文章目录
tensorflow层次结构
构成基本部件就是layer,一个layer除了包含其shape,还有其weights,shape和weights构成了layer的基础。
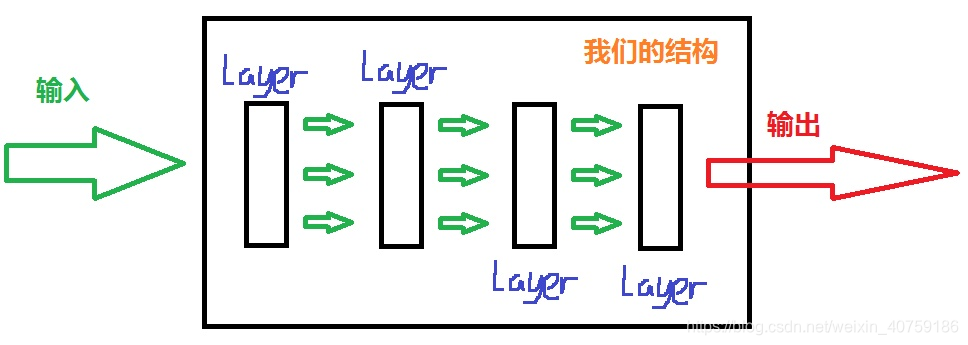 通常我们构建网络代码如下:
通常我们构建网络代码如下:
这个就是一个最简单的三层网络:输入层,隐藏层,输出层
相信大家也了解到了shape和weights是配套的,虽然我们画图是三层,在tensorflow里对应的是2层。
输出层和损失计算是在同一层,一般把最后一层叫做costlayer,正因为如此,我们预测时只用输出层
的weights,不需要使用输出层计算损失的过程。
nn = NNDist()
nn.add(ReLU((x.shape[1], 24)))
nn.add(CrossEntropy((y.shape[1],)))
在这里不要纠结使用tensorflow的方法来实现tensorflow,我们只是了解tensorflow的代码结构,实际都可以自己写。
layer的实现:
layer有一个变量和一个方法:shape和activate
from abc import ABCMeta, abstractmethod
class Layer():
__metaclass__ = ABCMeta
def __init__(self, shape):
self.shape = shape
def activate(self, x, w, bias=None, predict=False):
if bias is None:
return self._activate(tf.matmul(x, w), predict)
return self._activate(tf.matmul(x, w) + bias, predict)
@abstractmethod
def _activate(self, x, predict):
pass
# Activation Layers
class Tanh(Layer):
def _activate(self, x, predict):
return tf.tanh(x)
class Sigmoid(Layer):
def _activate(self, x, predict):
return tf.nn.sigmoid(x)
值得提出的是,输出层,也就是costlayer的处理,把损失计算看成最后一层的激活方法,这个由于tensorflow的内置梯度计算,现在相当于forward pass增加了一步:
# Cost Layers
class CostLayer(Layer):
def _activate(self, x, y):
pass
def calculate(self, y, y_pred):
return self._activate(y.astype(np.float32), y_pred)
class CrossEntropy(CostLayer):
def _activate(self, x, y):
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=x, labels=y))
利用layer构建网络:
构建网络需要的变量:
一个网络我们需要什么,至少需要2个变量,一是存放所有layers,而是存放所有的weights。
class NNBase:
def __init__(self):
# 一个NN是由各个layers构成,这里存放所有layers的信息,
# 每个layers包含shape和weights
self._layers = []
# 优化器是什么
self._optimizer = None
# 当前layer神经元的个数
self._current_dimension = 0
# data sets
self._tfx = self._tfy = None
# 把每一层的权重信息更新到总的列表
self._tf_weights, self._tf_bias = [], []
self._cost = self._y_pred = None
self._train_step = None
添加layers:
首先添加layer的过程是在干什么,没有想象的复杂:他基本干两件事,更新self._layers和self._tf_weights。
注意的structure都只是shape而已。
# 创建网络时使用,
# 创建网络的过程实际上是维护self._layers,self._tf_weights这两个表
# 这两个表代表了整个网络,所以第一次先创建这两个表
# 输入层的shape有连个维度:feature_dim,隐藏层神经元个数,
# 其他层shape只有一个维度:隐藏层神经元个数
# 所以需要有一个空中变量始终代表当前层的维度,也就是
# 加入层的前一层的维度
def add(self, layer):
# 第一层需要单独处理
if not self._layers:
self._layers, self._current_dimension = [layer], layer.shape[1]
self._add_weight(layer.shape)
else:
_next = layer.shape[0]
self._layers.append(layer)
self._add_weight((self._current_dimension, _next))
self._current_dimension = _next
# 定义变量w和b
@staticmethod
def _get_w(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name="w")
@staticmethod
def _get_b(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name="b")
# 根据当前层的shape把每一层的权重信息更新到总的列表
def _add_weight(self, shape):
w_shape = shape
b_shape = shape[1],
self._tf_weights.append(self._get_w(w_shape))
self._tf_bias.append(self._get_b(b_shape))
前向传播处理(损失处理在最后一层):
# forward pass
def _get_rs(self, x, y=None):
# get the value of first layer
# 获取第一层的输出,调用self.activate时会直接调用存入self._layers
# 里对应的激活函数的self._activate
_cache = self._layers[0].activate(x, self._tf_weights[0], self._tf_bias[0])
for i, layer in enumerate(self._layers[1:]):
# in last layer
if i == len(self._layers) -2:
# 假如是预测的话,就不需要costlayer计算损失,直接利用最后的权重更新结果
if y is None:
#首先costlayer应该不参与预测的,costlayer也不能称之为层,
# 因为tensorflow的梯度计算内置了,从堆积木角度看
# 把backword pass可以看成层,不参与预测为什么还需要矩阵计算
# tf.matmul(_cache, self._tf_weights[-1] + self._tf_bias[-1])?
# 这是因为输出层和costlayer往往是一起的,
# costlayer里面装的weights实际上是输出层的weights
return tf.matmul(_cache, self._tf_weights[-1] + self._tf_bias[-1])
# 否则就是训练过程,需要传入y_true,计算损失
return layer.activate(_cache, self._tf_weights[i+1], self._tf_bias[i+1], y)
# 不是最后一层,就按照第一层的处理
_cache = layer.activate(_cache, self._tf_weights[i+1], self._tf_bias[i+1])
return _cache
完整构建网络,训练fit():
首先上述只是NN的一个基类,还有一些精心设计的网络模块化了,完整版的神经网络就叫做 NNDist,是在基类基础上完成的,其次训练是在会话里进行的。
class NNDist(NNBase):
def __init__(self):
NNBase.__init__(self)
self._sess = tf.Session()
def _get_prediction(self,x):
with self._sess.as_default():
# 将字符串str当成有效的表达式来求值并返回计算结果
return self._get_rs(x).eval(feed_dict={self._tfx:x})
def predict_classes(self, x):
x = np.array(x)
return np.argmax(self._get_prediction(x), axis=1)
def fit(self, x=None, y=None, lr=0.001, epoch=10):
# 记录的是结构用的 Optimizer
self._optimizer = Adam(lr)
# build graph
self._tfx = tf.placeholder(tf.float32, shape=[None, x.shape[1]])
self._tfy = tf.placeholder(tf.float32, shape=[None, y.shape[1]])
with self._sess.as_default() as sess:
self._cost = self._get_rs(self._tfx, self._tfy)
self._y_pred = self._get_rs(self._tfx)
self._train_step = self._optimizer.minimize(self._cost)
sess.run(tf.global_variables_initializer())
# train
for counter in range(epoch):
# 这种用法有点奇怪啊
self._train_step.run(feed_dict={self._tfx: x, self._tfy: y})
def evaluate(self, x, y):
y_pred = self.predict_classes(x)
y_arg = np.argmax(y, axis=1)
print("Acc: {:8.6}".format(np.sum(y_arg == y_pred) / float(len(y_arg))))
测试代码:
import sys
'''python import模块时, 是在sys.path里按顺序查找的。
sys.path是一个列表,里面以字符串的形式存储了许多路径。
使用A.py文件中的函数需要先将他的文件路径放到sys.path中'''
root_path = sys.path.append(r"/root/2half/Util")
import Util
def main():
nn = NNDist()
epoch = 1000
x, y = Util.DataUtil.gen_spiral(120, 7, 7, 4)
nn = NNDist()
nn.add(ReLU((x.shape[1], 24)))
nn.add(CrossEntropy((y.shape[1],)))
nn.fit(x, y, epoch=epoch)
nn.evaluate(x, y)
if __name__ == '__main__':
main()