不得不说《Linux内核源代码情景分析》这本书被那么多人当作经典是有原因的,这里只是该书的笔记远不及毛老师描述的清楚。
对第一章做一个总结。这一章主要讲解段式和页式内存管理,当然还有一些其他东西。
- Linux内核版本号的格式:”x.yy.zz“,其中x号的不同表示内核发生了重大改变。 yy号不同一方面表示内核的不同版本,第二方面表示内核是发行版还是开发版,yy为偶数表示发行版,为奇数表示开发版。zz表示同一个版本的内核下进行了细微修改。
- 修改linux的内核必须”开源“,但是在Linux系统下的应用程序就可以有自己的知识产权不必”开源“。
- Linux 2.4.0版本源代码目录组成大致如下(安装的Linux源码在/usr/src/linux):

- 我们所得cpu有多少位是指的cpu的ALU(算术逻辑单位)有多少位。
- 段式管理:
intel在8086 cpu中设置了4个段寄存器:CS(代码段寄存器)、DS(数据段寄存器)、SS(堆栈段寄存器)、ES(附加段寄存器)。这4个段寄存器是16位cpu时就有的段寄存器,那时没有保护模式,也就谈不上内存管理,说白了就不是现在意义上的中央处理器。cpu发展到32位后,因为之前的架构设计不好变动,所以cpu中保留了CS、DS、SS、ES这4个段寄存器,并为减少ES寄存器的负担添加了:FS(通用寄存器)、GS(变址寄存器)两个寄存器。
下面介绍一条访问内存指令发出一内存地址后,cpu是如何得到其放到数据总线的实际地址的:
(1)通过指令性质判断使用哪个段寄存器,例如:转移指令中地址在代码段;取数指令中地址在数据段。
(2)根据段寄存器中的”虚地址“指令作为偏移,在”段描述结构体数组“找到对应的”段描述结构体“。
(3)从结构体中的到基地址。
(4)判断该结构体中基地址加上结构体中的段长后是否越界。
(5)根据指令性质和段描述符中的访问权限判断是否越权。
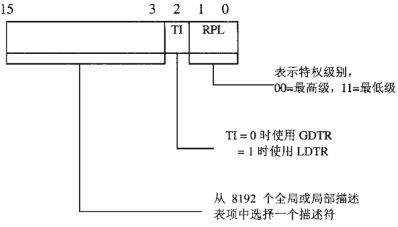
其中第(2)条是否看起来比较懵比,因为还有两个寄存器还没有介绍:GDTR(全局段描述寄存器)、LDTR(局部段描述寄存器),分别指向内存中一个”地址段描述结构体数组“。将寄存器中的前13位作为下标在两个”段描述结构体数组“中找到相应的”段描述结构体“。
寄存器的定义如下图:
这里就有一个疑问了,“段描述结构体”是什么样的形式呢?下面用一段伪代码来说明:
typedef struct
{
unsigned int base24_31:8; /*段的基地址最高8位*/
unsigned int g:1; /* granularity,表段的长度单位,0表示字节,1表示4KB */
unsigned int d_b:1; /* default operation size,存取方式,0=16位,1=32位*/
unsigned int unused:1; /*固定设置为0*/
unsigned int avl:1; /* avalaible,可供系统软件使用*/
unsigned int seg_limit_16_19:4; /*段的长度的最高4位*/
unsigned int p:1; /* segment present,为0表示该段内容不在内存中*/
unsigned int dpl:2; /* Descriptor privilege level,访问本段所需要的权限*/
unsigned int s:1; /*描述项类型,0表示系统,1表示代码或数据*/
unsigned int type:4; /*段的类型与上的S标志位一起使用*/
unsigned int base_0_23:24; /*段的基地址的低24位*/
unsigned int seg_limit_0_15:16; /*段的长度低16位*/
}段描述项;上述伪代码中type的字节定义如下:

很容易看出:当我们把”段描述项结构体“中的基地址设置为0,段的长度设置为最大,就刚好从0覆盖到32位地址空间(4G),这也是Linux页式管理跳过段式管理的方法了。
还有一点补充:我们知道电脑为使内存最大化,将常用数据放在内存中将不常用数据放在磁盘中,所以cpu取数据时将会判断”段描述结构体“中type字段的P值,如果P值为0表示不在内存在磁盘中,此时cpu产生一次异常,由相应的服务程序将磁盘中这一段内容读入内存某地方,并依据放入内存的地方设置”段描述项结构体“基地址,并将P值置为1。
还有一点补充:虽然80386cpu将 rpl(权限)划分为了0、1、2、3,这4个等级,但是Linux、unix等操作系统并未按照intel想的那么来,而是指采用了0、3两个等级,分别是:系统状态、用户状态。
- 页式管理
页式内存管理较之段式内存管理来说,页式内存管理有更好的灵活性和效率性。所谓灵活性是指能操作尽量小的内存空间表示灵活性越高,效率当然是指cpu完成相同功能时间越短则效率越高。如果想增加段式内存管理的灵活性的话就需要频繁的更改寄存器的值,使得效率性降低。所以综上所述选择页式管理更为合理。
那我们干嘛要介绍段式管理呢?因为早期cpu一直使用段式管理的方式,后来新改进的cpu也是决定利用之前的资源,所以也就必须先经过段式内存管理再进行页式内存管理,但我们得知道在Linux中段式管理其实是没什么作用的,所以其采用一种巧妙的方式跳过了段式管理(第二章再讲)。
可以从下图中了解到页式管理的基本逻辑:

CR3是新添加的一个寄存器,作为指向页面目录的一个指针。一个符合指令性质的32位的段寄存器中的虚地址被分为:目录、页表、偏移量,3段。在寄存器中的占位:偏移量 0-11,页表 12-21,目录 23-31。其中每个目录和页表成员都占用4字节。
到这里可能有些人要问了:为什么页式管理要有那么多次的映射过程,”一步到位“不就好了吗?其实这样自然有好处的:
第一:这样做可以节约内存,想一下,一个进程几乎不可能用到全部的内存,这么说的话,很多页面指向的物理空间进程是没有去访问的,那么对应有很多页表和目录进程也没有去访问,如果采用只经过一次映射的方式,比如只经过”目录“映射的方式,那么cpu肯定会为整个”目录“分配好内存,就会占用很多空间。但是若采用多次映射的方式,只要有进程没有访问到的目录,那么该目录其所指向的页表数组就不会被分配空间,从而达到节约内存的效果。
第二:每个目录数组和页表数组中都有1024个成员,每个成员占4字节,所以每个目录数组和页表数组都占4k字节,就刚好一个页面的大小,就无须跨页面存放。
目录结构体伪代码如下:
typedef struct
{
unsigned int ptba:20; /* 页表基地址高20位*/
unsigned int avail:3; /* 通系统程序员使用 */
unsigned int g:1; /* global,全局性页面 */
unsigned int ps:1; /* 页面大小,0表示4k */
unsigned int reserved:1; /* 保留,永远是0 */
unsigned int a:1; /* accessed,已被访问过 */
unsigned int pcd:1; /* 关闭缓冲存储器 */
unsigned int pwt:1; /* Write Through,用于缓冲存储器*/
unsigned int u_s:1; /* 为0表示系统权限,为1表示要用户权限 */
unsigned int r_w:1; /* 只读或可写 */
unsigned int p:1; /* 为0表示页面未在内存中 */
}目录项;在页表结构体中,与之目录结构体几乎一样,只是reserved位表示Dirty,表示该页面已经被写过。ps为变为保留位reserved。
- Linux的内核C代码
1.内核中有大量的内联函数inline。
2.定义一个宏实现简单的功能最好使用的方式:#define xxx do{ }while(0) 的方式。
3.下面主要讲一下Linux的链表,它是比较巧妙也很常用链表使用方式:
在学习输入子系统时就有体会但是没有深入学习,导致后来面试的时候被问道Linux的链表有什么巧妙之处时一脸懵逼...。现在学习到了,Linux链表一般如下构成:
struct list_head //称为寄宿者
{
struct list_head *next, *prev;
};
------------------我是分割线------------------
typedef struct page //称为宿主
{
struct list_head list;
......
struct page *next_hash;
......
struct list_head lru;
......
} mem_map_t;通过阅读Linux源码我们可以发现:将宿主这连接到链表中的函数list_add( ),实际上是将寄宿者list_head添入链表中去,那么有人就要问了:这样添进去有什么用吗?我们怎么通过list_head链表找到要使用的宿主节点呢?Linux是这样巧妙实现的,看下面4行代码:
#define memlist_entry list_entry
#define list_entry(ptr, type, member) ( (type *)( (char *)(ptr) - (unsigned long )(& ((type *)0) ->member) ) )
page = memlist_entry(curr, struct page, list);
//这里的curr是指某page节点内部成员list的地址,&((struct page*)0) ->list)是指page在0地址时list的地址。
page = ( (struct page *)((char *)curr - (unsignes long)(&((struct page *)0) ->list) ) );