dense :全连接层 相当于添加一个层
函数如下:
tf.layers.dense(
inputs,
units,
activation=None,
use_bias=True,
kernel_initializer=None, ##卷积核的初始化器
bias_initializer=tf.zeros_initializer(), ##偏置项的初始化器,默认初始化为0
kernel_regularizer=None, ##卷积核的正则化,可选
bias_regularizer=None, ##偏置项的正则化,可选
activity_regularizer=None, ##输出的正则化函数
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None, ##层的名字
reuse=None ##是否重复使用参数
)部分参数解释:
inputs:输入该网络层的数据
units:输出的维度大小,改变inputs的最后一维
activation:激活函数,即神经网络的非线性变化
use_bias:使用bias为True(默认使用),不用bias改成False即可,是否使用偏置项
trainable=True:表明该层的参数是否参与训练。如果为真则变量加入到图集合中
GraphKeys.TRAINABLE_VARIABLES (see tf.Variable)

tf.nn.softmax_cross_entropy_with_logits
【TensorFlow】tf.nn.softmax_cross_entropy_with_logits的用法
from:https://blog.csdn.net/mao_xiao_feng/article/details/53382790
在计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_entropy_with_logits,那么它到底是怎么做的呢?
首先明确一点,loss是代价值,也就是我们要最小化的值
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
除去name参数用以指定该操作的name,与方法有关的一共两个参数:
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes
softmax的公式是:
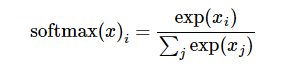
至于为什么是用的这个公式?这里不介绍了,涉及到比较多的理论证明
第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵,公式如下:
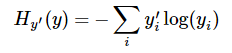
其中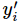
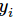
softmax的输出向量[Y1,Y2,Y3...]
显而易见,预测
注意!!!这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到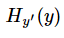
tf.reduce_mean操作,对向量求均值!