开发者在面对 kubernetes 分布式集群下的日志需求时,常常会感到头疼,既有容器自身特性的原因,也有现有日志采集工具的桎梏,主要包括:
- 容器本身特性:
- 采集目标多:容器本身的特性导致采集目标多,需要采集容器内日志、容器 stdout。对于容器内部的文件日志采集,现在并没有一个很好的工具能够去动态发现采集。针对每种数据源都有对应的采集软件,但缺乏一站式的工具。
- 弹性伸缩难:kubernetes 是分布式的集群,服务、环境的弹性伸缩对于日志采集带来了很大的困难,无法像传统虚拟机环境下那样,事先配置好日志的采集路径等信息,采集的动态性以及数据完整性是非常大的挑战。
- 现有日志工具的一些缺陷:
- 缺乏动态配置的能力。目前的采集工具都需要事先手动配置好日志采集方式和路径等信息,因为它无法能够自动感知到容器的生命周期变化或者动态漂移,所以它无法动态地去配置。
- 日志采集重复或丢失的问题。因为现在的一些采集工具基本上是通过 tail 的方式来进行日志采集的,那么这里就可能存在两个方面的问题:一个是可能导致日志丢失,比如采集工具在重启的过程中,而应用依然在写日志,那么就有可能导致这个窗口期的日志丢失;而对于这种情况一般保守的做法就是,默认往前多采集 1M 日志或 2M 的日志,那么这就又会可能引起日志采集重复的问题。
- 未明确标记日志源。因为一个应用可能有很多个容器,输出的应用日志也是一样的,那么当我们将所有应用日志收集到统一日志存储后端时,在搜索日志的时候,我们就无法明确这条日志具体是哪一个节点上的哪一个应用容器产生的。
本文档将介绍一种 Docker 日志收集工具 log-pilot,结合 Elasticsearch 和 kibana 等工具,形成一套适用于 kubernetes 环境下的一站式日志解决方案。
log-pilot 介绍
log-Pilot 是一个智能容器日志采集工具,它不仅能够高效便捷地将容器日志采集输出到多种存储日志后端,同时还能够动态地发现和采集容器内部的日志文件。
针对前面提出的日志采集难题,log-pilot 通过声明式配置实现强大的容器事件管理,可同时获取容器标准输出和内部文件日志,解决了动态伸缩问题,此外,log-pilot 具有自动发现机制,CheckPoint 及句柄保持的机制,自动日志数据打标,有效应对动态配置、日志重复和丢失以及日志源标记等问题。
目前 log-pilot 在 Github 完全开源,项目地址是 https://github.com/AliyunContainerService/log-pilot 。您可以深入了解更多实现原理。
针对容器日志的声明式配置
Log-Pilot 支持容器事件管理,它能够动态地监听容器的事件变化,然后依据容器的标签来进行解析,生成日志采集配置文件,然后交由采集插件来进行日志采集。
在 kubernetes 下,Log-Pilot 可以依据环境变量 aliyun_logs_$name = $path 动态地生成日志采集配置文件,其中包含两个变量:
- $name 是我们自定义的一个字符串,它在不同的场景下指代不同的含义,在本场景中,将日志采集到 ElasticSearch 的时候,这个 $name 表示的是 Index。
- 另一个是 $path,支持两种输入形式,stdout 和容器内部日志文件的路径,对应日志标准输出和容器内的日志文件。
- 第一种约定关键字 stdout 表示的是采集容器的标准输出日志,如本例中我们要采集 tomcat 容器日志,那么我们通过配置标签
aliyun.logs.catalina=stdout来采集 tomcat 标准输出日志。 - 第二种是容器内部日志文件的路径,也支持通配符的方式,通过配置环境变量
aliyun_logs_access=/usr/local/tomcat/logs/*.log来采集 tomcat 容器内部的日志。当然如果你不想使用 aliyun 这个关键字,Log-Pilot 也提供了环境变量 PILOT_LOG_PREFIX 可以指定自己的声明式日志配置前缀,比如PILOT_LOG_PREFIX: "aliyun,custom"。
- 第一种约定关键字 stdout 表示的是采集容器的标准输出日志,如本例中我们要采集 tomcat 容器日志,那么我们通过配置标签
此外,Log-Pilot 还支持多种日志解析格式,通过 aliyun_logs_$name_format=<format> 标签就可以告诉 Log-Pilot 在采集日志的时候,同时以什么样的格式来解析日志记录,支持的格式包括:none、json、csv、nginx、apache2 和 regxp。
Log-Pilot 同时支持自定义 tag,我们可以在环境变量里配置 aliyun_logs_$name_tags="K1=V1,K2=V2",那么在采集日志的时候也会将 K1=V1 和 K2=V2 采集到容器的日志输出中。自定义 tag 可帮助您给日志产生的环境打上 tag,方便进行日志统计、日志路由和日志过滤。
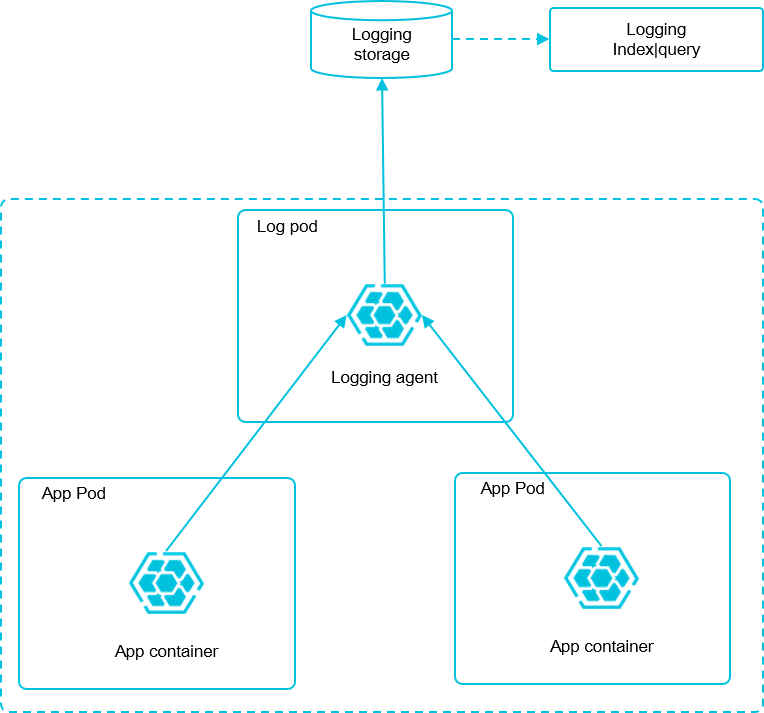
日志采集模式
本文档采用 node 方式进行部署,通过在每台机器上部署一个 log-pilot 实例,收集机器上所有 Docker 应用日志。
前提条件
您已经开通容器服务,并创建了一个 kubernetes 集群。本示例中,创建的 Kubernetes 集群位于华东 1 地域。
步骤1 部署 elasticsearch
- 连接到您的 Kubernetes 集群。具体操作参见通过SSH访问Kubernetes集群 或 通过 kubectl 连接 Kubernetes 集群。
- 首先部署 elasticsearch 相关服务,该编排模板包含一个 elasticsearch-api 的服务、elasticsearch-discovery 的服务和 elasticsearch 的状态集,这些对象都会部署在 kube-system 命名空间下。
kubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/elasticsearch.yml - 部署成功后,kube-system 命名空间下会出现相关对象,执行以下命令查看运行情况。
$ kubectl get svc,StatefulSet -n=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch-api ClusterIP 172.21.5.134 <none> 9200/TCP 22h svc/elasticsearch-discovery ClusterIP 172.21.13.91 <none> 9300/TCP 22h ... NAME DESIRED CURRENT AGE statefulsets/elasticsearch 3 3 22h
步骤2 部署 log-pilot 和 kibana 服务
- 部署 log-pilot 日志采集工具,如下所示:
kubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/log-pilot.yml - 部署 kibana 服务,该编排示例包含一个 service 和一个 deployment。
kubectl apply -f https://acs-logging.oss-cn-hangzhou.aliyuncs.com/kibana.yml
步骤3 部署测试应用 tomcat
在 elasticsearch + log-pilot + Kibana 这套日志工具部署完毕后,现在开始部署一个日志测试应用 tomcat,来测试日志是否能正常采集、索引和显示。
编排模板如下。
apiVersion: v1
kind: Pod
metadata:
name: tomcat namespace: default labels: name: tomcat spec: containers: - image: tomcat name: tomcat-test volumeMounts: - mountPath: /usr/local/tomcat/logs name: accesslogs env: - name: aliyun_logs_catalina value: "stdout" ##采集标准输出日志 - name: aliyun_logs_access value: "/usr/local/tomcat/logs/catalina.*.log" ## 采集容器内日志文件 volumes: - name: accesslogs emptyDir: {}tomcat 镜像属于少数同时使用了 stdout 和文件日志的 Docker 镜像,适合本文档的演示。在上面的编排中,通过在 pod 中定义环境变量的方式,动态地生成日志采集配置文件,环境变量的具体说明如下:
aliyun_logs_catalina=stdout表示要收集容器的 stdout 日志。aliyun_logs_access=/usr/local/tomcat/logs/catalina.*.log表示要收集容器内 /usr/local/tomcat/logs/ 目录下所有名字匹配 catalina.*.log 的文件日志。
在本方案的 elasticsearch 场景下,环境变量中的 $name 表示 Index,本例中 $name即是 catalina 和 access 。
步骤 4 将 kibana 服务暴露到公网
上面部署的 kibana 服务的类型采用 NodePort,默认情况下,不能从公网进行访问,因此本文档配置一个 ingress 实现公网访问 kibana,来测试日志数据是否正常索引和显示。
- 通过配置 ingress 来实现公网下访问 kibana 。本示例选择简单的路由服务来实现,您可参考Ingress 支持 获取更多方法。该 ingress 的编排模板如下所示。
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kibana-ingress namespace: kube-system #要与 kibana 服务处于同一个 namespace spec: rules: - http: paths: - path: / backend: serviceName: kibana #输入 kibana 服务的名称 servicePort: 80 #输入 kibana 服务暴露的端口 - 创建成功后,执行以下命令,获取该 ingress 的访问地址。
$ kubectl get ingress -n=kube-system NAME HOSTS ADDRESS PORTS AGE shared-dns * 120.55.150.30 80 5m - 在浏览器中访问该地址,如下所示。
- 单击左侧导航栏中的management ,然后单击
您也可以执行以下命令,进入 elasticsearch 对应的 pod,在 index 下列出 elasticsearch 的所有索引。
$ kubectl get pods -n=kube-system #找到 elasticsearch 对应的 pod ... $ kubectl exec -it elasticsearch-1 bash #进入 elasticsearch 的一个 pod ... $ curl 'localhost:9200/_cat/indices?v' ## 列出所有索引 health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .kibana x06jj19PS4Cim6Ajo51PWg 1 1 4 0 53.6kb 26.8kb green open access-2018.03.19 txd3tG-NR6-guqmMEKKzEw 5 1 143 0 823.5kb 411.7kb green open catalina-2018.03.19 ZgtWd16FQ7qqJNNWXxFPcQ 5 1 143 0 915.5kb 457.5kb - 索引创建完毕后,单击左侧导航栏中的Discover,然后选择前面创建的 Index,选择合适的时间段,在搜索栏输入相关字段,就可以查询相关的日志。
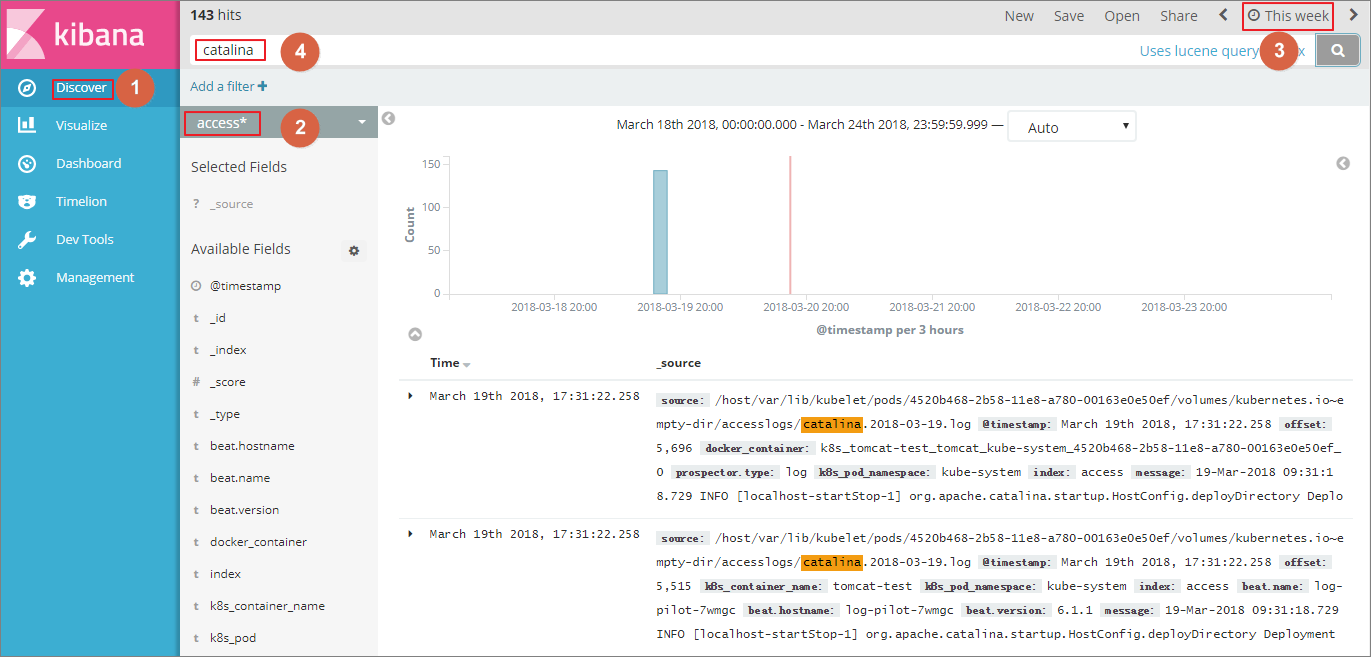
至此,在阿里云 Kubernetes 集群上,我们已经成功测试基于 log-pilot、elasticsearch 和 kibana 的日志解决方案,通过这个方案,我们能有效应对分布式 kubernetes 集群日志需求,可以帮助提升运维和运营效率,保障系统持续稳定运行。