简介
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle可以在http://kettle.pentaho.org/网站下载到。
术语
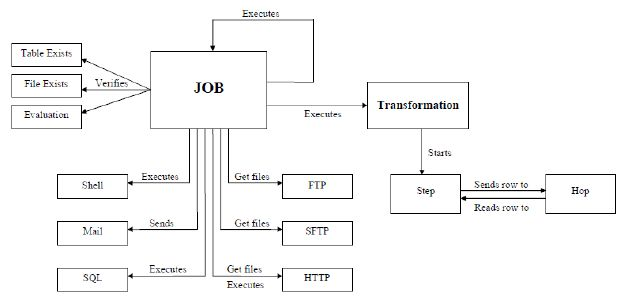
1. Transformation 转换步骤,可以理解为将一个或者多个不同的数据源组装成一条数据流水线。然后最终输出到某一个地方,文件或者数据库等。
2. Job 作业,可以调度设计好的转换,也可以执行一些文件处理(比较,删除等),还可以 ftp 上 传,下载文件,发送邮件,执行 shell 命令等
3. Hop 连接转换步骤或者连接 Job(实际上就是执行顺序) 的连线 Transformation hop:主要表示数据的流向。从输入,过滤等转换操作,到输出。
Job hop:可设置执行条件: 1, 无条件执行 2, 当上一个 Job 执行结果为 true 时执行 3, 当上一个 Job 执行结果为 false 时执行
应用场景
-
表视图模式:这种情况我们经常遇到,就是在同一网络环境下,我们对各种数据源的表数据进行抽取、过滤、清洗等,例如历史数据同步、异构系统数据交互、数据对称发布或备份等都归属于这个模式;传统的实现方式一般都要进行研发(一小部分例如两个相同表结构的表之间的数据同步,如果sqlserver数据库可以通过发布/订阅实现),涉及到一些复杂的一些业务逻辑如果我们研发出来还容易出各种bug;
-
前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;
-
文件模式: 数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B上在按照标准接口解析相应的文件把数据接收过来;
kettle的组成
tips:linux上执行job kitchen.sh -file=/PRD/updateWarehouse.kjb -level=Minimal
执行转换 pan.sh -file=/PRD/updateWarehouse.kjb -level=Minimal
Transformation组件树介绍
Transformation中的节点介绍如下:
- Main Tree:菜单列出的是一个transformation中基本的属性,可以通过各个节点来查看。
- DB连接:显示当前transformation中的数据库连接,每一个transformation的数据库连接都需要单独配置。
- Steps:一个transformation中应用到的环节列表
- Hops:一个transformation中应用到的节点连接列表
核心对象菜单列出的是transformation中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加。 - Input:输入环节
- Output:输出环节
- Lookup:查询环节
- Transform:转化环节
- Joins:连接环节
- Scripting:脚本环节
Job组件树介绍
Job中的节点介绍如下:
- Main Tree:列出的是一个Job中基本的属性,可以通过各个节点来查看。
DB连接:显示当前Job中的数据库连接,每一个Job的数据库连接都需要单独配置。 - Job entries/作业项目:一个Job中引用的环节列表
核心对象菜单列出的是Job中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加。
每一个环节可以通过鼠标拖动来将环节添加到主窗口中。
并可通过shift+鼠标拖动,实现环节之间的连接。
经常遇到问题:
1. 如何连接资源库?
如果没有则创建资源库

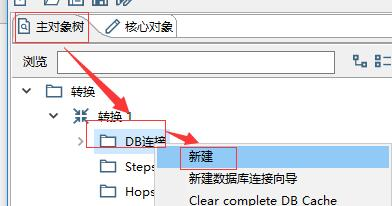
2. 如何连接数据库?
在连接数据库之前,首先需要保证当前在一个transform(转换)页面,然后点击左侧选项栏中的“主对象树”,然后右键点击“DB连接”,选择“新建”。
当然也可以设置一些其他的连接属性,如zeroDateTimeBehavior=round&characterEncoding=utf8。
3. 如何解决数据库连接更新不及时问题?
有时候我们数据库中的表的字段进行了更新(增加或删除字段),但是在使用“表输入”控件的“获取SQL语句”功能是会发现的到的字段还是原来的字段,这是由于缓存造成的,需要进行缓存清理。

4. 如何解决Unable to read file错误?
有时候我们在文件夹中将Job或Transform移动到其他目录之后,执行时会出现Unable to read file错误。然后就进入到了当前Transform的配置页面。修改配置中的目录即可。
5. 如何解决tinyint类型数据丢失问题?
在Kettle使用JDBC连接MySQL时,对于表中数据类型为tinyint的字段,读取时有可能会将其转为bool类型,这有可能造成数据丢失。例如,有一个叫status名字的tinyint类型字段,取值有三种:0、1、2。kettle读取之后很可能将0转为false,1、2都转为true。输出时,将false转为0,true转为1,这样就会造成元数据中status为2的数据被错误的赋值为1。
解决这个问题时,可以在读取元数据时将status转为int或char。比如SELECT CAST(status as signed) as status FROM <table_name>或SELECT CAST(status as char) as status FROM <table_name>