.1 集合类型操作函数或方法
| 函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项x不在集合S中,将x增加到s |
| S.remove(x) | 如果x在集合S中,移除该元素;不在产生KeyError异常 |
| S.clear() | 移除S中所有数据项 |
| len(S) | 返回集合S元素个数 |
| x in S | 如果x是S的元素,返回True,否则返回False |
| x not in S | 如果x不是S的元素,返回True,否则返回False |
0.2 序列类型的操作符和函数
| 操作符 | 描述 |
|---|---|
| x in s | 如果x是s的元素,返回True,否则返回False |
| x not in s | 如果x不是s的元素,返回True,否则返回False |
| s + t | 连接s和t |
| s * n 或 n * s | 将序列s复制n次 |
| s[i] | 索引,返回序列的第i个元素 |
| s[i: j] | 切片,返回包含序列s第i到j个元素的子序列(不包含第j个元素) |
| s[i: j: k] | 步骤切片,返回包含序列s第i到j个元素以j为步数的子序列 |
| len(s) | 序列s的元素个数(长度) |
| min(s) | 序列s中的最小元素 |
| max(s) | 序列s中的最大元素 |
| s.index(x) | 序列s中第一次出现元素x的位置 |
| s.count(x) | 序列s中出现x的总次数 |
1 集合
1.1 定义
Python语言中的集合类型与数学中的集合概念一致,即包含0个或多个数据项的无序组合。集合是无序组合,用大括号"{}"表示,它没有索引和位置的概念,集合中元素可以动态增加或删除。
集合(set)是可变,无序,不重复的元素的集合
1.2 集合的操作
- 集合初始化定义:
s1 = set()
s2 = {1,2,3}
s5 = set(range(5))
- 集合类型有一些常用的操作函数或方法
| 函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项x不在集合S中,将x增加到s |
| S.remove(x)★ | 如果x在集合S中,移除该元素;不存在则KeyError异常 |
| S.discard(x)★ | 存在x则移除,不存在则不报错,不改变原来的集合 |
| S.clear() | 移除S中所有数据项 |
| len(S) | 返回集合S元素个数 |
| x in S | 如果x是S的元素,返回True,否则返回False |
| x not in S | 如果x不是S的元素,返回True,否则返回False |
| set.pop() | 任意移除一个元素,并返回移除的元素. |
- 集合的操作符
集合类型有4个操作符,交集(&).并集(|).差集(-).补集(^),操作逻辑与数学定义相同。

| 操作符的运算 | 描述 |
|---|---|
| S – T | 返回一个新集合,包括在集合S中但不在集合T中的元素 |
| S & T | 返回一个新集合,包括同时在集合S和T中的元素 |
| S ^ T | 返回一个新集合,包括集合S和T中非共同元素 |
| S | T | 返回一个新集合,包括集合S和T中所有元素 |
1.3 集合成员运算符比较
线性结构的查询时间复杂度是O(n),即随着数据规模的增大而增大耗时.
set,dict 等结构,内部使用hash 值作为key,时间复杂度可以做到O(1),查询时间与数据规模无关.
示例:
n1 = 100
n2=1000000
l1= list(range(n1))
l2=list(range(n2))
s1= set(range(n1))
s2=set(range(n2))
%timeit (-1 in l1)
>>>2.02 µs ± 53.9 ns
%timeit (-1 in l2)
>>>19.9 ms ± 293 µs
%timeit (-1 in s1)
>>>106 ns ± 2.06 ns
%timeit (-1 in s2)
>>>97.8 ns ± 0.964 ns
由上可以看出,判断某个数是否在所列数据结构中,用集合检索的速度远远快于列表.其时间复杂度为O(1).
这里主要运用到了hash.第一步就是对元素进行hash,如果存在则hash值不变,如果不存在则可以进行hash,因此查找是否存在只需要操作一次便可完成,所以其速度非常快,故可以应用于元素的检索中.
以下都是不可变类型,是可哈希类型,hashable
int,float,complex #数值型
True,False #布尔型
string,bytes #字符串
tuple
None
2. 列表类型
2.1 列表定义
列表是包含0个或多个元组组成的有序序列,属于序列类型。列表可以进行元素增加,删除,替换,查找等操作。列表没有长度限制,元素类型可以不同,不需要预定义长度。
列表类型用中括号"[]"表示,也可以通过list(x)
函数将集合或字符串类型转换成列表类型。
2.1.1列表的操作函数
| 操作函数 | 描述 |
|---|---|
| len(ls) | 列表ls的元素个数(长度) |
| min(ls) | 列表ls中的最小元素 |
| max(ls) | 列表ls中的最大元素 |
| list(x) | 将x转变成列表类型 |
2.1.2 列表操作方法
| 方法 | 描述 |
|---|---|
| ls.append(x) | 在列表ls最后增加一个元素x O(1) |
| ls.insert(i, x) | 在列表ls第i位置增加元素x |
| ls.clear() | 删除ls中所有元素 |
| ls.pop(i) | 将列表ls中第i项元素取出并删除该元素O(n) |
| ls.remove(x) | 将列表中出现的第一个元素x删除O(n) |
| ls.reverse()★ | 列表ls中元素反转 |
| ls.copy() | 生成一个新列表,复制ls中所有元素 |
| ls.extend() | 在原列表尾部连续追加多个元素 |
| ls.index() | 返回s中第一次出现元素x的位置O(1) |
| ls.sort() | 对列表元素进行排序 当reverse =True 时反转降序 |
| ls1 +ls2 | 生成一个新的列表,两个列表尾部相加(但重新分配内存,空间复杂度高) |
-
01特例ls.copy
list1 = [1,[1,2,3],4] list2 = list1.copy() list[1][1] =5 lsit1 = list2 ?
答案是相等。
列表拷贝为浅拷贝,只拷贝了地址,故后期修改地址内的数据被复制列表也会作相应的修改。
若想完整拷贝需要倒入库进行深拷贝:
import copy :
list1 = list0.copy.deepcopy()
这个进行的拷贝就会完整复制所有数据。
同样:
list2 = [1,2,3]
list3 = list2 *3
这种也是浅拷贝,修改一个数据,后面的数据同样更改。慎用!!!!
- 02特例ls.sort()
ls1=[1,2,4,5,"3"]
ls1.sort()#会报错,但是使用
ls1.sort(key=int) #可以将列表的类型改为相同格式,使排序成立。
>>>ls1=[1,2,"3",4,5]#不修改列表中原格式
3.元组
3.1 定义:
元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。
元组类型一旦定义就不能修改,在编程中不够灵活,同时,元组类型的所有操作都可以由列表类型实现。因此,如果需要自定义变量,通常以列表类型代替元组类型使用。如果确认编程中不需要修改数据,可以使用元组类型。
3.2 元组的常用操作:
t1=(1,) #一个元组的写法:加","区分
ls = [1,2,3,4]
t2=tuple(ls)
>>(1,2,3,4)
元组一旦创立变不可更改,但是创建的元组内含有引用地址的则可以修改引用地址内的数据,如:
t3 = (1,[2,3,4],'a',None)
t3[1][0]= 5
>>> (1,[5,3,4]],'a',None)
引用类型,注意元组引用地址
- namedtuple
对于namedtuple,你不必再通过索引值进行访问,你可以把它看做一个字典通过名字进行访问,只不过其中的值是不能改变的。
例:
from collections import namedtuple
Point= namedtuple('Point',['x','y'])
type(Point)
>> type #Point 是一个类型
p1=Point(4,5)
print(p1)
>>Point(x=4, y=5)
Point(x=20,y=10)
p1.x p2.y
>>(20,10)
Student = namedtuple('Stu','name,age')
Student
>>'__main__.s' #为标识符,名字为S ,名字给人看的,程序员使用标识符
tom = Student('tom',20)
tom
>>Stu(neme='tom',age=20)
jerry = Student('Jerry',18)
jerry
>> Stu(name='Jerry',agr = 18)
#其他:
x =4
y=10
s1=f"{x}-->{y}
s1
>>'4-->10'
s2=f'{P1}’ #
>>'Point(x=4,y=5)'
4. 字符串
4.1 定义:
字符串是字符的序列表示,根据字符串的内容多少分为单行字符串和多行字符串。
单行字符串可以由一对单引号(’)或双引号(")作为边界来表示,单引号和双引号作用相同。
多行字符串可以由一对三单引号(’’’)或三双引号(""")作为边界来表示,两者作用相同。
4.2 字符串的常用操作:
字符串操作符
| 操作符 | 描述 |
|---|---|
| x + y | 连接两个字符串x与y |
| x * n 或 n * x | 复制n次字符串x |
| x in s | 如果x是s的子串,返回True,否则返回False |
字符串处理函数
| 函数 | 描述 |
|---|---|
| len(x) | 返回字符串x的长度,也可返回其他组合数据类型的元素个数 |
| str(x) | 返回任意类型x所对应的字符串形式 |
| chr(x) | 返回Unicode编码x对应的单字符 |
| ord(x) | 返回单字符x表示的Unicode编码 |
| hex(x) | 返回整数x对应十六进制数的小写形式字符串 |
| oct(x) | 返回整数x对应八进制数的小写形式字符串 |
字符串处理方法
| 方法 | 描述 |
|---|---|
| str.lower() | 返回字符串str的副本,全部字符小写 |
| str.upper() | 返回字符串str的副本,全部字符大写 |
| str.split(sep=None) | 返回一个列表,由str根据sep被分割的部分构成 |
| str.count(sub) | 返回sub子串出现的次数 |
| str.replace(old, new) | 返回字符串str的副本,所有old子串被替换为new |
| str.center(width, fillchar) ★ | 字符串居中函数,fillchar参数可选 |
| str.strip(chars) | 从字符串str中去掉在其左侧和右侧chars中列出的字符 |
| str.join(iter)★ | 将iter变量的每一个元素后增加一个str字符串 |
字符串操作
- join 操作
示例:
":".join(map(str,range(9))) #map(str,abc) #map将abc转为字符串格式
>>'0:1:2:3:4:5:6:7:8'
"*".join('abcd')
>>'a*b*c*d'
"*".join(['abcdef']) #列表内元素看成一个整体
>>'abcdef'
s1='a,b,c,d,e'
s1='afsdff'
"*".join(s1) #在每一个字符后面增加一个*
>>>'a*f*s*d*f*f'
- 字符串分割
**s1.split(',')**
>>['a', 'b', 'c', 'd', 'e'] --> #以","进行分割,立即返回一个列表
s.split(maxsplit=2) -->#默认分割几次,默认以最大空格进行切
s.rsplit() #--->反向切片
★s.splitlines()#--->安照换行符进行分割
★ s.partition(',') #--->切一次,立即返回一个三元组 s.replace(old,new[,count])--> 替代
s3='a,b,c,d,e'
s3.parttition(',') #>>>('a',',','b,c,d,e') #常用于切头去尾。
s.tittle() #英文首字母大写
s.capitalize() #英文第一个字母大写
s.center(30,'*') #居中填充 不足的*补齐
s=' I am very very very very sorry '
s.strip("a") #去掉两头的"a"字符
s.stirp()
>> I am very very very very sorry
s.strip(' \t\nmai') # --->去掉后面出现的字符,直到第一个非出现字符
>>>'very very very sorry'
s.find()#---->找到返回正索引,找不到怎返回-1
s.startswith('',0,-3) #--->可加区间的前缀和后缀
s.endswith() # 判断字符串是否已给出字符串结尾
#字符串is系列操作,返回值都是bool类型,是返回True,否则返回False
isalnum() #是否是字母和数字组成
isalpha() #是否是字母
isdecimal() #是否只包含十进制数字
isdigit() #是否全部数字(0~9)
isidentifier() #是不是字母和下划线开头,其他都是字母.数字.下划线
islower() #是否都是小写
isupper() #是否全部大写
isspace() #是否只包含空白字符
字符串格式化:
format函数 ---python常用
format()方法的格式控制:
| : | <填 充> | <对 齐> | <宽 度> | <,> | <.精度> | 类型 |
|---|---|---|---|---|---|---|
| 引导符号 | 用于填充的 单个字符 | <左对齐> 右对齐 ^ 居中 | 槽的设定输入宽度 | 数字的千位分隔符适用于整数和浮点数 | 浮点数小数部分的精度或字符串的最大输出长度 | 整数类型b,c,d,o,x,X 浮点数类型 |
octets =[192,168,160,1]
print("{:02x}{:02x}{:02x}{:02x}".format(*octets))
>>c0a8a001 #参数解构
输出IP地址的16进制格式
5 字典
5.1 定义:
“键值对”是组织数据的一种重要方式,广泛应用在Web系统中。键值对的基本思想是将“值”信息关联一个“键”信息,进而通过键信息查找对应值信息,这个过程叫映射。Python语言中
通过字典类型实现映射。
Python语言中的字典使用大括号{}建立,每个元
素是一个键值对,使用方式如下:
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
其中,键和值通过冒号连接,不同键值对通过逗号隔开。字典类型也具有和集合类似的性质,即键值对之间没有顺序且不能重复。
总之一句话: 字典是可变,无序,key不能重复;
5.2 字典初始化定义:
d = dict() 或者d = {}
dict(**kwargs) #使用name=value对初始化一个字典
dict(a=5)
>>>{'a': 5}
dict(iterable, **kwarg) #使用可迭代对象和name=value对构造字典,不过可迭代对象的元素必须是一个二元结构
d = dict(((1,'a'),(2,'b'))) 或者d = dict(([1,'a'],[2,'b'])) #最外面一个括号表示dict()里面一个括号表示元组的括号,最里面一个括号表示元组,是可迭代对象,所以扩号一个不能少.
>>>{1: 'a', 2: 'b'}
d=dict([[1,2],(2,3)])
>>>{1:2,2:3}
dict(mapping, **kwarg) # 使用一个字典构建另一个字典
dict(d,a=3,b=4)
>>>{1: 'a', 2: 'b', 'a': 3, 'b': 4}
d = {'a':10, 'b':20, 'c':None, 'd':[1,2,3]}#直接用键值对构建,经常使用,键值对的类型不一定要求都是一致,可任意组配
类方法dict.fromkeys(iterable, [value])
d = dict.fromkeys(range(5)) #加可迭代对象,不加value值则键的值为None即缺省为None
>>>{0: None, 1: None, 2: None, 3: None, 4: None}
d = dict.fromkeys(range(5),0)
>>>{0: 0, 1: 0, 2: 0, 3: 0, 4: 0}# 返回给定的defult值
ls = [1]
d8=dict.fromkeys(range(5),ls)
ls.append(2)
print(d8)
>>>{0: [1,2], 1: [1,2], 2: [1,2], 3:[1,2], 4: [1,2],}
5.3 字典元素的访问:
| 描述 | 操作 |
|---|---|
| d[key] | 返回key对应的值value;key不存在抛出KeyError异常,返回数据类型为dict_values |
| get(key[, default])★ | 返回key对应的值value;key不存在返回缺省值,如果没有设置缺省值就返回None |
| setdefault(key[, default])★ | 返回key对应的值value ;key不存在,添加kv对,value设置为default,并返回default,如果default没有设置,缺省为None |
举例:
d = {"201801":"小明", "201802":"小红", "201803":"小白"}
print(d["201802"]) #返回键对应的值
>>>小红
d.get("201804",'None')#返回key对应的值value
>>>'None'
d.setdefault("201804",'None')#key不存在则将原来的字典进行修改,与get不同.
>>>'None'
print(d)
>>>{'201801': '小明', '201802': '小红', '201803': '小白', '201804': 'None'}
5.4 字典元素的修改:
| 描述 | 操作 |
|---|---|
| d[key] = value | 将key对应的值修改为value;key不存在添加新的kv对; |
| d.values() | 返回所有的值信息; 类型为dict_values |
| d.items() | 返回所有的键值对; 类型为dict_items |
| update([other]) | 返回None,使用另一个字典的kv对更新本字典;key不存在,就添加,key存在,覆盖已经存在的key对应的值,就地修改 |
| pop(key[, default]) | key存在,移除它,并返回它的value;key不存在,返回给定的default;default未设置,key不存在则抛出KeyError异常 |
| popitem()★ | 移除并返回一个任意的键值对;字典为empty,抛出KeyError异常 |
| clear() | 清空字典 |
| del | 删除字典中元素,若计数为0则内存清空 |
注意;在列表中:
☆☆☆ list.pop()则是从列表末尾删除并返回值,因为列表是有序的,但字典为无序,所以这里的pop不给定值就会抛异常.
举例:
d.update(red=1) #用标识符加一个值.
d.update((('red',2),)) # 注意括号个数与括号内容!! # 这里一定要使用二元元组表示
d.update({'red':3})
>>> {'201801': '小明', '201802': '小红', '201803': '小白', '201804': 'None', 'red': 1}
del d['201801] #删除KV对
a True
b=[6]
d2={'a':a,'b':b,'c':[1,2,3]}
del d2['b']
>>>b的引用计数少1,但b=[6]依旧存在,所以内存还存在
5.5 字典元素的遍历:
- for 循环遍历
#(1) 遍历key
for k in d:
print(k)
for k in d.keys():
print(k)
#(2)遍历value
for k in d:
print(d[k])
for k in d.keys():
print(d.get(k))
for v in d.values():
print(v)
#(3)键值对遍历; 即KV对
for item in d.items():
print(item) # 返回元组tuple类型
for item in d.items():
print(item[0], item[1]) #返回字符串类型
for k,v in d.items(): #解构
print(k, v)
for k, _ in d.items(): #返回key
print(k) #上下两种方法参数的结构
for _ ,v in d.items(): #返回value,下划线"_"表示不需要,在解构中尽可能多的收集数据
print(v)

注意:
在遍历元素的过程中,使用key寻找与value都是一样的操作!!!但凡是遍历,就没有快的,元素多的,能不遍历就不遍历,能一遍遍历的不要两边遍历.
- del 操作
del d8[1]#删除字典元素,存在则可以删,首先遍历遍字典 不存在则报错
小结:
Python3中,keys.values.items方法返回一个类似一个生成器的可迭代对象,不会把函数的返回结果复制到内存中
返回Dictionary view对象,(操作的还是原来的字典)可以使用len().iter().in操作
字典的entry的动态的视图,字典变化,视图将反映出这些变化
keys返回一个类set对象,也就是可以看做一个set集合。
如果values都可以hash,那么items也可以看做是类set对象
Python2中,上面的方法会返回一个新的列表,占据新的内存空间。所以Python2建议使用iterkeys.itervalues.iteritems版本,返回一个迭代器,而不是返回一个copy
5.6字典的特殊操作:
- defaultdict
collections.defaultdict([default_factory[, …]])
1)第一个参数是default_factory,缺省是None,它提供一个初始化函数。当key不存在的时候,会调用这个工厂函数来生成key对应的value
2)构造一个字典,values是列表,为其添加随机个元素
import random
from collections import defaultdict
random.seed(20)
# d1={}
d1 = defaultdict(list)#缺省字典,当不存在时则调用缺省工厂,生成KV对,然后就可以继续添加,不抛keyerror
for k in 'abcdef':
for v in range(random.randint(1, 5)):
# if k not in d1.keys(): #写法一用if 判断是否存在
# d1[k] = []
d1[k].append(v)# #缺省字典,当不存在时则调用缺省工厂,生成KV对,然后就可以继续添加,不抛keyerror
# d1.get(k,[]).append(v) #写法二当初始k不存在时,创建一个空列表,与if类似 ,但这里不能使用,因为创建的列表是临时的.
# d1.setdefault(k,[]).append(v)#写法三,用setdefaultdict 创建新的列表
print(d1)
- OrderedDict
# 在puython3.6版本以前,字典插入的顺序是无序的,因此输出是无序的,要想记录插入顺序,则要使用OrderedDict()来记录字典插入的顺序,避免后期在索引字典KV值时,无须先按照插入顺序进行排序,而是直接索引就可以.这样极大的减少了因排序的时间.
collections.OrderedDict([items])
#key并不是按照加入的顺序排列,可以使用OrderedDict记录顺序
from collections import OrderedDict #导入OrderedDict
import random
d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}
print(d)
#在python3.6版本以前,不加Ordereddict顺序是随机的.
keys = list(d.keys())#单用d.keys()返回的是dict_keys()所以加lsit转化为列表
random.shuffle(keys) # 打乱顺序
print(keys)
od = OrderedDict() # 生成空字典
for key in keys:
od[key] = d[key]
print(od)
print(od.keys())
>>>{'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}
>>>['pear', 'apple', 'banana', 'orange']
>>>OrderedDict([('pear', 1), ('apple', 4), ('banana', 3), ('orange', 2)])# 返回类似列表值的形式来记录插入KV对的顺序.
>>>odict_keys(['pear', 'apple', 'banana', 'orange'])
应用场景:
假如使用字典记录了N个产品,这些产品使用ID由小到大加入到字典中除了使用字典检索的遍历,有时候需要取出ID,但是希望是按照输入的顺序,因为输入顺序是有序的否则还需要重新把遍历到的值排序
总结:
写完这章,Python的基本语法就搞定了,然而似乎python的重点在于它各种各样的库,接下来就是整理python常见的库开发了,以及,库和这些基本语法搭配起来一起使用,更好的去解决问题。
附录:
数据类型的比较
| 比较项 | 列表 | 元组 | 字典 | 集合 |
|---|---|---|---|---|
| 类型 | list | tuple | dict | set |
| 定界符 | [ ] | ( ) | { } | { } |
| 是否可变 | √ | x | √ | √ |
| 是否有序 | √ | √ | x | x |
| 是否支持下标 | √ | √ | √ | x |
| 元素分隔符 | , | , | , | , |
| 对元素形式要求 | 无 | 无 | 键:值 | 必须可哈希 |
| 对元素值要求 | 无 | 无 | 键必须可哈希 | 必须可哈希 |
| 是否可重复 | 是 | 是 | 链不重复,值可以重复 | 否 |
| 查找速度 | 非常慢 | 很慢 | 非常快 | 非常快 |
| 新增和删除速度 | 尾部操作快,其他慢 | 不允许 | 快 | 快 |
补充:
列表: 在内存存储空间是连续的,但是增减数据繁琐。
链 : 链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。由上一个数据知道下一个数据。增删元素方便
队列: 不允许在中间变化 先进先出,后进先出
stack: 栈 -> 后进先出