Linux内核源代码情景分析笔记
好吧,首先我承认我要是读者的话,这篇文章我看着也头疼,因为写的太长太泛(其主要部分集中在内存管理,进程管理,文件系统)!原本是想按自己理解的精简精简的,按照操作系统中两个核心的抽象概念“进程”和“文件”开始介绍的,可以说操作系统引入这两个概念是系统的核心,其中进程的管理可以说是对内存和cpu的抽象管理,当然基础内存管理是必须的。而文件可以说是对设备的一层抽象(不仅仅是存储文件的设备),而底层的实现则需要设备驱动程序。而且进程与文件之间可以说是一个相辅相成的作用,从进程控制块就能看出,所以没办法分开来介绍那个。所以这篇文章还是按照学习的过程一点一点来总结介绍的。再者,其原因之一是linux系统实在庞大,之二是我写不出很高度概括性的东西,而且很多地方我怕以后有误解,所以写的很严谨,不敢说太多的大话迷惑大家,迷惑自己。
最后希望咱们学计算机的都能做个程序员,工程师之类的,而不是码农!好了,下面就进入主题-Linux内核源代码情景分析。
1预备知识
1.1linux内核简介
linux发展史
linux源代码组成
linux内核版和发行版的命名方式
1.2 Intelx86的寻址方式
早期8086和8088处理器是16位,寻址方式为实模式,后来随着技术的发展,人们意识到实模式的不足(完全把计算机暴露在用户的眼皮下),就产生了保护模式,关于这两点的区别,主要在于对内存的访问是否有进行保护,主要是越界和越权。越界就是用户不能访问的地址范围不允许访问,用户没有权限的地址范围不能访问。所以早期计算机工作者们就在建立了段式内存管理,把内存地址进行分段(比如,16段,每段大小64k,刚好1M)然后cpu中设置了四个段寄存器:CS,DS,SS,ES,分别用于可执行代码的指令,数据,堆栈,其他。由于早期intel内存大小采用1M,而cpu确实16位,如果不做一定额处理,16位总线是不能访问超过64k的范围,所以每个段寄存器的内容作为内存地址的高16位,同时与段内偏移地址作为低16进行相加(重叠12位),这样就刚好形成了20位的内存地址,即1M。
由于这种管理机制无法提供对内存的保护,所以基于段式内存管理机制,到后来的386以后,人们采用保护模式,并且数据总线为32位了,人们在原来的四个段寄存器的基础上加上两个段寄存器FS,GS,为了实现保护模式的作用。所以数据总线的地址内容应该有如下设计思想
1根据指令的性质来确定应该使用哪个段寄存器
2根据段寄存器的内容,找到相应的地址段描述结构
3根据地址段描述结构得到基地址
4将指令发出的地址作为位移,与段描述结构中规定的段长度比较,是否越界
5根据地址段描述结构符中的访问权限来确定是否越权
6将指令发出的地址作为位移,与基地址相加得出实际的物理地址。
上面就是保护模式下段式内存管理的设计思想,下面就是实现过程。
1段寄存器,由于段地址描述结构栈8个字节,故地址为8的整数倍,所以段寄存器低三位可以用于其他作用。
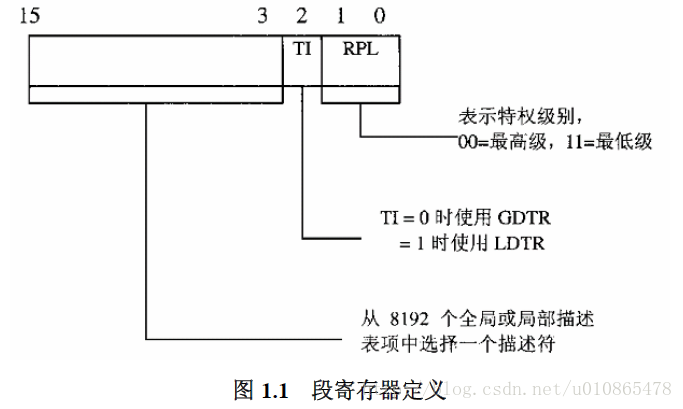
2段地址描述结构(GDTR,LDTR),其数据的主要作用在于描述基地址,权限,范围。

通过上面的段寄存器映射到过渡的段地址描述结构,最后就是指令发出的地址与段地址描述结构提供的基地址来映射到最后的物理地址了(前提是没有采用分页内存管理)。
实模式与保护模式介绍的相关资料
http://wenku.baidu.com/link?url=hbpDCdrBxA_agf7u9pLZCdXIXvXwPXMvIbKsSgRZiPp9F8jcD6mRqsgDI9-dB9_8cuQS8Bz_IMxg85ZjytPOxiU_OBlk4_Gg7Nlo3mY8tg_
1.3 i386页式管理机制
由于段式管理机制是实实在在的,没有抽象出来,不方便内存管理,人们就又在段式管理的基础上增加了分页式管理,从而由虚拟地址经过段式管理映射得到的地址不再是物理地址了,人们称为线性地址,在线性地址的基础上经过页面映射后得到的才是真正的物理地址。
在分页机制中,线性地址的结构被人为的划分为

而整个页面映射的过程为
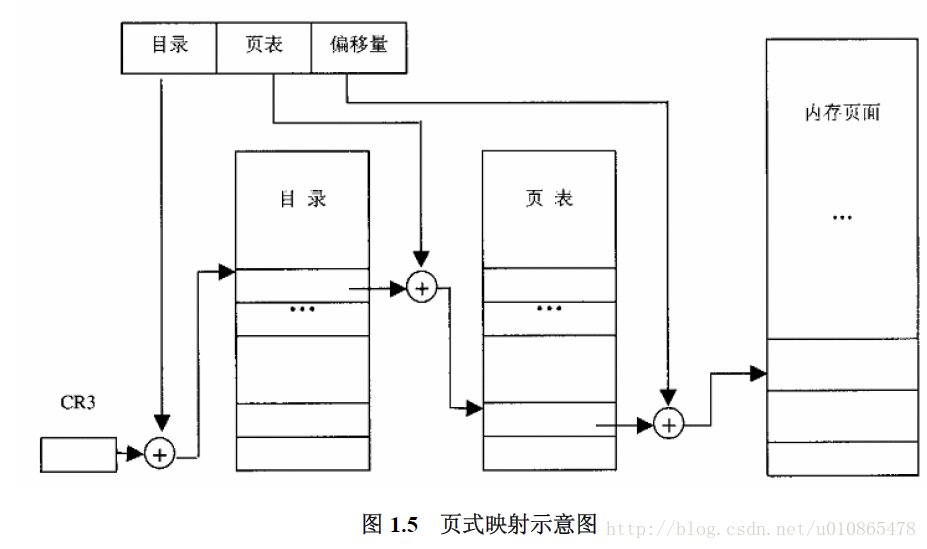
这里解释两点
1 记得前面我的每个段地址描述结构都占8个字节,所以地址一定按8的整数倍对其,这里我们的页面大小人为的划分为4k,即按4k对其,所以我们的目录项和页表同样可以拿出低12位用作他用。至于怎样实现,那是硬件上的问题。
2 为什么采用多级分页机制,而不简单直接的使用页表和页内偏移地址来进行分页,目的是在于节省内存,至于是怎么节省的,我当初上操作系统课程始终不明白,现在搞明白了。因为操作系统在创建进程时会为进程分配一个进程控制块,里面其中有一部分就是对虚存管理的页面数据结构,如果不采用多级分页机制的话,那么每个进程关页面表就占 个字节,即1M,即是进程用不着那么页表项(因为32位地址默认个用户的虚存空间是4G,但一个进程很难想象会用完这4G),但还是会占内存,但是采用多级分页的话,那么不需要的页表项就不进行分配,从而也就节省了内存,但是相反一个进程真的用完了4G的虚存,那么他需要的目录项和页表项占的内存就多了目录项这一部分了。
1.4linux内核源代码中C语言代码
Linux内核的主体是由GNU的C语言编写,CNU为此提供了编译器gcc,而gcc从C++语言中吸收了inline和const,其实GNU的C和C++是合为一体的,gcc既是C的编译器也是C++的编译器,所以linux中很多C语言代码自然就有C++风格在里面,所以需要一点C++基础。但这不是问题关键,关键在学习linux中C语言设计思想。
1常见的宏定义对简单函数的实现
#define DUMP_WRITE(addr,nr) \ do{ memcpy(bufp,addr,nr);bufp+=nr} while(0)2使用结构体封装多个队列
Typedef struct page{
Struct list_head list;
Struct page *next_hash;
…………………
}mem_map_t;3使用宏定义与函数实现简单初始化
#define IRQ(x,y) \
IRQ##x##y##_interrupt
#define IRQLIST_16(x) \
IRQ(x,0), IRQ(x,1), IRQ(x,2), IRQ(x,3), \
IRQ(x,4), IRQ(x,5), IRQ(x,6), IRQ(x,7), \
IRQ(x,8), IRQ(x,9), IRQ(x,a), IRQ(x,b), \
IRQ(x,c), IRQ(x,d), IRQ(x,e), IRQ(x,f)
void (*interrupt[NR_IRQS])(void) = {
IRQLIST_16(0x0),
#ifdef CONFIG_X86_IO_APIC
IRQLIST_16(0x1), IRQLIST_16(0x2), IRQLIST_16(0x3),
IRQLIST_16(0x4), IRQLIST_16(0x5), IRQLIST_16(0x6), IRQLIST_16(0x7),
IRQLIST_16(0x8), IRQLIST_16(0x9), IRQLIST_16(0xa), IRQLIST_16(0xb),
IRQLIST_16(0xc), IRQLIST_16(0xd)
#endif
};
#undef IRQ
#undef IRQLIST_161.5linux内核源代码中的汇编语言代码
汇编语言有两套格式,在dos/windows领域中采用的汇编语言都是由intel定义的指令格式,也就是我们教材里面的汇编语言格式。另外一种就是UNIX领域使用的AT&T定义的格式,所以在linux内核中所使用的汇编格式是AT&T。尽管两种汇编语言指令不一样,但是指令的风格很类似,所以提供了一种互相学习的条件。而且AT&T汇编同样适用于gcc编译器,所以在c语言中可以嵌入式汇编语句,所以看懂linux内核代码,需要AT&T汇编基础以及嵌入式汇编基础。这里不详细介绍,后面在进程切换一节中借助一段内核中用来实现内存空间切换的汇编代码来介绍一下嵌入式AT&T汇编。
详细参见:
#define switch_to(prev,next,last) do { \
asm volatile("pushl %%esi\n\t" \
"pushl %%edi\n\t" \
"pushl %%ebp\n\t" \
"movl %%esp,%0\n\t" /* save ESP */ \
"movl %3,%%esp\n\t" /* restore ESP */ \
"movl $1f,%1\n\t" /* save EIP */ \
"pushl %4\n\t" /* restore EIP */ \
"jmp __switch_to\n" \
"1:\t" \
"popl %%ebp\n\t" \
"popl %%edi\n\t" \
"popl %%esi\n\t" \
:"=m" (prev->thread.esp),"=m" (prev->thread.eip), \
"=b" (last) \
:"m" (next->thread.esp),"m" (next->thread.eip), \
"a" (prev), "d" (next), \
"b" (prev)); \
} while (0)前面三条指令用来吧系统空间的寄存器值保存,然后把当前进程esp存入prev->thread.esp,方便后期的返回,然后切换当前esp,把next->thread.esp给到esp寄存器,实现堆栈指针的切换。
http://blog.chinaunix.net/uid-7585066-id-2048718.html
2存储管理
2.1linux内存管理基本框架
好了,了解段式管理和页式管理机制后,我们就可以了解linux内存管理的基本框架了。对于32位地址的内存管理,系统会为每个进程分配4G的虚存空间,linux内核把这4G部分划分为2个部分,一个为系统空间(虚地址0xC0000000到0xF0000000),一个为用户空间(0x00000000-0xBFFFFFFF)。对于系统空间而言,给定一个虚拟地址x,其物理地址是x-PAGE_OFFSET,给定一个物理地址,起虚拟地址为x+ PAGE_OFFSET。#define PAGE_OFFSET 0xC0000000。
这里不深入解释系统空间和用户空间的区别,到了进程管理部分自然明白他的用意。只是这里一直有一个问题,当初看书的时候不明白,我们刚刚讲完段式映射和页式映射,怎么会有上面的虚拟地址到物理地址的映射关系呢?其实这是一个单独设立的映射,只是对系统空间而言是这么管理的,而对于用户空间则还是进行段映射和页映射。因为每个进程都是独自拥有自己的用户空间3G,系统空间却是所有进程共享的。后面介绍页面管理中的页面换入,换出,分配,撤销,都是对用户虚拟空间进行,不考虑系统空间,因为系统空间已经创建,基本不存在换入换出问题(除进程控制块的创建与撤销)。所以,这里就理解为系统空间的映射关系为上,而用户空间的映射就是接下来我们要讲的段映射和页映射的全过程。
1虚拟地址(存在于进程创建时系统分配的进程控制块中)通过段映射得到线性地址。
2线性地址通过页映射得到物理地址。
2.2地址映射全过程
这里需要再介绍linux的这两个过程,其实有了分页管理机制,根本用不着段式管理,但是硬件厂商这么做了,而且考虑到兼容性问题,也不好去掉段式管理这一步。但是linux巧妙的忽略了段式管理的作用,而直接使用分页管理,具体的实现过程是这样的。将段地址描述结构中的基地址统一设置成0,这样虚拟地址就等同于线性地址,然后直接转换成物理地址。具体实现过程见代码。
2.3几个重要的数据结构和函数
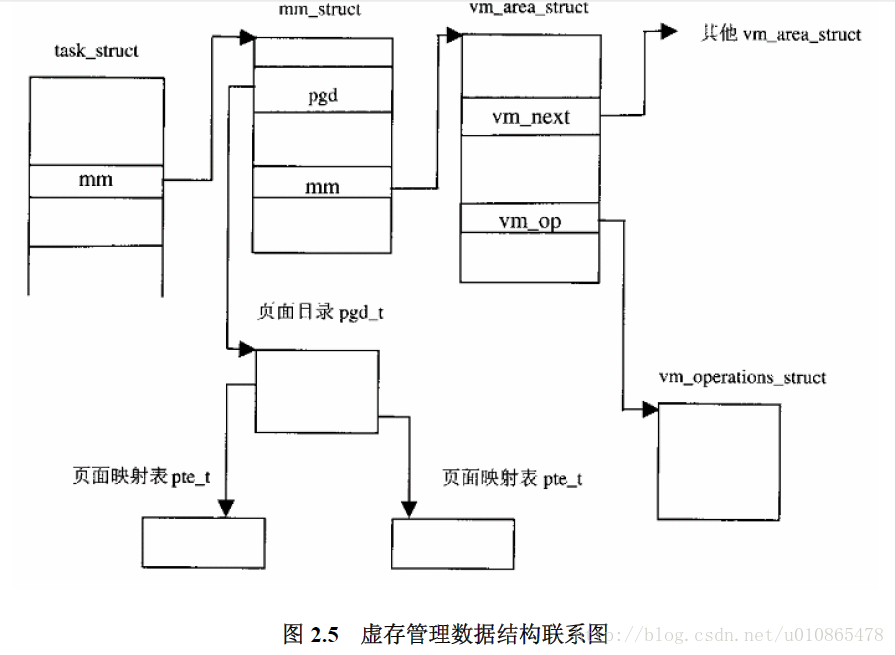
从上面这张图就能看出,内存管理需要由数据结构来组织的,通过函数来实现,具体看代码,其实并不难理解。
2.4越界访问
需要注意的是这里的越界访问别理解为我们程序当中的数组越界,这里是指访问不在内存中的页面。主要有三种情况
1相应的页面目录项和页表项未空,也就是线性地址与物理地址的映射关系尚未建立,或者已撤销。
2映射关系有,但相应的页面不存在内存中
3指令中规定的访问方式与页面的权限不符
上面三种情况都会产生越界访问,cpu就会产生一次页面异常。然后根据不同的情况做相应的处理。
2.5用户堆栈的扩展
不知道大家有没有想过为什么会有上面三种情况,他们是怎么产生的,下面我先介绍第一种,其主要是进程创建之初或者后期用户对堆栈的扩展,因为在这之前都没有建立页面目录和页表项,然后需要注意的是,在建立页面目录和页表项的同时,我们不光在内存上分配页面目录项和页表项,而且需要把虚存上的内容拷贝到内存页面上,即一页4K,但不一定是建立完全,可以慢慢来嘛,这也就是为什么那么多的进程可以同时运行在计算机上,当他们所占的内存总和大于内存实际大小时,操作系统同样能使其有条不紊的运行。这里举个例子,想象一下,比如要铺设从南昌到北京的火车轨道,需要最短的轨道长度是多少,答案不是两点线段最短,而是只需要火车的长度就行,因为我们可以拆东墙补西墙,理论上只要我们铺轨道的速度足够快的话,那么火车就好像一直行驶在轨道上了,多么了不起的理论啊,哈哈。
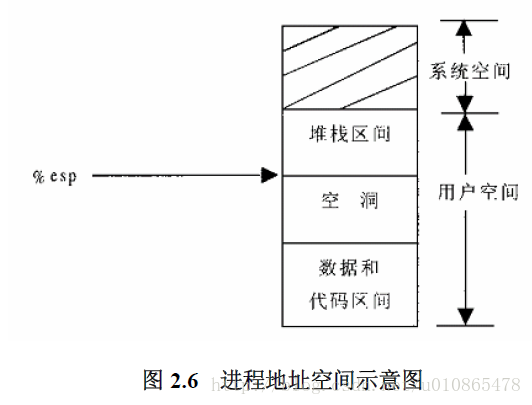
当用户进程申请扩展堆栈区间时,由于申请的部分还没建立页面映射,所以会产生一次缺页异常,然后建立页面映射,在内存分配页表,而且分配一部分必须的页面空间。
2.6物理页面的使用和周转
上面讲了缺页异常的第一种情况,下面介绍第二种,既然建立了页面映射表,为什么内存中么有页面呢,当然可能最开始分配页面时未能一次分配完全,但跟多是因为用户空间下的页面是需要页面管理的,其中包括交换。关于页面置换,就必须思考几个问题,换出的页面放在哪,什么样的页面可以换出?
计算机技术发展的早期就有了把内存和一个专用的磁盘空间“交换”的技术,就是暂时把不用的信息放到磁盘上,为其他急用的信息腾出空间。在介绍物理页面周转之前,先理解物理页面,我们知道,每一个内存上的物理页面都自己的页表,就好像一本书一样,每一页都有页面号。那么磁盘上的页面呢,既然我们换出后是放在磁盘上,那么也必须建立一种页面映射机制,方便在磁盘上找到页面。
这里使用一个swp_entry_t的数据结构来标识一个页面,其实就是一个32位的无符号整型数。其中offset表示页面在那一个磁盘设备或者文件上的位置,也就是文件中的逻辑页面号,type则指明哪一个文件中。也就是指明哪一个文件,文件中的那一页。

好了,两种映射关系有,就可以进行物理页面的周转。周转有两方面意思,其一是页面的分配,使用,回收,并不一定涉及页面的盘区交换,其二才是盘区交换,也就是内存页面与交换设备页面进行交换。但是需要注意的一点是,我们前面就讲过这里的交换页面只针对用户空间下的页面,系统空间页面不存在换入换出问题。下面就介绍两类页面的交换,一类是,用完后没有保存价值的页面,对于这样的页面我们直接换出,换出的过程当然也涉及到会写(有修改才回写),另一类是用完后,现在暂时不用,但是有保存价值的页面,对于这样的页面我们采用缓存技术,只要内存条件允许,就把这些页面养起来,就是建立一个LRU队列,把进过LRU最近最久未使用算法挑选出来的页面放到这个队列中,直到条件不再允许时,才真正把其换出,最后才进行会写(也是修改了才回写,是否修改需要标志来标识)。
2.7物理页面的分配
物理页面的分配,其中物理页面可以是连续的也可以是不连续,但是连续的内存页面方便内存管理。那么怎么分配合适物理页面。人们提出很多的分配算法,这里面确实有很多需要考虑的,当然其中不得不讲的就是伙伴系统分配方式了。也就是把内存分成一系列大小不一的块,如16k,32k,64k,128k,然后为这些大小不一的内存块建立多个链表,把大小一样的内存块块链入一个链表,然后当有进程需要分配内存块时就逐个比较,找到合适块(一定大于等于)进行分配,把分配后剩下的部分链入小的空闲内存块链表上。但是有个问题,这样会造成大量小内存块到最后因为找不到合适而无法分配出去。而且其中也涉及到进程需要的分配内存的和空闲的内存大小的问题,这些都是操作系统得解决的问题,实际过程中有很多因素需要考虑,这就像是供和需的博弈一样,关键在操作系统,当博弈成功,系统就分配物理页面,不成功,操作系统会采取各种措施来实现分配,比如换出暂时不用的页面,需求页面能否降低一点要求,能不能向预留的空闲内存借。绝大所数情况是一次就能分配成功的。
2.8页面的定期换出
页面定期换出的目的就是尽力为了在换入新页面时有空闲页面,注意是尽力而为,因为即使定期换出也不能完全杜绝缺页异常发生时内存没有空闲页面,只好临时寻找可以换出的页面解急需。为此,linux内核中设置了一个专门定期将页面换出的kswapd进程。虽然是系统提供的,但它有自身的进程控制块,同其他进程一样受内核调度。其代码实现是循环的进行一系列的页面换出操作,每次循环最后会调用一个sleep进入睡眠,让内核只有的调度其他的进程运行。但是内核会在一定的时间内会把他唤醒,一定的时间取决于时钟中断。
具体换出页面的代码就不多说了,主要根据内存的当前转态分级别的把可以换出的页面换出,以便腾出更多的空闲空间,尽力减少缺页异常的发生。
2.9页面的换入
页面的换入主要是针对已经建立好了地址映射,但是页面不在内存中的页面。记得前面讲过换出的过程,其实换入就是一个逆过程。先到缓存中去找,如果在缓存中找到了,那就直接换入,也就是把该页面从缓存队列脱链,加入到活跃的内存队列中。如果在缓存队列中找不到,那就只好到磁盘上去找,因为我们在换出的时候,已经把它的内存映射改成了磁盘映射,所以我们能通过磁盘映射载磁盘上找到页面,并把它拷贝到内存上,并加入内存队列,修改为内存映射,
2.10内核缓冲区管理
内核缓冲区的作用是用来缓存一些经常需要操作的信息,而这些信息的大小又大小不一,不好像堆栈一样随用随分配,而是采用slab的缓冲区分配和管理的方法,
一个slab可能由1,2,4,最大32个连续的物理页面构成,每个slab通过指针链接起来,这样就方便不同需要时创建,而不浪费内存,而且链接起来方便查找。
2.11外部设备存储空间的地址映射
其实这就是我们操作系统课程上讲到的外部设备编址的问题,一种是采用内存映射,外部设备的存储单元,如存储单元,控制单元,状态寄存器,数据寄存器,都作为内存的一部分出现在系统中,这样cpu就能像访问内存一样访问外部设备。一种采用I/O映射,外部设备存储单元与内存分属不同体系,访问内存的指令不能用来访问外设。现在一般采用前者,Linux内核中,通过ioremap()函数来建立映射。
2.12系统调用brk()和mmap()
这里我只想用两句话来说明这两个系统调用的作用,前者是用于内存页面的分配时,建立页表与内存页面之间的映射,当然包括把页面拷贝到内存,后者则是在创建进程时,建立虚存空间和具体文件之间的映射。但是需要注意的是建立映射的过程中完成很多复杂的需求,比如用函数指针来绑定一些对页面的操作。这两个系统调用的实现过程其实并不简单,非常值得研究,具体还是参看书籍。
3中断,异常和系统调用
3.1概述
中断,异常和系统调用可以说是进程管理的基础,没有这三种机制,可以说无法实现现代操作系统的进程管理,当然这只是必要条件了,所以在进程管理之前有必要理解中断,异常和系统调用
中断:通常人们把中断分为两种,外部中断和软中断,其中外部中断是用来相应外设的请求的,所以很多的书籍把中断放到I/O设备章节中介绍,但并不是特别合理,我个人认为中断不一该这狭义的理解,我觉得吧中断,异常和系统调用统一理解为一种管理机制更合适,而且他们之间有很多相似之处。另外一种软件中断,又成陷阱,是进程主动请求的,又成同步,其实同步和异步是一个很抽象的概念,后面讲进程通信再来细说吧。
异常:异常一般是由于“不小心”犯规产生的,比如除0,当然也不排除故意安排的,如缺页异常。
系统调用:可以说,计算机的安全很大程度上是因为有了系统调用,因为他扮演这用户与硬件交流的信使,当然上面两个也是,但系统调用在一个程序中用的更多,而且没有系统调用,可以说一个进程根本无法运行,因为进程创建都必须进过系统调用。
上面三者有很强的相似性,都可以理解为一个执行流顺序执行过程中,有意无意的被打断而去执行另一段执行流,所以把他们三者理解为一种管理机制更为合适。
3.2x86cpu对中断的硬件支持
早期的intelx86cpu支持256个不同的中断,在实模式下,cpu把内存从0开始的1k字节作为一个中断向量表,每一个中断向量号占4字节,刚好256个中断,而且中断向量号乘4就是中断向量表的地址,在中断向量表中存放的中断服务程序的入口地址,这样程序就可以转入中断服务程序执行。在保护模式下,中断相应机制采用了基本的段式内存管理,中断向量表改称为“门”,每一次中断都必须通过这扇门,才能进入中断服务程序,当然门是有要求的。 为了实现这个过程,cpu增加了一个寄存器IDTR,用于指向中断门的基地址,而且按不同的用途,cpu中共设有四种门。
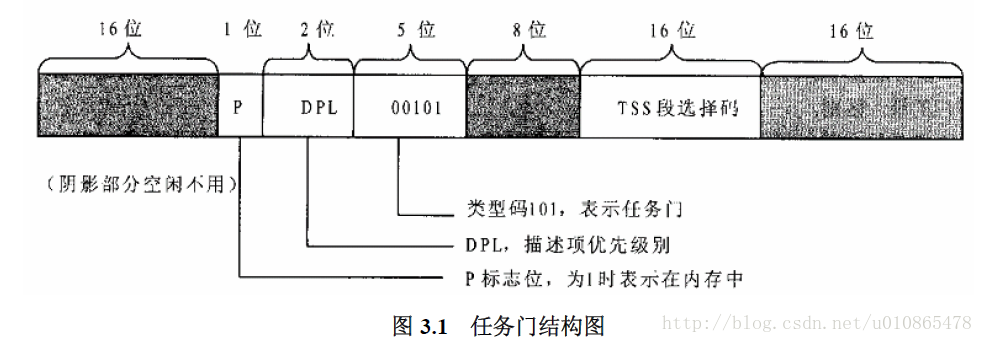
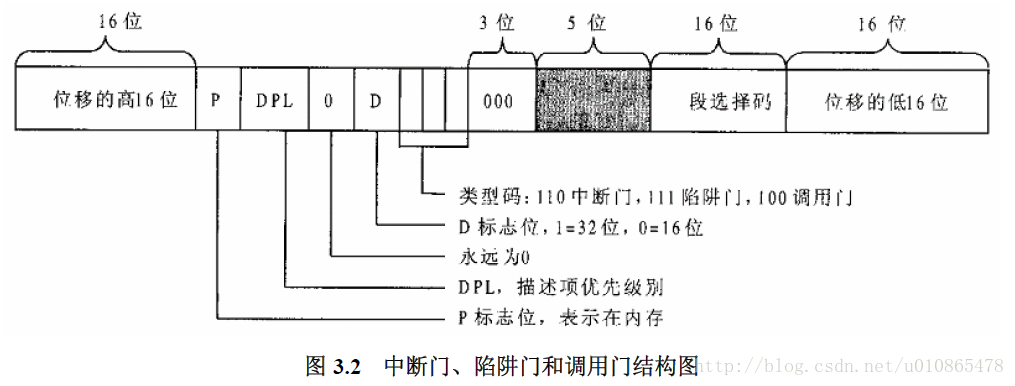
,然后中断相应的过程就是,中断向量号地址加上IDTR寄存器中的基地址得到中断门的地址,然后进入中断门,对权限进行比较,合格是则从中断门中取出中断服务程序的偏移地址,同样进过GDTR指向的段地址描述结构的基地址相加,得到中断服务程序的入口地址,此过程类似于段式内存管理,但是却不失麻烦。
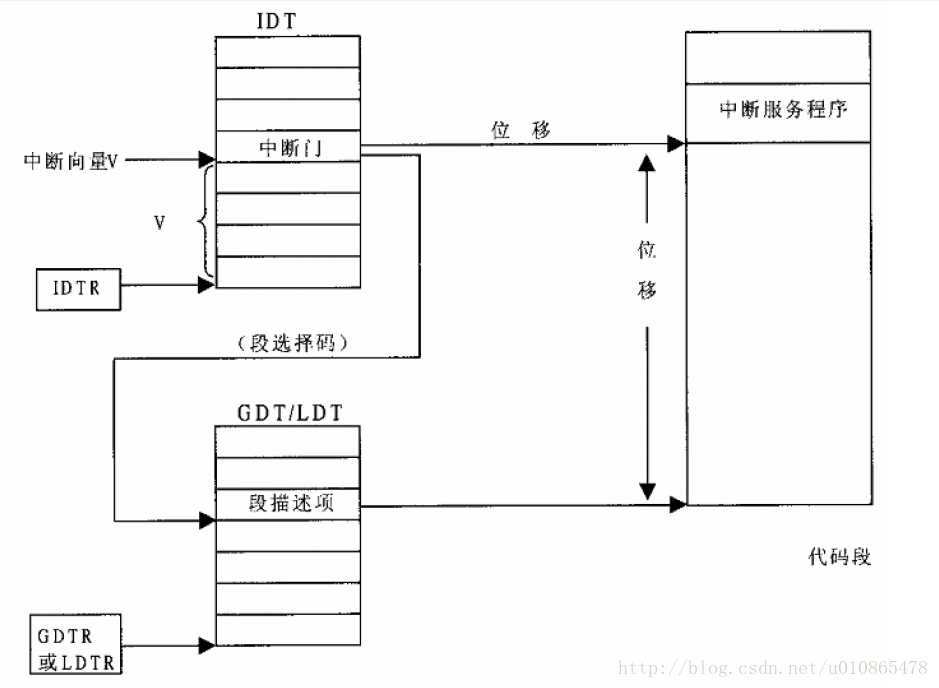
3.3中断向量表IDT的初始化
上面介绍完中断机制的硬件支持后,我想下面就得开始软件对这些硬件支持的初始化工作了,首先,IDTR中断门基地址寄存器初始化,这个很简单,就是指向中断门的基地址就行,然后就开始对中断门IDT进行初始化了,也就是对中断号和中断服务程序建立映射关系,方便程序通过中断向量号找到相应的中断服务程序。这个交给trap_init()函数,具体实现过程看代码,其中有汇编和宏定义来实现。其中一个很重要的中断-时钟中断,但此时还不能进行初始化,因为进程调度机制还没初始化话,一旦时钟中断开始,进程调度也就要随之开始,他就像动物的心跳一样。
3.4中断请求队列的初始化
上面讲的中断向量表IDT中有两种表项,一种是专为cpu本身的中断门,主要用于cpu异常,INT指令产生中断,系统调用,第二种则是通用中断门。两者的区别在于通用中断门可以为多个中断源所共享,而专用中断门则是为特定的中断源专用。所以,有共享的话,那么就必定会有多个中断源对应一个中断号的情况,那么多个中断源就必须要有组织,有纪律,所以这里又要用到队列来组织多个中断源公用一个中断号的情况,那么要实现中断机制,必须对中断请求队列进行初始化。
3.5中断相应和服务
好了,有了上面的准备工作之后,我们就能开始享受中断服务了,具体中断向右和服务我们还是走一遍。
这里有必要说清楚一下,中断是不允许嵌套的,所以进入中断,异常,系统调用之前中断一定是关闭,而中断,异常,系统调用都是运行在系统空间的,所以,只有等到从系统空间返回用户空间后,才从新开启中断,也就是说,要进入中断,一定是进程运行在用户空间时,来了一个中断,系统才会去响应。
那么,当中断请求到来时,系统先要保留现场(其实就是当前一些寄存器的保存),以便执行完中断服务程序之后返回。
但是这里需要说清楚一个关键的部分,进入中断服务程序后,为什么要把中断向量号压栈,这里是系统设计者有意安排的,因为在中断服务执行完后恢复现场后,不会立即回到进入中断前的状态,而是先比较中断向量号(此时还是在系统空间),是否可以安排一次进程调度,因为中断执行完后,各个进程在进程调度准则中的优先情况又发生了变化,所以这是一次精心的安排。同样,对于异常,系统调用也是这样,当然一些准备工作也是需要的,比如系统调用表。
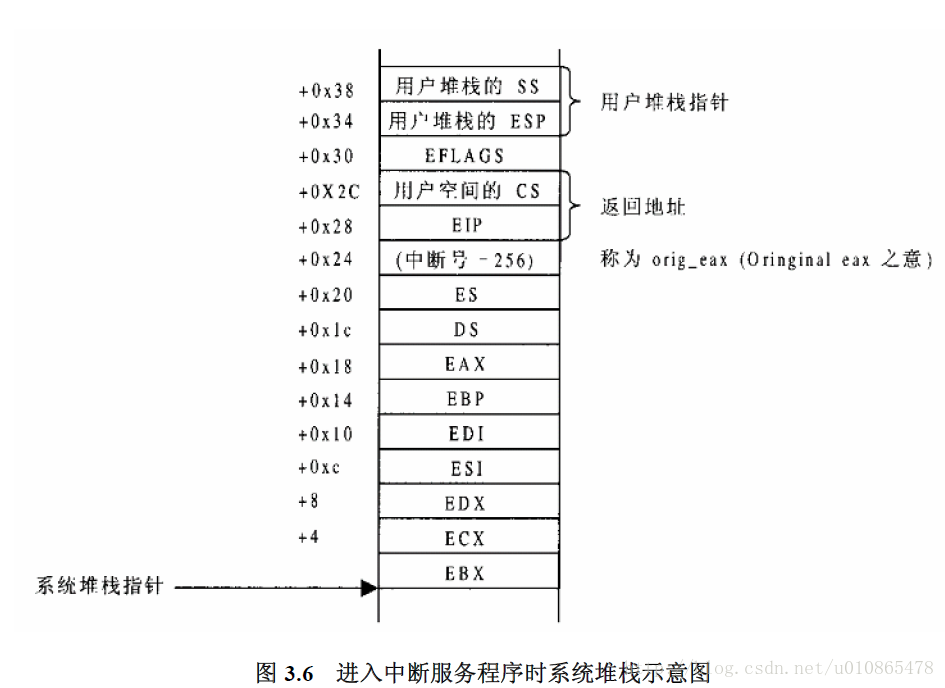
程序关键部分
if (!(action->flags & SA_INTERRUPT)) //权限检查
__sti();//关中断
do {
status |= action->flags;
action->handler(irq, action->dev_id, regs);
action = action->next;
} while (action);//循环判断中断请求队列中是否还有未执行的中断
if (status & SA_SAMPLE_RANDOM)
add_interrupt_randomness(irq);
__cli();//关中断
irq_exit(cpu, irq);//退出中断3.5软中断与Bottom Half
由于中断服务程序一般都是在关闭中断的情况下执行,以避免中断嵌套的复杂性,但是如果中断服务程序执行时间过长,这样显然是不合适的。为了解决这个问题,人们又吧中断执行过程分成两部分,一部分是必须要求在关中断条件下执行,成为硬中断服务程序,另一部分则不要求一定在关中断条件下执行,成为软中断,这也就是这一节讲的软中断。所以这样的话,我们可以在执行完硬中断部分提前的开启中断,可以让cpu响应其他的中断请求。具体的实现看代码
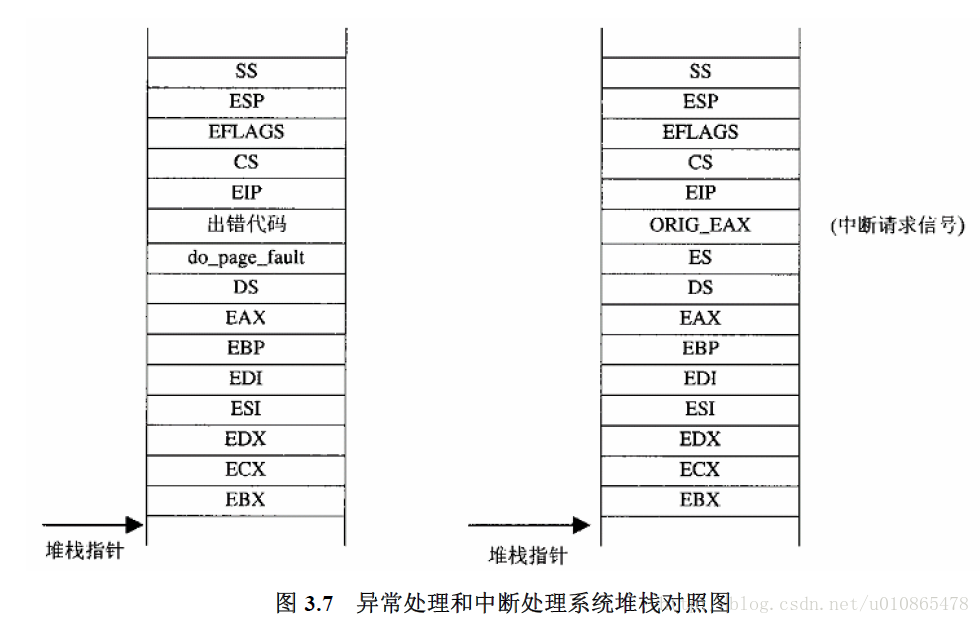
3.6页面异常的进入和返回
由于异常和中断很类似,所以,下面一张图就能说明缺页异常的过程了。
3.7时钟中断
时钟中断的作用远非计时这么简单,想想,进程调度过程中,加入一个进程不自愿的放下cpu占有权,赖这不放怎么办,这是时钟中断就起到很重要的作用了,时钟中断会每隔一定的时间结束长期霸占cpu的进程,进入系统调用,安排下一次进程调度。当然,时钟中断还有另外一个很重要的作用,那就是对于一些对时间有要求的进程,它们必须用到时钟中断,比如,用计算机控制一个舵机运行,而舵机的工作方式一般是PWM波来控制的,也就是电流变化满足一定的占空比来驱动舵机转动,那么就需要隔一定的时间来执行一段程序,那么要达到度一定时间的精准把握,那么显然需要用到时钟中断,也就是根据主频,把时间换算成计数,每当计数器满时,执行一次时钟中断。当然时钟中断的控制方式与硬件和软件都有关,微机原理教材中也提到过。
3.8系统调用
前面已经说明了系统调用的重要性,只有通过系统调用,进程才能从用户空间进入系统空间,linux中严格区分系统空间和用户空间(虽然硬件上设计了4个不同的权限,但linux只是用系统态和用户态两种),系统调用过程可以和中断过程一样理解,因为他们的机制是相同的,但还得再说一遍,用户程序是碰不到计算机硬件的,其中大多数情况下是通过系统调用才有资格和计算机打交道。
3.9系统调用号和跳转表
同中断一样,系统调用也有很多种,所以也需要有一个类似于中断向量表一样的结构来组织不同的系统调用。我们称之为系统调用号和跳转表。
4进程与进程调度
从大致的方向上理解,可以说操作系统的两个重要管理就是进程管理和文件管理,进程管理可以说是对cpu以及内存的管理,而文件管理可以说的对外设的管理,当然进程管理的前提得建立在内存管理基础上,进程通信是属于进程管理的一部分,而文件管理的前提则是设备驱动了。所以操作系统 的几个重要部分就是内存管理,进程管理,文件管理,设为驱动。
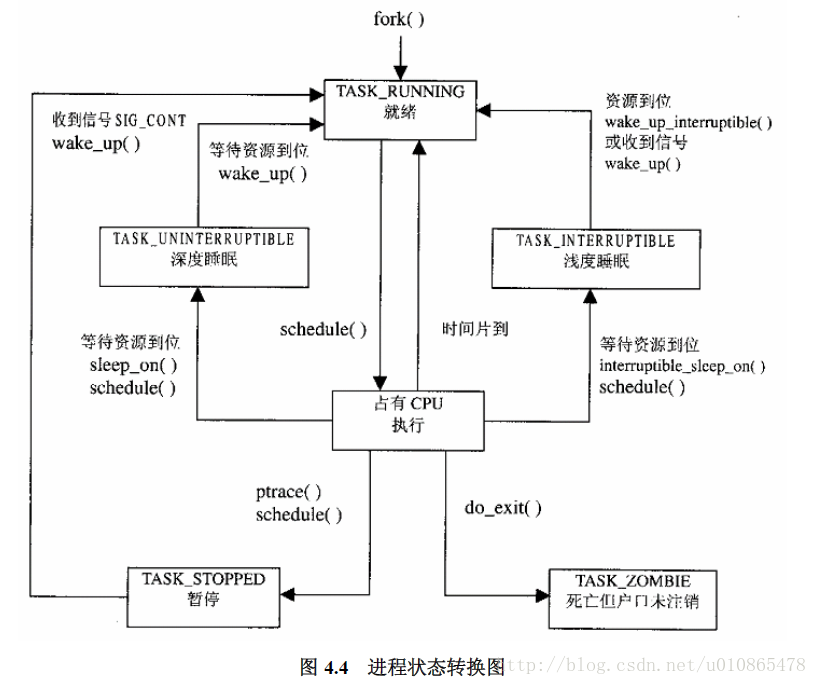
4.1进程的四要素
相信学过操作系统的同学都知道进程这个概念,但肯定有一部分同学无法说清楚进程是什么,只知道进程是程序运行的一个实例。的确,在我学完操作系统课程之后,我依然无法说清楚进程是什么,直到我看了计算机系统这本书,我才有了一个概念,那就是进程不是什么,它是一个抽象的概念(文件其实也是一个抽闲的概念),一张图让我明白进程这个概念。
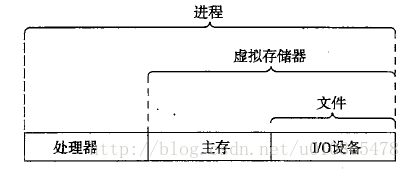
然后此书上给出进程的四要素,让我对进程有了一个更深的理解
1有一段程序供其执行,这段程序不一定是进程所专有,可以与其他进程公用
2有前面的“私有财产”,就是进程专用的系统堆栈空间,系统空间不是独立的,任何进程不能直接改变系统空间的内容(除自身的系统堆栈空间)
3有“户口”每一个进程都必须有一个task_struct数据结构,有了这个结构,才能成为内核调度的一个基本单位接收内核调度,而这个数据结构在系统空间下。
4有独立的用户空间,这部分是供进程独自占有的
然后,书中有这么一段话(帮助大家度进程和线程有一个了解):缺少上面的任何一条都不能称为进程,如果只具备前面3条,那就称为线程,如果完全没有用户空间,就称为“内核线程”,而如果是共享用户空间则称为“用户线程”。
其中系统空间堆栈用于分配下面2页内容
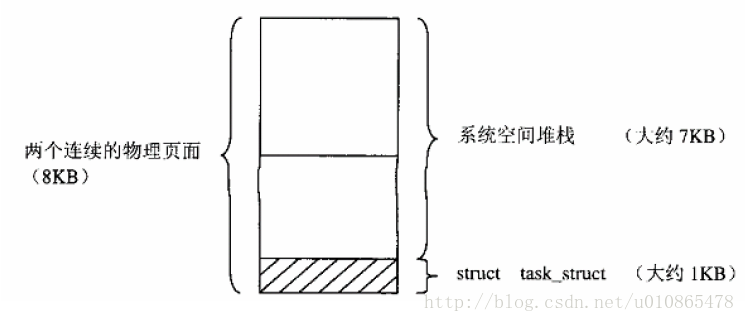
其中非常有必要介绍一下进程控制块task_struct数据结构,里面包含了一个进程各种信息,进程调度得以实现,绝大功劳归功于进程控制块,还是非常有必要列举一下的。
struct task_struct {
/*
* offsets of these are hardcoded elsewhere - touch with care
*/
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
unsigned long flags; /* per process flags, defined below */
int sigpending;
mm_segment_t addr_limit; /* thread address space:
0-0xBFFFFFFF for user-thead
0-0xFFFFFFFF for kernel-thread
*/
struct exec_domain *exec_domain;
volatile long need_resched;
unsigned long ptrace;
int lock_depth; /* Lock depth */
/*
* offset 32 begins here on 32-bit platforms. We keep
* all fields in a single cacheline that are needed for
* the goodness() loop in schedule().
*/
long counter;
long nice;
unsigned long policy;
struct mm_struct *mm;
int has_cpu, processor;
unsigned long cpus_allowed;
/*
* (only the 'next' pointer fits into the cacheline, but
* that's just fine.)
*/
struct list_head run_list;
unsigned long sleep_time;
struct task_struct *next_task, *prev_task;
struct mm_struct *active_mm;
/* task state */
struct linux_binfmt *binfmt;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned long personality;
int dumpable:1;
int did_exec:1;
pid_t pid;
pid_t pgrp;
pid_t tty_old_pgrp;
pid_t session;
pid_t tgid;
/* boolean value for session group leader */
int leader;
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->p_pptr->pid)
*/
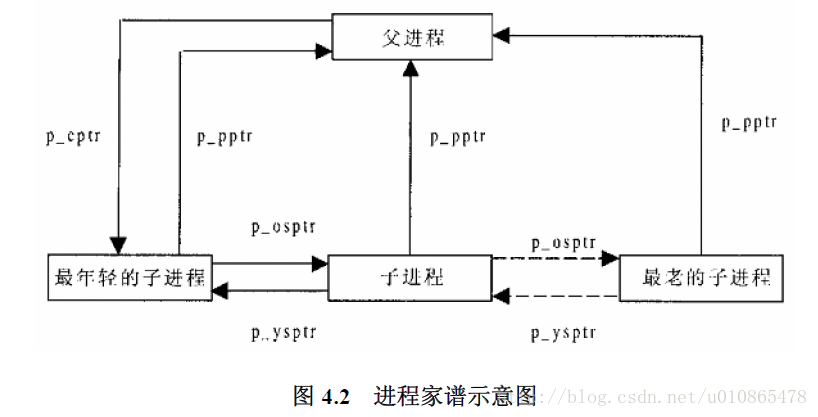
struct task_struct *p_opptr, *p_pptr, *p_cptr, *p_ysptr, *p_osptr;
struct list_head thread_group;
/* PID hash table linkage. */
struct task_struct *pidhash_next;
struct task_struct **pidhash_pprev;
wait_queue_head_t wait_chldexit; /* for wait4() */
struct semaphore *vfork_sem; /* for vfork() */
unsigned long rt_priority;
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_incr;
struct timer_list real_timer;
struct tms times;
unsigned long start_time;
long per_cpu_utime[NR_CPUS], per_cpu_stime[NR_CPUS];
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;
int swappable:1;
/* process credentials */
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
int ngroups;
gid_t groups[NGROUPS];
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
int keep_capabilities:1;
struct user_struct *user;
/* limits */
struct rlimit rlim[RLIM_NLIMITS];
unsigned short used_math;
char comm[16];
/* file system info */
int link_count;
struct tty_struct *tty; /* NULL if no tty */
unsigned int locks; /* How many file locks are being held */
/* ipc stuff */
struct sem_undo *semundo;
struct sem_queue *semsleeping;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* signal handlers */
spinlock_t sigmask_lock; /* Protects signal and blocked */
struct signal_struct *sig;
sigset_t blocked;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty */
spinlock_t alloc_lock;
};操作系统在一开启之时,就有创建了一个init进程(不要问第一个进程又是怎么创建,可以看系统启动的过程),然后其他的进程都是由这个进程通过系统调用复制出来的,然后一个进程又可以创造出另一个进程,这就有下面这个进程家族谱。
4.2进程三部曲:创建,执行,消亡
不同的操作系统进程的创建也不一样,这里我们只说linux操作系统,每一个进程的创建都需要父进程(别问init),子进程通过fork(),clone()创建一个基于父进程一样的进程,他们之间的区别在于子进程继承父进程资源的多少问题,fork是完全继承,而clone是有选择性的继承。其中继承的资源有,系统空间和用户空间,但是子进程有自己的进程控制块。好了,进程创建好了,可以开始执行么,显然,和父进程一样的子进程有何用,子进程必须得独立起来,这就到第二步,子进程铜鼓execve()加载自己的目标程序,然后子进程和父进程分道扬镳,走自己的路。那么父进程呢,父进程有三种选择,1继续走自己的路,与子进程分道扬镳,如果子进程先于父进程“去世”则有内核给父进程发一个报丧信号(若父进程没有收到,那么子进程就成立僵尸进程,需要init进程来处理)。2停下来进入睡眠,等待子进程结束后唤醒父进程。3父进程结束自己的生命,此时子进程就成了孤儿进程,全部都指向init作为自己的父进程,子进程结束后统一给init进程发信号。
4.3系统调用fock(),vfock(),clone()
Fork(),vfork(),clone()三个系统调用都是通过调用do_fork()来实现子进程的创建,唯一不同的是传递的参数不一样,而do_fork()则根据参数的不同,有选择性的继承父进程的资源,子进程创建过程如下:
1分配进程控制块alloc_task_struct(),包括进程PID,同时把进程控制块加入进程队列中(而且不止一个队列,最少三个),完成进程家谱
2继承父进程已打开的文件,继承文件系统
3继承父进程的信号
4继承父进程的用户空间,只是单单建立虚存映射,并没有拷贝页面到内存
5继承父进程的系统空间堆栈
/* copy all the process information */
if (copy_files(clone_flags, p))
goto bad_fork_cleanup;
if (copy_fs(clone_flags, p))
goto bad_fork_cleanup_files;
if (copy_sighand(clone_flags, p))
goto bad_fork_cleanup_fs;
if (copy_mm(clone_flags, p))
goto bad_fork_cleanup_sighand;
retval = copy_thread(0, clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_sighand;
p->semundo = NULL;4.4系统调用execve()
好了,复制完父进程的资源后,子进程开始走自己的路了,但是在走自己的路之前,必须得有自己的东西,那么接下来它需要做下面几步
1打开可执行文件,这里在创建进程之初时,会传递一些必要的参数,其中就包括可执行文件的路径,对比一些信息,判断是否有问题(包括很多细节问题,比如文件路劲长度),没有问题则继续下一步。
2加载可执行文件,可执行文件的类型有很多,这里仅介绍a.out格式目标文件,其文件具备一定的格式,加载过程中会对比文件内容,判断文件是否符合格式,符合则继续
3现在,进程需要告别从父进程继承下来的东西了,如信号,映射,打开的文件,同时释放用户空间共享计数,并建立自己的信号表,映射,内存页面分配(前面只是建立了映射,并没有物理页面的分配),同时,在进入子进程调用exeevc()调用前,父进程执行了down()操作,也就是信号阻塞自己,是自己进入睡眠,那么现在execve()结束后必须的up()唤醒父进程。
4.5系统调用exit(),wait()
exit()系统调用是用来结束一个进程,一个进程的结束,那么就必须得释放它生前所占有的资源,但是有部分资源是他自己不能主动释放的,必须交给父进程来处理,然后还有一个很关键的问题就是,别忘了,我们创建进程时可有一个很严密的进程家谱网,现在一个进程要结束,那么很自然要修改这个家谱。具体过程不究,只讲两个关键问题。
1, 一个进程结束自己后,他的子进程就成孤儿了,它需要发送一个信号给它的所有子进程,然后修改子进程的父进程指针,统一指向init
2, 一个进程结束自己后,它必须的通知它的父进程,最后给它收尸(获得一个信号,然后释放子进程结束后还占有的资源)
注意,对于程序员来说,debug是一个非常关键的系统调用,他能让我们跟踪进程的执行情况,那么这里跟踪的实现也是通过一个进程pr来实现的,被跟踪的进程同样成为子进程,主动跟踪的进程则为其养父进程,而且一个进程一旦被跟踪,那么它的养父就得履行他作为父进程的职责,而亲父进程就显的不那么重要了。
wait()调用可以说是进程同步的一个系统调用,因为之前讲过父进程的情况又三种,其中一种就是等待子进程结束,那么wait()系统调用就是这么一个作用,使自己进入睡眠,并进行一次进程调用操作,直到子进程结束后发送一个信号量唤醒父进程,重新让父进程挂入活动进程队列,参与进程调度。
4.6进程的调度与切换
一个好的系统的进程调度需要兼顾三种不同应用的需求
1交互式,着重于系统的相应速度,使公用一个系统的用户都感觉自己是独占系统资源,也就是常理解的分时系统
2批处理,着重于平均响应速度,常理解为多道批处理系统
3实时,对时间要求特别严格的应用,常理解为实时系统
为了满足上述目标, 设计一个进程调度机制时需要考虑的具体问题如下
1调度的时机
2调度的策略
3调度的方式是否是可剥夺还是不可剥夺的
其中设计的最关键在于调度的时机与是否可剥夺,至于调度算法那可以作为一个模块单独来考虑,尽管一个好的调度算法很重要,但是对系统的框架却无足轻重。
调度时机,首先看自愿调度,在内核(系统空间)里面,一个进程可以通过schedule()系统调用启动一次调度,当然也可以在次之前在系统空间把本进程设置为睡眠转态,来达到进程调度的目的。在用户空间下可以通过pause()系统调用是本进程睡眠来执行一次进程调度,而nanosleep()系统调用同样可以为只一次自愿暂时放弃运行加上一定的时间限制。除了非自愿地情况,系统也可以强制的在每一次系统调用,中断服务返回之前,强制的执行一次进程调度(前面讲中断返回时提到过,中断向量号压栈的目的,可以在返回用户空间之前执行一次进程调度)。还有就是对于linux内核的调度方式来说是一种“有条件的可剥夺”方式,当进程在用户空间运行行,一直霸占cpu时间过长,那么时钟中断就必须出来阻止这样的情况了,也就是说该进程的时间片用完了,必须强制执行一次进程调度。
调度的策略:为了适应不同的应用,内核设计了三张不同的调度政策:分时,多道,实时。每一次进行进程调度时,都会根据预先设定好的调度算法来计算每一个进程的优先权值,权值越高,则越有机会被调度执行。
每次执行进程调度,调度前后不同的进程占有cpu执行,那么就涉及到进程间的切换问题。由于用户空间下不能直接切换,每一次进程的切换总是发生在用户空间进入系统空间,然后执行调度,然后从系统空间返回用户空间,所以这里的切换就是只系统空间和用户空间之间的切换。代码分析部分作为嵌入式汇编语言分析实例。
4.7强制性调度
强制性调度发生在三种情况下
1在时钟中断服务程序中,当发现当前进程连续运行时间过长
2当唤醒一个睡眠中的进程,发现被唤醒的进程比当前进程优先权值更高
3一个进程通过系统调用改变调度政策或礼让,这种情况实际应该被视为主动的,自愿的调度,这种情况下也会理解执行进程调度
4.8系统调用nanosleep()和pause()
前面说过,nanosleep()是用来让当前进程进入睡眠,并且一定时间内唤醒的一个系统调用,pause()则是在用户空间下用来执行进程调度的系统调用,还一种特殊情况,当前进程收到一个SIGSTOP信号后,会在一次系统空间返回用户空间之前执行一次schedule()进程调度。
他们的实现过程就不多讲,看代码。
4.9内核中的互斥操作
内核中很多操作在进行过程中都不允许被打扰,最典型的就是队列操作,如果两个进程都要将一个数据结构链入到同一个队列队尾,要是再第一个进程完成一半的时候发生了调度,第二个进程插进来了,那么结果就乱了。类似的干扰也会发生在某个中断服务程序中 bh函数,(系统调用,异常??)在多处理结构系统中,还要考虑来至另外一个处理器的干扰。所以互斥操作就显得很重要了。简单两种机制就是信号量和锁。信号量一般用于解决进程间互斥问题,而锁则有很多种类,其中自旋锁常用于多处理器之间互斥操作。
信号量: 简单的理解用信号量来表示某种资源(一般资源数大多为1),使用一次down一次,直到为0后就不允许使用,需要使用的进程都暂时进入睡眠状态,等其他进程使用完up一次后又资源可以使用后再唤醒因此资源而睡眠的进程,一次只能唤醒一个。然候需要注意的一个问题就是当两个进程A,B分别申请资源a,b而进程A申请到a,进程B申请到了b,而彼此必须两者都拥有才能执行下次,那么AB之间就陷入了死锁,为了避免死锁,也提出了很说算法,其中最简单就是按序申请,或者一次性能拿到所有资源的进程才允许分配(如银行家算法)。
自旋锁:当不同的处理器访问临界资源时,其中一个处理器允许访问,那么另外一个处理器就必须等待,那么这是处理器干嘛呢,能不能做其他的事呢,对于自旋锁而言,另外一个处理器是什么都不做,一直在循环做无用功,看上去有那么点浪费,但也没办法,只能把处理器锁住。相比较要保证一个操作的原子性而把总线锁住,多处理器锁住一个处理还算节约的啦。
5文件系统
其实,进程管理部分还没有完全讲完,所以上面的章节也不完全叫进程管理,而是叫进程与进程调度,进程管理还有一个很重要的部分,那就是进程通信了,但是进程通信很大程度上要依赖文件系统的存在(或者说借助文件系统的机制),所以在介绍进程通信前,很有必要理解文件系统。
5.1概述
Linux除了提供对自己本身的ext2文件系统的支持以外,同样为了提供对其他文件系统的支持,linux提供虚拟文件系统VFS。
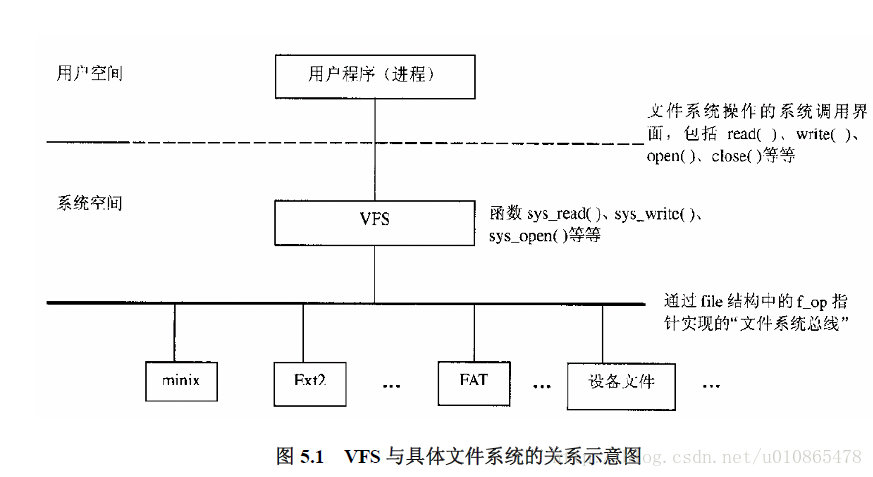
同样,在进程控制块中也包括文件的信息
有
struct task_struct {
/* filesystem information */
struct fs_struct *fs;//指向文件系统的信息
/* open file information */
378 struct files_struct *files;//指向已打开的文件信息
}下面为文件系统的逻辑结构图,其实都是通过数据结构来进行描述的
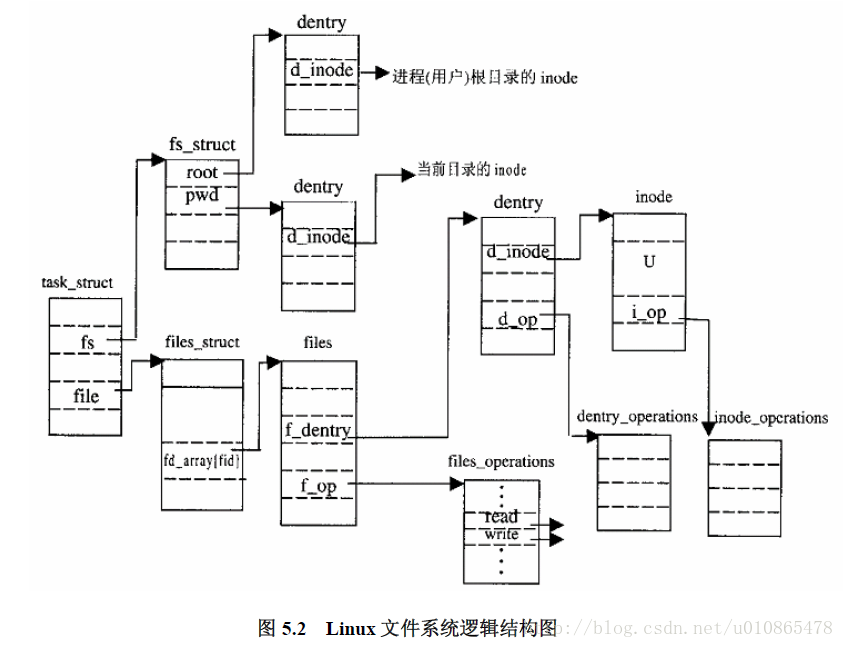
对于文件的理解不能简单理解为存储在磁盘上的文件,linux中有三种不同类型的文件
1磁盘文件,也就是具有存储作用,我们常理解的文件,这一类文件具备文件系统逻辑结构的数据结构,这也是标识一个文件的方式
2设备文件,前面就讲过,文件可以理解为是一个抽象的概念,对于具体的设备可以抽象出来看着设备文件,同样设备文件也具备上面的数据结构,但不一定有存储数据。
3特殊文件,这一类文件,可以理解为是借助了文件系统的逻辑结构来实现一些特殊的作用,其主要作用就是用来进程通信了。所以这一类特殊的文件也具备文件的一般数据结构,如fifo,socket,proc。
5.2从路径到目标结点
有了文件系统,文件就好管理了,linux文件系统结构上就像一棵倒立的树,同样,遍历文件系统查找文件就像是树的遍历一样,通过文件提供的路径,一个一个节点的匹配下去,而每一个节点的匹配也正是字符串的匹配,每一个字符串的匹配就是一个一个字符的比较,可想而知,这样的工作量有多大,所以算法的作用又体现出来的,这里采用一种杂凑表的形式来建立一个专门用于遍历目标文件的链表,linux系统中很多情况下都这么做。但是需要注意的是,遍历过程有一些特殊的技巧和约束。
1对文件路径的字符长度有要求
2对文件命名的方式有要求
3节点可以使用硬链接和软连接指向一个目录(但有链接数要求)
4“/”表示一个节点的结束“.”表示当前目录,“..”表示上一目录
5遍历过程并非直接遍历到文件,而是遍历到文件的上一级目录,这样可根据特定的参数来判断是否当文件不存在时是否应该创建。
6遍历的过程可以理解为是对fs数据结构进行遍历,但是到找到文件后,并需要建立进程与打开文件的信息的话,那么就意味着需要建立file数据结构了,其过程见系统文件逻辑结构图。
5.3访问权限与文件安全
一个好的操作系统,不仅要帮助用户高效的管理计算机,同时必须保证用户信息的安全性,那么文件安全无疑是很关键的,所以linux具备文件安全性,有一套访问权限设计。
首先对文件的分类有,可读,可写,可执行。
对用户也进行了分类有,超级用户,同组用户,普通用户
那么对于上面进行组合就有9中不同的方式,linux用三组三位二进制数表示三种不同用户对一个文件的操作权限。
同样进程控制块中也会提供用户的类型,如task_struct中有euid,egid,suid,sgid,此外uid为0表示超级用户。只有超级用户以及具备特权yoghurt权限的进程才能通过系统调用来改变其用户号和组号。
这里需要说明的就是用户的改变,在我用普通用户登入系统后,系统会为用户分配一个Session,也就标识了我是普通用户,其实我是不具备超级用户的权限的。我们su命令只是为普通用户执行了一个set_uid可执行程序,它的文件主死root,即特权用户,所以普通用户执行su的过程就具备了特权用户的权限(这也就给系统带来了一些风险性)。
5.4文件系统的安装与拆卸
在linux系统中(不光是linux)很多功能都是以模块的形式封装起来,具体使用的再把其加载进来,而且对功能模块可以有选择性的安装了,如linux对不同文件系统之间的支持,可以通过sys_mount安装,sys_umount卸载。文件系统的安装过程主要有
1检查设备的正常性
2对文件的权限进行检查
3建立文件系统(就是建立文件系统的逻辑结构)
4添加到虚拟文件系统
5.5文件的打开与关闭
前面已经介绍了从路径到文件一节中已经通过文件的路径找到了文件,那么找到文件之后需要建立进程与文件的关系无疑是必须的,这一步有文件的打开来实现,task_struct结构中有一个文件指针file用来指向已打开的文件,而这个数据结构中又包含dentry结构,下面还有idone,建立打开文件的过程就是完成这么一个庞大的文件系统结构,打开的过程需要做一系列的检查,知道建立完这么一个数据结构,最好就是建立文件系统结构与用户空间页面的映射,也就是把文件中的内容映射到虚拟空间页面上,进程的执行过程从逻辑上来讲是运行在虚拟空间,而实实在在的指令和数据都在文件中,那么可见建立文件与虚拟空间的关系是关键,当然最后进程的运行还是在内存上,所后面要需要建立虚拟空间域物理空间的映射,这就是前面讲的地址映射了,相反关闭的过程就需要释放打开的占有的资源。
5.6文件的写与读
文件打开后,与具体的进程建立好联系后,那就就可以开始对文件进行操作了,千万别忘了,我们建立联系时有一个file_op指针,它指向该文件的允许操作的数据结构指针,里面提供文件操作的函数指针。所以我们才能对文件进行读写操作,操作的过程并不难,也不是关键。关键的问题是当一个文件与多个进程建立联系后,那么多个进程多一个文件的读写操作就必须具备互斥操作,即一个文件可以被多个进程读,但不能被多个进程同时写。所以说,信号量和锁的作用又体现出来了。然后要注意的一点就是,进程对文件的操作并不是直接操作的。前面我们也讲过页面置换过程中有个会写的操作,就一点就说明我们进程直接操作的页面不是文件上的页面,而是映射到内存之后的页面,因为磁盘和内存的读写速度相差太大。所以这里的读写操作都是在内存上的操作,而并非直接在文件上的。
5.7其他文件操作
这里所介绍的文件的其他操作主要是,对文件内部额操作,比如文件的读写指针,从什么地方开始读写文件。系统中专门提供一个sys_lseek系统调用来实现这一操作,具体不做介绍了,看代码。
5.8特殊文件系统 /proc
前面介绍三类文件中讲到过特殊文件,特殊文件有fifo,socket,proc… 他们很重的一个作用就是用于进程通信。当然通信功能我们留到进程通信一章中介绍,这里只介绍/proc文件系统
先谈谈proc文件系统的作用吧,每当创建一个进程时,就以进程的pid在该文件目录下建立一个特殊的文件,使得通过这个文件就能读写相应进程的用户空间,那么这样的作用就是能清楚的知道进程做了些什么了,这毫无疑问具备了debug的功能了。
当然要使用这个文件系统之前,必须先建立这么一个文件系统,系统初始化阶段对proc文件系统做两件事,一是向系统登记proc文件系统,而是通过kern_mount将一个具体的proc文件系统安装到系统的/proc结点上。同样也是一个建立文件系统逻辑数据结构的过程。
6进程通信
6.1概述
进程是程序运行的一个实例,一个程序至少有一个进程,多个进程之间必然需要协同通信一起完成任务,所以进程通信也是进程管理的一个关键部分。
目前,进程通信的方式主要有以下几种
管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程,兄弟进程关系。
有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信
信号( semophore ) : 信号是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
套接字( socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。下面一一介绍其工作机制
6.2管道
管道机制的主体是系统调用pipe(),但是有pipe()建立的管道的两端都同一个进程,所以必须在fork()的配合下,才能在父子进程,兄弟进程之间建立起通信。
管道的创建是通过文件来实现的,这也就是前面讲到的进程通信借组了文件系统。
所以创建管道的过程需要创建一个文件,即分配目录项dentry和节点idone。但是一开始创建的管道读写两端都在同一个进程中,那么就需要fork()系统调用创建子进程后,由子进程继承父进程的管道,然后再把父子进程中的一端读和写关闭,这样一个进程只能读,一个只能写,这就有了进程通信的实体了,当然是半双工。
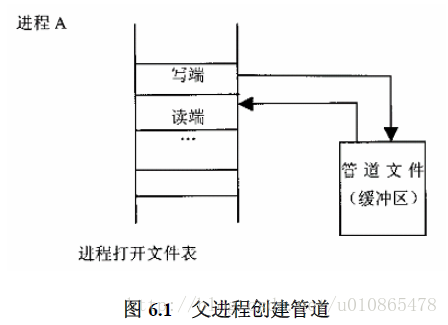
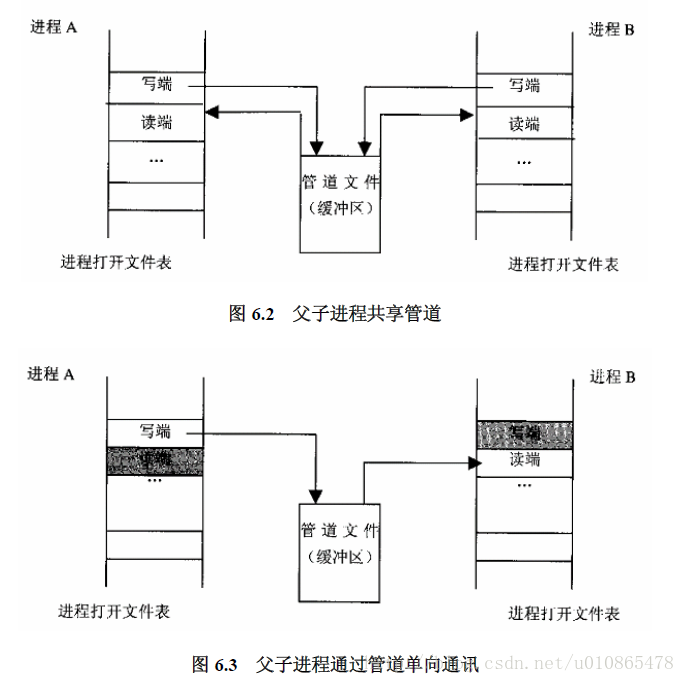
然后建立好管道后,进程之间就有俩通信的实体了,但是还缺少通信规定,管道文件设计为缓冲区,一个进程负责往里面写数据,一个进程负责往里面读数据,那么就涉及到缓冲区为空和缓冲区满的两种特殊状况,那么这里面就有一个进程同步问题了,即缓冲区为空,则读进程睡眠,若缓冲区满了,则写进程睡眠,直到对方唤醒自己。
6.3命名管道
管道通信只能用于特定关系的进程之间,为了实现任意进程通信,所以就提出了命名管道,为了实现有名管道,设立了一种文件类型即fifo文件,需要注意的是该类型文件严格遵循先进先出的原则,不允许lseek()操作来移动文件内部读写指针的位置。进程通过命名管道通信的实现过程就是,把需要通信的进程和fifo文件建立映射,通信机制和管道一样。
6.4信号
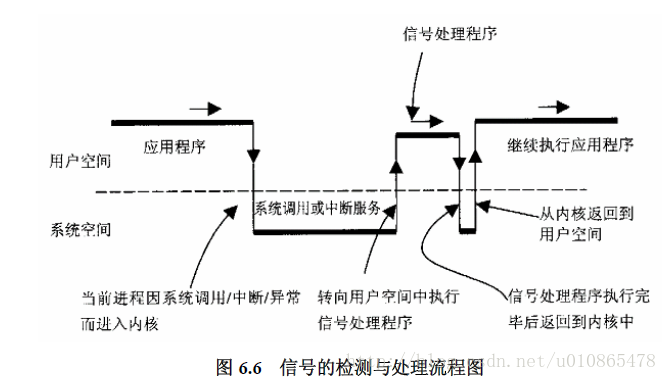
注意,信号一定要和信号量区别理解,信号是异步的,信号量是同步的,信号可以理解为一种软中断,就是系统或者进程通过软件的方式设定好一个信号,当有进程或系统发起信号请求时,那么就会触发一段特定的程序来执行(不一定要立即执行),相当于系统安排好了一段程序等待信号到了后不慌不忙的执行。为什么说不慌不忙,那是因为当前进程可以继续执行下去,直到进程从用户空间进入系统空间后,才会去检查信号,有则是调用信号处理程序,然后回到系统空间。
6.5消息队列(报文传递)
其实从实现过程来说,称为消息队列更合适。考虑到信号所能承载的信息量小,管道的开销大(如建立一个文件结构)信息不具备一定的格式,后来就提出了消息队列,消息队列的好处是信息可以有格式读取,信息量不小,而且开销小,就是建立一个消息队列而不需要建立一个文件节点。消息队列就好像信箱来信了一样。其过程如下
1建立消息队列msgget()
2消息发送msgsnd()
3消息的接收msgrcv()
4消息机制的控制和设置msgctl()
6.6共享内存
从上面的几种实现进程的通信方式来说都是通过借助一些东西来帮助实现进程之间的通信,如文件,队列。那么共享内存无疑是最直接,高效的通信方式了,它能实现需要通信的进程可以访问同一块内存空间。但需要注意的是这里说的内存空间不是只物理空间,因为对程序来说,虚拟空间就是进程执行的空间。别忘了,进程创建的使用有一个mm__struct结构,用来建立进程虚存空间的映射,如也就是说建立好虚存空间映射,那么由虚存空间映射到物理空间就自然而然啦。
具体过程如下:
1共享内存区的创建与寻找
2建立共享内存映射(虚存映射)
3撤销共享内存的映射
4对共享内存区的控制与管理
6.7 信号量
信号量常用于进程同步,信号量可以用来表示临界区,有限资源的访问,信号量设置初值后,每使用一次执行down(),执行完释放一次执行up(),每次使用资源前徐检查资源是否够使用,不够则进入睡眠等待,其他的进程使用完释放后有资源后再唤醒。
7 socket
进程通信发展过程中两大主力推动是来至AT&T和BSD,前面介绍的几种进程通信的方式来至AT&T,基本上都是致力于实现本机中进程中的通信,而BSD尽管做的不多,但可以说是思维的扩展,而不着重与本机间进程通信,socket通信不仅可以用于本机进程之间通信,同样适用于网络上不同计算机节点之间的进程之间通信。Socket本机通信的方式与报文队列方式相似,数据是有结构的报文。故名思议,socket就好像一个通信线的插口,而在文件系统中又扮演这一种特殊的文件socket。一个插口上逻辑上有三个特征,网域,类型,规程。同样对应着创建一个socket即需要这三者。
网域:是指名插口属于哪一种网络,如AF_INET表示互联网,AF_UNIX表示本地。
类型:网络通信有两种主要的模式,一种是“有连接”,一种是“无连接”,有连接方式就像在通信的两端建立了“虚电路”,保证来哦传递的可靠性与有序性,而无连接方式通信之前不需要建立连接,每个报文都是孤立的,对用户做出尽力传递,但无法保证。
规程:放在网络上来讲,就是我们的网络层协议,如AF_INET中的无连接的规程基本上就是UDP。
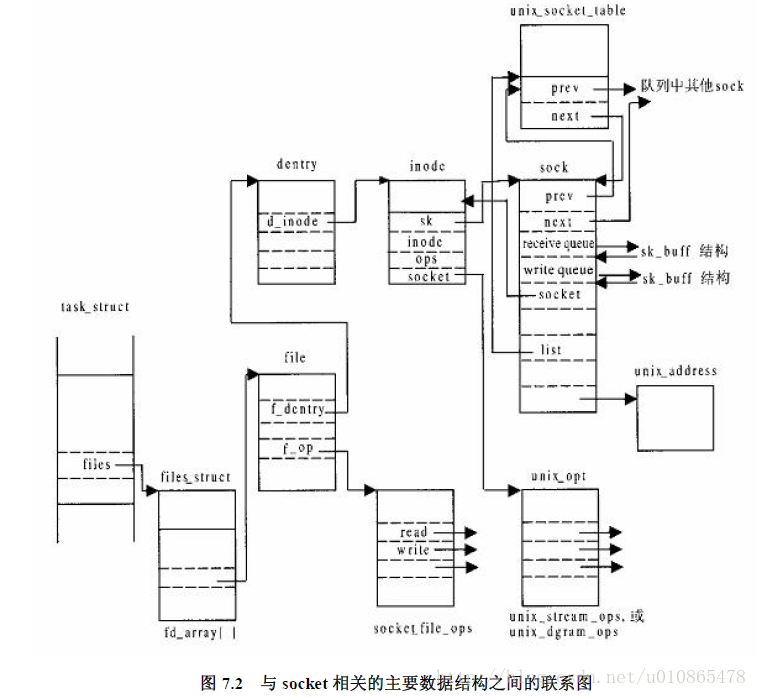
Socket进程通信实现
1 插口的创建与撤销
SYS_SOCKET:
int socket(int domain, int type, int protocol);
其中,domain 参数指定协议族,对于本地套接字来说,其值须被置为 AF_UNIX 枚举值;type 参数指定套接字类型,protocol 参数指定具体协议;type 参数可被设置为 SOCK_STREAM(流式套接字)或 SOCK_DGRAM(数据报式套接字),protocol 字段应被设置为 0;其返回值为生成的套接字描述符。其创建过程同样需要建立socket文件系统逻辑结构。
SYS_BIND:
int bind(int socket, const struct sockaddr *address, size_t address_len);
将代表一个插口的文件号与某个域中的可寻试题或插口地址绑定
SYS_SOCKEPAIR:创建一对互相连接的无名插口
SYS_SHUTDOWN:部分或完全关闭一个插口
2插口间连接的建立
SYS_LISTEN:作为server的以防首先通过listen()向内核挂号
SYS_CONNECT:在有连接模式中,client一方需要connect()向以挂号的server方插口请求连接。
SYS_ACCEPT:server方通过accept()接受或等待接收来的第一个连接请求。
3报文的发送与接收
对于有连接模式,可以直接使用文件操作中的read和write直接对socket操作,像文件一样接收和发送消息。除此之外,有连接和无连接方式都可以使用socket通信的专用消息处理调用,recv/send,recvfrom/send_to,recvmsg/sendmsg。
同步与异步的区别
查了很多资料,仔细分析过,同步和异步的去别还不是很明白,只是有一个简单的想法,异步就像是突发事件来了,已经安排好了时间的处理程序,执行流不停下来,等到合适的时间再去执行处理程序。同步就是事件来,不一定说马上处理,但是当前的执行流几乎不能做什么,而是转去执行事件处理(不一定是说处理程序,而是执行流需要切换)。下面是一个参考资料
http://jingyan.baidu.com/article/295430f1cbfa8f0c7e0050ab.html
8设备驱动
这一节就不怎么介绍了,我也没看,时间有限,基本上是和硬件打交道,模块开发,是系统框架的底层实现,有一个高度的了解就行吧,所以就按目录方式高度概括吧。
8.1概述
8.2系统调用mknod()
8.3可安装模块
8.4PCI总线
8.5块设备驱动
8.6字符设备驱动概述
8.7终端设备与汉字信息处理
8.8控制台的驱动
8.9通用串行外部总线USB
8.10系统调用select()以及异步输入/输出
8.11设备文件系统devfs
9多处理器SMP系统结构
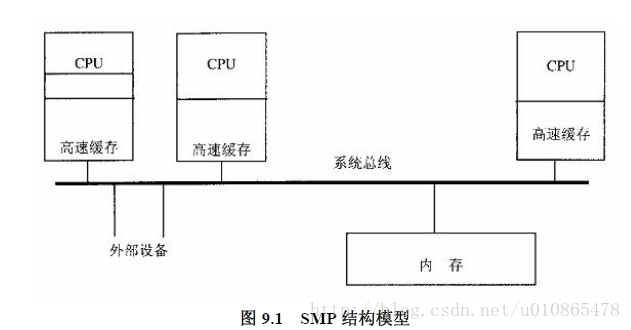
多核结构适合于提高系统的总吞吐量,但是各个进程则互相独立,所以为了提高计算机解决大问题的速度,则取决于是否存在一个好的并行性算法。
但是,我们大多数进程之间还是需要同步协调工作的,那么他们之间必然存在关系,在单核中,我进程之间的互斥机制可以通过信号量来实现,但是到了多核显然不那么简单,因为信号量的使用是针对单核,只考虑一个cpu程序的执行,而多核则必须考虑多个cpu的运行。所以多核虽然给我们带来了速度,但也带来了复杂度。前面介绍过锁的概念,其中有一种自旋锁就是通过锁住一个cpu来实现互斥访问临界资源,以实现进程同步的问题。
9.1 SMP结构中的互斥问题
9.3 高速缓存与内存的一致性
9.4 SMP结构中的中断机制
9.5 SMP结构中的进程调度
9.6 SMP的系统引导
10系统启动
关于系统的启动,以前也学习过,不过从此书中我再次看到系统启动后,在以前的认识上有了一个新的认识,就是建立在前面的基础上,我么可以说系统是启动了,但是linux没有完全初始化,而linux的初始化过程又可以分为三个阶段。其实之前的介绍可以看作是一个系统的引导过程。
1把linux内核映像装入到内存
2linux系统基础建设,如分页机制中的页表项
3内核线程init()的启动,中断,异常,映射机制,进程调度,时钟的初始化
好吧,最后还是向大家极力推荐linux内核源代码情景分析这本书,此书非常适合想深入理解操作系统的同学阅读,虽然刚开始阅读会有点不适应,因为和我们平时的教材书不大一样,因为教材书可以说是站在一个比较高的层次高度的概括,没有深入的介绍实现,而且文字上不是很严格,有些地方让人模棱两可,粗暴点说就是权威性不足。而此书不仅具备高度概括性,而且有情景代码供读者细究,严谨性非常强,给读者一种这就是对的感觉,而且分析非常到位。因为此书是基于linux2.4.0版讲解的,不说涵盖操作系统的大量技术吧,也可以说涵盖了很多基本的操作系统设计思想吧。当然比0.11版阅读起来有难度,老实说,此书看到第二章我就看不下去了,想换一本深入理解linux内核书来看的,但是当我换着看的时候,我发现在此书中看到的一点点东西,结果我在另外一本书中要看一章才算看完,也就是说此书的一点点内容就包含了很多其他书需要用大量文字来表达的东西,于是我觉得再次捡起此书,硬着头皮,慢慢的,一点一点的看下去。此书情景分析是一个难点,但也是其优点,因为当我一直纠结这段文字表达的意思的时候,我回过头仔细分析代码时就能领了其意思了,给我一种完全信服感。此书可以看出作者对linux有非常长的研究和积累,才能高度提炼出这些关键情景代码,让我们看到这些好东西,我们都应该珍惜老师的成果。此书的确可以作为linux操作系统学习的宝典,也可以作为平时的参考资料,具备权威性,和国外的一些经典书籍不差,而且语言风格上和我们传统类似,易于理解,不存在翻译过程中的直译让人费解。好了,推荐完本书后,我就得说说我阅读此书的心得吧,可以说为什么我想学习操作系统呢,完全是因为我喜欢计算机,虽然我知道我以后搞系统开发的可能性不大,但是操作系统中有很多值得我学习的东西,而且能解惑。想想,要是我写一辈子的程序却不知道程序到底是怎么运行起来的,只是会不停的编码,那多么没劲了,就好像我们活一辈子下来,不知道为什么活着,那多尴尬啊!我想这也是一种求知欲吧!虽然说看完这本书不能说就完全理解操作系统,但是起码有了一个更深的认识。原本打算读完希望看得懂linux代码,理解操作系统的思想以及设计实现的,看完后我发现后者我基本算完成,前者不好说,说看的懂肯定是没问题,但是一个整体放在那,那看起来我想我会崩溃,如果真的说要知道代码每一段的实现,以及设计思想,我想没有二三年的研究是不可能的了,所以看完此书后,我觉得我最大的收获就是linux设计思想和实现过程,当然也包括一些linux程序设计语言C风格,嵌入式汇编等,所以所收获还是不少的。但是有了收获,如果不总结,不分享,我就觉得是一种浪费,就好像刚磨好的刀不用,等它生锈一样。所以我就稀里糊涂的写了这么多的文字。但是我觉得还是非常不错的,起码说清楚了操作系统设计思想,当然如果想深入理解的话还是推荐看原书,相比较原书,我只是做了一些自己的总结,完全微不足道,而且很多图为了方便都是从原书上截下来的,所以凡是没指明出处的图表,都来至此书!友情建议:本文最多算是一个linux学习总结,如有同学想深入了解操作系统,还是选本合适的参考书深入学习!