版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/xyy1028/article/details/86474298
1.引入numpy模块
import numpy一.loadtxt() 读取csv文件
对该scv文件操作为例

1.dtype 参数指定读取类型
myMatrix = numpy.loadtxt(
"D:\why.csv",
dtype=str)
print myMatrix输出;
['Name,age,sex' 'why,18,female' 'xyz,19,female' 'hehe,20,male'
'&,120,emale' 'haha,21,male']2.delimiter指定定界符
myMatrix = numpy.loadtxt("D:\why.csv",
dtype=str,
delimiter=",")
print myMatrix输出:
[['Name' 'age' 'sex']
['why' '18' 'female']
['xyz' '19' 'female']
['hehe' '20' 'male']
['&' '120' 'emale']
['haha' '21' 'male']]3.comments 参数指定当以某字符开头时,跳过该行
myMatrix = numpy.loadtxt("D:\why.csv",
dtype=str,
delimiter=",",
comments="&")
print myMatrix输出:
[['Name' 'age' 'sex']
['why' '18' 'female']
['xyz' '19' 'female']
['hehe' '20' 'male']
['haha' '21' 'male']]4.skiprows 参数指定从第几行开始
myMatrix = numpy.loadtxt("D:\why.csv",
dtype=str,
delimiter=",",
comments="&",
skiprows=1)
print myMatrix输出:
[['why' '18' 'female']
['xyz' '19' 'female']
['hehe' '20' 'male']
['haha' '21' 'male']]
5. usecols参数只使用指定列
myMatrix = numpy.loadtxt("D:\why.csv",
dtype=str,
delimiter=",",
usecols=(1,2),
)
print myMatrix输出:
[['age' 'sex']
['18' 'female']
['19' 'female']
['20' 'male']
['120' 'emale']
['21' 'male']]6. converters参数,对该行进行操作
myMatrix = numpy.loadtxt("D:\why.csv",
dtype=str,
delimiter=",",
skiprows=1,
converters={1: lambda i: int(i) + 1}
)
print myMatrix输出:
[['why' '19' 'female']
['xyz' '20' 'female']
['hehe' '21' 'male']
['&' '121' 'emale']
['haha' '22' 'male']]7. unpack参数把所有列当成向量格式输出
myMatrix = numpy.loadtxt("D:\why.csv",
dtype=str,
delimiter=",",
unpack=True
)
for i in myMatrix:
print i输出:
['Name' 'why' 'xyz' 'hehe' '&' 'haha']
['age' '18' '19' '20' '120' '21']
['sex' 'female' 'female' 'male' 'emale' 'male']8.ndmin 返回的数组至少具备的维度,默认为0,可选值 1或2
myMatrix = numpy.loadtxt("D:\why.csv",
dtype=str,
delimiter=",",
ndmin=1)
print myMatrix输出:
[['Name' 'age' 'sex']
['why' '18' 'female']
['xyz' '19' 'female']
['hehe' '20' 'male']
['&' '120' 'emale']
['haha' '21' 'male']]二.savetxt()方法
savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='',
footer='', comments='# ', encoding=None)
# 1.fname 指定保存到的文件名
# 2.X 存入的数组
# 3. fmt 写入文件中的每个字符串格式
# 如: %s:ASCII字符
# %d: 整数
# %.2f:2位小数的浮点数
# %.18e:科学计数法
# 4.delimiter 分隔符
# 5.newline 分行负,"\n代表换行"1.常规写入(行列固定个数)
a = [['Name', 'age', 'sex'],
['why', '18', 'female'],
['xyz', '19', 'female'],
['hehe', '20', 'male'],
['&', '120', 'emale'],
['haha', '21', 'male']]
numpy.savetxt("D:/why2.csv", a, fmt='%s', delimiter=',', newline='\n', header='',
footer='', comments='# ', encoding=None)输出:

2.列不齐写入(有bug,第一个单元格与最后一个有中括号)
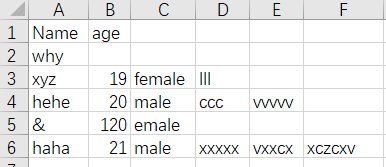
a = [['Name', 'age'],
['why'],
['xyz', '19', 'female', 'lll'],
['hehe', '20', 'male', 'ccc', 'vvvvv'],
['&', '120', 'emale'],
['haha', '21', 'male', 'xxxxx', 'vxxcx', 'xczcxv']]
hehe = []
for i in a:
hehe.append(str(i))
numpy.savetxt("D:/why2.csv", hehe, fmt='%s', delimiter=',')输出:

3.采用 pandas模块写入列不齐数据
import pandas as pd
a = [['Name', 'age'],
['why'],
['xyz', '19', 'female', 'lll'],
['hehe', '20', 'male', 'ccc', 'vvvvv'],
['&', '120', 'emale'],
['haha', '21', 'male', 'xxxxx', 'vxxcx', 'xczcxv']]
# 该处index可以指定行名
test = pd.DataFrame(columns=None, data=a)
print(test)
# 该处index可以取消行名
test.to_csv('D:/testcsv.csv', encoding='gbk', index=False, header=None)# header=None即去掉列名输出: