转载自:
http://lastorder.me/tag/parquet.html
https://blog.csdn.net/yu616568/article/details/51868447
Parquet是Hadoop上的一种支持列式存储文件格式。Parquet用Dremel论文(Dremel: Interactive Analysis of Web-Scale Datasets)中描述的方式,把嵌套结构存储成扁平格式。
对于优化『关系型数据库上的分析任务』,列式存储(Columnar Storage)是个比较流行的技术。列式存储,可以对于一个查询,尽量只读取对这个查询有用的数据,以此来让磁盘 IO 最小。采用Parquet,Twitter 把大数据集上的IO缩减到原来的1/3。也做到了『指哪打哪』,也就是遍历(scan)一个数据集的时候,如果只读取部分列,那么读取时间也相应会缩短,时间缩短的比例就是那几列的数据量占全部列数据量的比例。原理很简单,就是不采用传统的按行存储,而是连续存储一列的数据。如果数据是扁平的(比如二维表形式),那列改成按列存储毫无难度,处理嵌套的数据结构才是真正的挑战。
列式存储
何谓列式存储?看下面的例子,这就是三个列 A B C: 
如果把它换成行式存储的,那么数据就是一行挨着一行存储的: 
嵌套数据模型
Parquet支持嵌套的数据模型,类似于Protocol Buffers,每一个数据模型的schema包含多个字段,每一个字段有三个属性:重复次数、数据类型和字段名。重复次数可以是以下三种:required(有且仅只出现1次),repeated(出现0次或多次),optional(出现0次或1次)。每一个字段的数据类型可以分成两种:group(复杂类型)和primitive(基本类型)。例如Dremel中提供的Document的schema示例,它的定义如下:
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated group Language {
required string Code;
optional string Country;
}
optional string Url;
}
} 可以把这个Schema转换成树状结构,根节点可以理解为repeated类型,如下图: 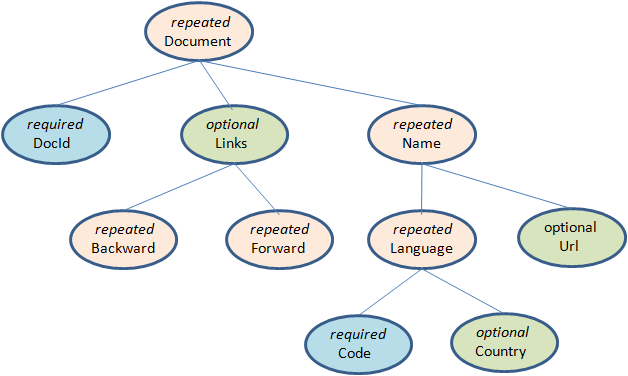
可以看出在Schema中所有的基本类型字段都是叶子节点,在这个Schema中一共存在6个叶子节点,如果把这样的Schema转换成扁平式的关系模型,就可以理解为该表包含六个列。Parquet中没有Map、Array这样的复杂数据结构,但是可以通过repeated和group组合来实现这样的需求。
由于一条记录中某一列可能出现零次或者多次,需要标示出哪些列的值构成一条完整的记录,这是由Striping/Assembly算法实现的。它的原理是每一个记录中的每一个成员值有三部分组成:Value、Repetition level和Definition level。value记录了该成员的原始值,可以根据特定类型的压缩算法进行压缩,两个level值用于记录该值在整个记录中的位置。
Repetition level
为了支持repeated类型的节点,在写入的时候该值它和前面的值在哪一层节点是不共享的。在读取的时候根据该值可以推导出哪一层上需要创建一个新的节点,例如对于这样的一个schema和两条记录: 
列式存储时,这里列我们会存储a、b、c、d、e、f、g、h、i、j,但是某一数据与前面的一个数据的层次关系是不知道的,例如不知道b与a、d与c、h与g是同一层还是不同层等等。
为了表述方便,称在一个嵌套结构里,一个repeated field连续出现的一组值为一个List(只是为了描述方便),比如 a,b,c 是一个level2 List,d,e,f,g是一个level2 List,a,b,c,d,e,f,g所在的两个level2 List是同一个level1 List里的。
那么:repetition level 标示着新 List 出现的层级:
• 0 表示整条记录的开始,此时应该创建新的 level1 List 和 level2 List,比如a或h是一条记录的开始,所以repeated level=0。
• 1 表示level1 List 的开始,此时应该创建一个新的level2 List,比如d和前面的值c共享了根节点(属于相同记录),但是在level1这个节点上是不共享的,所以repeated level=1。
• 2 表示level2 List中新的值产生,此时不新建 List,只在 List 里插入新值,比如b和前面的值共享了level1这个节点,只需要插入新值,所以repeated level=2。
根据以上的分析每一个value需要记录的repeated level值如下: 
在读取的时候,顺序的读取每一个值,然后根据它的repeated level创建对象,当读取value=a时repeated level=0,表示需要创建一个新的根节点(新记录),value=b时repeated level=2,表示需要创建一个新的level2节点,value=d时repeated level=1,表示需要创建一个新的level1节点,当所有列读取完成之后可以创建一条新的记录。本例中当读取文件构建每条记录的结果如下: 
Definition Levels
有了repeated level我们就可以构造出一个记录了,为什么还需要definition levels呢?由于repeated和optional类型的存在,可能一条记录中某一列是没有值的,假设我们不记录这样的值就会导致本该属于下一条记录的值被当做当前记录的一部分,从而造成数据的错误,因此对于这种情况需要一个占位符标示这种情况。
definition level的值仅仅对于空值是有效的,表示在该值的路径上第几层开始是未定义的,对于非空的值它是没有意义的,因为非空值在叶子节点是定义的,所有的父节点也肯定是定义的,因此它总是等于该列最大的definition levels。例如下面的schema。
message ExampleDefinitionLevel {
optional group a {
optional group b {
optional string c;
}
}
} 它包含一个列a.b.c,这个列的的每一个节点都是optional类型的,都可能是null。当c被定义时a和b肯定都是已定义的,当c未定义时我们就需要标示出在从哪一层开始时未定义的,为了记录嵌套结构的状况,我们就需要保存最先出现 null 的那一层的深度了。一共三个嵌套的 optional field,所以最大 definition level 是 3。
以下是各种情形下,a.b.c 的 definiton level: 

这里definition level不会大于3,等于3的时候,表示c有定义;等于0,1,2的时候,指明了null出现的层级。required总是有定义的,所以不需要 definition level。