tf.nn.sparse_softmax_cross_entropy_with_logits(
_sentinel=None,
labels=None, #参数labels表示实际标签值,大小为[batch_size,num_classes]
logits=None, #参数logits为神经网络最后一层的输出,它的大小为[batch_size, num_classes]
name=None #可选参数
)解析:此函数的参数logits为神经网络最后一层的输出,它的大小为[batch_size, num_classes],参数labels表示实际标签值,大小为[batch_size,num_classes]。第一步是先对网络最后一层的输出做一个softmax,输出为属于某一属性的概率向量;再将概率向量与实际标签向量做交叉熵,返回向量。
tf.nn.sparse_softmax_cross_entropy_with_logits()首先来说,这个函数的具体实现分为了两个步骤,我们一步一步依次来看。
第一步:Softmax
不管是在进行文本分类还是图像识别等任务时,神经网络的输出层个神经元个数通常都是我们要分类的类别数量,也可以说,神经网络output vector的dimension通常为类别数量,而我们的Softmax函数的作用就是将每个类别所对应的输出分量归一化,使各个分量的和为1,这样可以理解为将output vector的输出分量值,转化为了将input data分类为每个类别的概率。举一个例子来说:

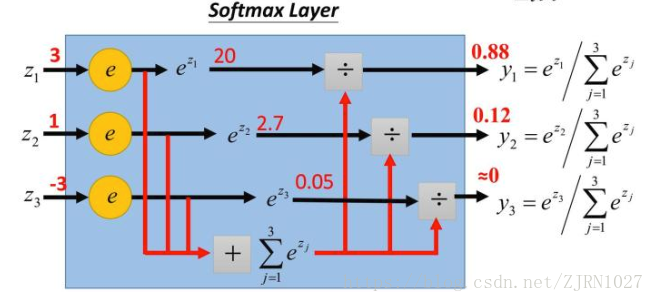
假设上面这个图中的Z1,Z2,Z3为一个三分类模型的output vector,为[3,1,-3],3代表类别1所对应的分量,1为类别2对应的分量,-3为类别3对应的分量。经过Softmax函数作用后,将其转化为了[0.88,0.12,0],这就代表了输入的这个样本被分到类别1的概率为0.88,分到类别2的概率为0.12,分到类别3的概率几乎为0。这就是Softmax函数的作用,Softmax函数的公式如下所示,我们就不做详细讲解了。
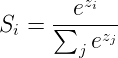
第二步:计算Cross-Entropy
神经网络的输出层经过Softmax函数作用后,接下来就要计算我们的loss了,这个这里是使用了Cross-Entropy作为了loss function。由于tf.nn.sparse_softmax_cross_entropy_with_logits()输入的label格式为一维的向量,所以首先需要将其转化为one-hot格式的编码,例如如果分量为3,代表该样本属于第三类,其对应的one-hot格式label为[0,0,0,1,.......0],而如果你的label已经是one-hot格式,则可以使用tf.nn.softmax_cross_entropy_with_logits()函数来进行softmax和loss的计算。
转为one-hot格式之后就该计算我们的cross-entropy了,公式如下:
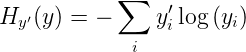
其中为label中的第i个值,
为经softmax归一化输出的vector中的对应分量,由此可以看出,当分类越准确时,
所对应的分量就会越接近于1,从而
的值也就会越小。(注意:交叉熵cross-entropy表示2个概率分布之间的距离,交叉熵越大,两个概率分布距离越远,两个概率分布越相异;交叉熵越小,两个概率分布越接近,两个概率分布越相似。)
第三:代码
讲了这么多,我们来看看项目中是怎样运用这个函数的,直接上代码。
这是之前做实验时写的文本分类的一个程序,其中就用到tf.nn.sparse_softmax_cross_entropy_with_logits()来计算loss。
self.logits = tf.matmul(out_put,output_w)+output_b
self.softmax = tf.nn.softmax(self.logits)
with tf.name_scope("loss"):
self.loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.logits+1e-10,labels=self.target)
self.cost = tf.reduce_mean(self.loss)这里是LSTM_Model程序里面的部分截取,其中self.logits为神经网络输出层的输出,下一行,这里我们使用tf.nn.softmax()计算一下softmax函数的输出结果,是为了打印出来给大家看一下数据,但是在项目中这一行其实是多余的~
下面我们使用tf.nn.sparse_softmax_cross_entropy_with_logits()函数,最后tf.reduce_mean()对batch_size里每个样本的loss求平均,计算最后的cost值。
我们来看一下结果,我的batch_size为64,数据太多我只截取了前五组数据:
首先是self.logits,这是神经网络输出层输出的vector,由于我做的是二分类任务,所以shape=[64,2]
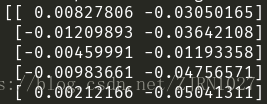
下面是softmax函数作用后的输出结果,我们可以看出来shape依旧是[64,2],但是数据已经被归一化了。
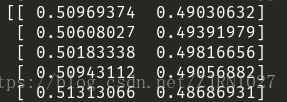
下面是输入的label

接下来是64个样本的loss的值
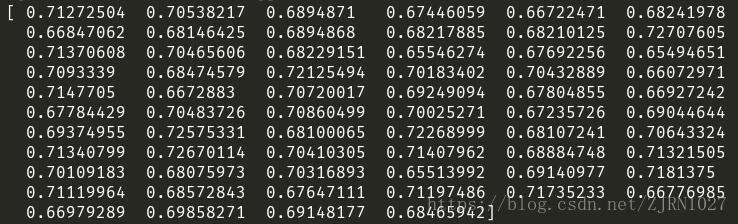
最后是cost的值