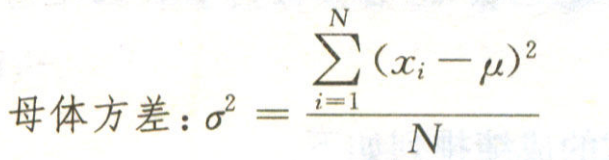预测一个网站上有多少用户愿意为了某些高级功能支付费用
数据python:
my_data=[[‘slashdot’,‘USA’,‘yes’,18,‘None’],
[‘google’,‘France’,‘yes’,23,‘Premium’],
[‘digg’,‘USA’,‘yes’,24,‘Basic’],
[‘kiwitobes’,‘France’,‘yes’,23,‘Basic’],
[‘google’,‘UK’,‘no’,21,‘Premium’],
[’(direct)’,‘New Zealand’,‘no’,12,‘None’],
[’(direct)’,‘UK’,‘no’,21,‘Basic’],
[‘google’,‘USA’,‘no’,24,‘Premium’],
[‘slashdot’,‘France’,‘yes’,19,‘None’],
[‘digg’,‘USA’,‘no’,18,‘None’],
[‘google’,‘UK’,‘no’,18,‘None’],
[‘kiwitobes’,‘UK’,‘no’,19,‘None’],
[‘digg’,‘New Zealand’,‘yes’,12,‘Basic’],
[‘slashdot’,‘UK’,‘no’,21,‘None’],
[‘google’,‘UK’,‘yes’,18,‘Basic’],
[‘kiwitobes’,‘France’,‘yes’,19,‘Basic’]]
字段解释:来源网站、位置、是否阅读过FAQ、浏览网页数、选择服务类型。将合理的推测值填入 服务类型 是我们的目标。
1、引入决策树:
class decisionnode:
def init(self,col=-1,value=None,results=None,tb=None,fb=None):
self.col=col
self.value=value
self.results=results
self.tb=tb
self.fb=fb
其中 col是待检验的判断条件
value对应于为了使结果为true,当前列必须匹配的值。
tb和fb也是decisionnode,对应于结果是true和false时,树上相对于当前节点的子树上的节点。
results 保存的是当前分支结果。
2、对树进行训练
创建divideset函数,split_function函数判断指定列中的数值与参考值是否相等,利用该函数将数据拆分成两个集合。
def divideset(rows,column,value):
# 定义一个函数,令其告诉我们数据行属于第一组(返回值为true)还是第二组(返回值为false)
split_function=None
if isinstance(value,int) or isinstance(value,float):
split_function=lambda row:row[column]>=value
else:
split_function=lambda row:row[column]==value
set1=[row for row in rows if split_function(row)] # 将数据集拆分为两个集合,并返回
set2=[row for row in rows if not split_function(row)]
return set1,set2
set1,set2=divideset(my_data,2,‘yes’)
set1,set2=divideset(my_data,3,18)
set1
Out[19]:
[[‘slashdot’, ‘USA’, ‘yes’, 18, ‘None’],
[‘google’, ‘France’, ‘yes’, 23, ‘Premium’],
[‘digg’, ‘USA’, ‘yes’, 24, ‘Basic’],
[‘kiwitobes’, ‘France’, ‘yes’, 23, ‘Basic’],
[‘slashdot’, ‘France’, ‘yes’, 19, ‘None’],
[‘digg’, ‘New Zealand’, ‘yes’, 12, ‘Basic’],
[‘google’, ‘UK’, ‘yes’, 18, ‘Basic’],
[‘kiwitobes’, ‘France’, ‘yes’, 19, ‘Basic’]]
set2
Out[20]:
[[‘google’, ‘UK’, ‘no’, 21, ‘Premium’],
[’(direct)’, ‘New Zealand’, ‘no’, 12, ‘None’],
[’(direct)’, ‘UK’, ‘no’, 21, ‘Basic’],
[‘google’, ‘USA’, ‘no’, 24, ‘Premium’],
[‘digg’, ‘USA’, ‘no’, 18, ‘None’],
[‘google’, ‘UK’, ‘no’, 18, ‘None’],
[‘kiwitobes’, ‘UK’, ‘no’, 19, ‘None’],
[‘slashdot’, ‘UK’, ‘no’, 21, ‘None’]]
如此拆分结果不是很理想,混杂了各种情况
3、选择最合适的拆分对象
uniquecounts函数对数据集中的每一项结果进行计数
def uniquecounts(rows):
results={}
for row in rows:
r=row[len(row)-1]
if r not in results:
results[r]=0
results[r]+=1
return results
基尼不纯度
基尼不纯度:将来自集合中的某种结果随机应用于集合中某一数据项的预期误差率。
python代码:
def giniimpurity(rows):
total=len(rows)
counts=uniquecounts(rows)
imp=0
for k1 in counts:
p1=float(counts[k1])/total
for k2 in counts:
if k1k2:
continue
p2=float(counts[k2])/total
imp+=p1p2
return imp
熵:代表的是集合的无序程度
python代码:
def entropy(rows):
from math import log
log2=lambda x :log(x)/log(2)
results=uniquecounts(rows)
# 此处开始计算熵的值
ent=0.0
for r in results:
p=float(results[r])/len(rows)
ent=ent-plog2§
return ent
uniquecounts(my_data) #{‘Basic’: 6, ‘None’: 7, ‘Premium’: 3}
giniimpurity(my_data) #0.6328
entropy(my_data) #1.505
熵和基尼不纯度都是值越小越好。熵对于混乱集合的判罚往往更重一点,因此对熵的使用更普遍一点。
4、以递归的方式构造树
信息增益:是指当前熵与两个新群组经加权平均后的熵之间的差值。 算法会针对每个属性计算相应的信息增益,从中选出信息增益最大的属性。
信息增益的计算规则:
#构造树
def buildtree(rows,scoref=entropy):
if len(rows)0:
return decisionnode()
current_score=scoref(rows)
# 定义一些变量以记录最佳拆分条件
best_gain=0
best_criteria=None
best_sets=None
column_count=len(rows[0])-1
for col in range(0,column_count):
# 在当前列中生成一个由不同值构成的序列
column_values={}
for row in rows:
column_values[row[col]]=1
# 接下来根据这一列中的每个值,尝试对数据进行拆分
for value in column_values.keys():
(set1,set2)=divideset(rows,col,value)
# 信息增益
p=float(len(set1))/len(rows)
gain=current_score-p*scoref(set1)-(1-p)*scoref(set2)
if gain>best_gain and len(set1)>0 and len(set2)>0:
best_gain=gain
best_criteria=(col,value)
best_sets=(set1,set2)
# 找到最佳分裂属性后,开始创建子分支
if best_gain>0:
trueBranch=buildtree(best_sets[0])
falseBranch=buildtree(best_sets[1])
return decisionnode(col=best_criteria[0],value=best_criteria[1],tb=trueBranch,fb=falseBranch)
else:
return decisionnode(results=uniquecounts(rows))
tree=buildtree(my_data)
5、决策树的显示:
def printtree(tree,indent=’’):
# 这是一个叶子节点吗?
if tree.results!=None:
print(str(tree.results))
else:
# 打印判断条件
print(str(tree.col)+’:’+str(tree.value)+’?’)
# 打印分支
print(indent+‘T->’),
printtree(tree.tb,indent+’ ‘)
print(indent+‘F->’),
printtree(tree.fb,indent+’ ')
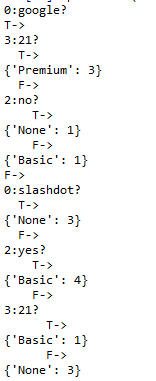
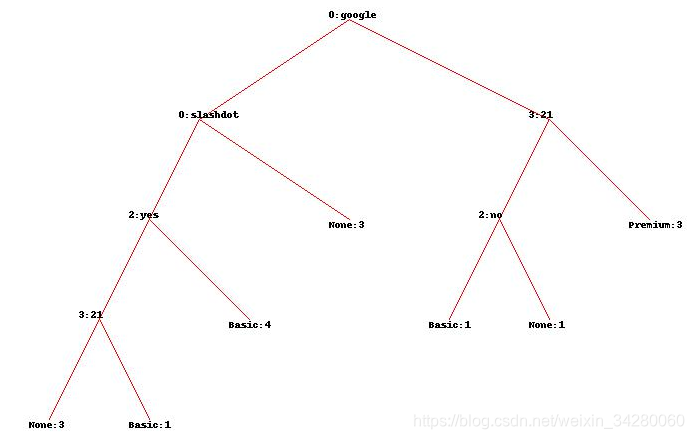
printtree(tree)
“google 在第0列吗?” 满足则T->,若浏览网页个数已经达到或超过21个,则将成为付费用户。若条件不满足,则会跳到F->。并对"slashdot在第0列吗?"进行评估。这一过程一直持续。
6、图形显示方式
def getwidth(tree):
if tree.tbNone and tree.fbNone:
return 1
return getwidth(tree.tb)+getwidth(tree.fb)



def getdepth(tree):
if tree.tbNone and tree.fbNone:
return 0
return max(getdepth(tree.tb),getdepth(tree.fb))+1
‘’’
为了将树真正打印出来,我们还需要安装Python Imaging Library
‘’’
from PIL import Image,ImageDraw
‘’’
drawtree为待绘制的树确定了一个合理的尺寸,并设置好了画布(canvas),然后将画布和根节点传给了drawnode函数
‘’’
def drawtree(tree,jpeg=‘tree.jpg’):
w=getwidth(tree)*100
h=getdepth(tree)*100+120
img=Image.new(‘RGB’,(w,h),(255,255,255))
draw=ImageDraw.Draw(img)
drawnode(draw,tree,w/2,20)
img.save(jpeg,‘JPEG’)
def drawnode(draw,tree,x,y):
if tree.results==None:
# 得到每个分支的宽度
w1=getwidth(tree.fb)*100
w2=getwidth(tree.tb)*100
left=x-(w1+w2)/2 # 确定此节点所需要占据的空间,最左边left,最右边right
right=x+(w1+w2)/2
# 绘制判断条件字符串
draw.text((x-20,y-10),str(tree.col)+’:’+str(tree.value),(0,0,0))
# 绘制到分支的连线,从当前节点画到其左右子节点
draw.line((x,y,left+w1/2,y+100),fill=(255,0,0))
draw.line((x,y,right-w2/2,y+100),fill=(255,0,0))
# 绘制分支的节点
drawnode(draw,tree.fb,left+w1/2,y+100)
drawnode(draw,tree.tb,right-w2/2,y+100)
else:
txt=’\n’.join([’%s:%d’%v for v in tree.results.items()])
draw.text((x-20,y),txt,(0,0,0))
drawtree(tree,jpeg=‘tree.jpg’)
7、对新的观测数据分类
def classify(tree,data):
if tree.results!=None:
return tree.results
else:
branch=None
if isinstance(data[tree.col],int) or isinstance(data[tree.col],float):
if data[tree.col]<tree.value:
branch=tree.fb
else:
branch=tree.tb
else:
if data[tree.col]!=tree.value:
branch=tree.fb
else:
branch=tree.tb
return classify(branch,data)
print(classify(tree,[’(direct)’,‘USA’,‘yes’,5])) #{‘Basic’: 4}
8、决策树剪枝
def prune(tree,mingain):
if tree.fb.resultsNone:
prune(tree.fb,mingain)
if tree.tb.resultsNone:
prune(tree.tb,mingain)
# 如果两个分支都是叶子节点,那么需要判断是否将其与父节点合并
if tree.fb.results!=None and tree.tb.results!=None:
tb,fb=[],[]
for v,c in tree.tb.results.items():
tb+=[[v]]c
for v,c in tree.fb.results.items():
fb+=[[v]]c
# 检查熵的减少情况
#delta=entropy(tb+fb)-(entropy(tb)+entropy(fb)/2) 书上这么写的,我修改如下:
p=float(len(tb))/len(tb+fb)
delta=entropy(tb+fb)-pentropy(tb)-(1-p)entropy(fb)
if delta<mingain:
# 合并分支
tree.tb,tree.fb=None,None
tree.results=uniquecounts(tb+fb)
prune(tree,1.0)
printtree(tree)
9、处理缺失值:若发现有重要数据缺失,则对每个分支对应结果值都会被计算一遍,并且最终的结果值会乘以它们各自权重。
def mdclassify(tree,data):
if tree.results!=None:
return tree.results
else:
if data[tree.col]==None:
tr,fr=mdclassify(tree.tb,data),mdclassify(tree.fb,data)
tcount=sum(tr.values()) # 该分支的样本总数
fcount=sum(fr.values())
tw=float(tcount)/(tcount+fcount) # 流入该分支的样本占父节点样本的比重
fw=float(fcount)/(tcount+fcount)
result={}
for k,v in tr.items():
result[k]=vtw
for k,v in fr.items():
if k not in result:
result[k]=0
result[k]+=vfw
return result
else:
branch=None
if isinstance(data[tree.col],int) or isinstance(data[tree.col],float):
if data[tree.col]<tree.value:
branch=tree.fb
else:
branch=tree.tb
else:
if data[tree.col]!=tree.value:
branch=tree.fb
else:
branch=tree.tb
return mdclassify(branch,data)
print(mdclassify(tree,[‘google’,‘France’,None,None]))
#{‘Premium’: 2.25, ‘None’: 0.125, ‘Basic’: 0.125}
每个概率都会乘以相应的权重值。
10、处理数值型结果:当拥有一颗以数字作为输出结果的决策树时,可以使用方差(variance)作为评价函数来取代熵或者基尼不纯度。
方差公式:
Python代码:
def variance(rows):
if len(rows)==0:
return 0
data=[float(row[len(row)-1]) for row in rows] # 遍历rows的类属性
mean=sum(data)/len(data)
variance=sum([(d-mean)**2 for d in data])/len(data)
return variance