我的BOSS(一位深圳大学毕业了好几年的资深工程师~主攻Machine Learning)一直有跟我说过关于机器学习的东西,但是我仅仅是了解而已,并没有深入的去研究(暂时还没有这个能力)。为了以后打下很好很好的基础,决定现在慢慢的去了解机器学习 ~ 今天先来一篇之前他跟我说过的一丢丢知识 (来源于 网络+自己理解)~
什么是机器学习
Langley(1996) 定义的机器学习是“机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。(Machine learning is a science of the artificial. The field’s main objects of study are artifacts, specifically algorithms that improve their performance with experience.’)
Tom Mitchell的机器学习(1997)对信息论中的一些概念有详细的解释,其中定义机器学习时提到,“机器学习是对能通过经验自动改进的计算机算法的研究”。(Machine Learning is the study of computer algorithms that improve automatically through experience.)
**Alpaydin(2004)**同时提出自己对机器学习的定义,“机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。”(Machine learning is programming computers to optimize a performance criterion using example data or past experience.)
我觉得一张图就已经基本了解了机器学习:

//图片来源于万门大学
监督学习:
1、 分类问题:输出为离散值的问题
- 明年会不会涨工资
- 能不能申请转学校
- 能不能赢球
2、回归问题:输出为连续值的问题
- 明年工资是多少
- 明天比特币价格是多少
- 能赢多少个球
3、思考题:中国球队能进多少个球是分类还是回归问题?
- 这个可以从分类问题去分析,也可以通过回归问题去解析。我们的目标是预测中国队是否能赢球?所以这两类都可以去分析,看那个好就用那个!
分类问题
问题描述:明年能不能申请去其他学校
1、特征(条件):
- 成绩(GPA,排名)
- 本科/高中学校
- 科研成果
- …

收集多组数据

y0 = x0 + b1x1 + b2X2 + b3x3 + b4x4 + b5x5
y = 1 if y0 > c
0 otherwish
建立线性回归模型
- 优点:简单、直观、计算快
- 缺点:分类阈(yu)值没有直观解析
线性回归(系数)

线性回归(logistic回归)
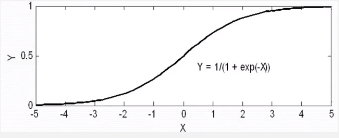
y0 = 10x1 - 30X2 + 10x3 + 3x4 + 0.01x5- 45;
y = 1 / ( 1 + exp(-y0) )
建立logistic回归模型
线性回归(树)

- 优点:模型直观
- 缺点:过拟合
过拟合(overfitting)
为了得到一致假设而使假设变得过度严格。
给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上H的错误率比h’小,但在整个实例分布上h’比H的错误率小,那么就说假设H过度拟合训练数据。
一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。
如图:

可以看出在a中虽然完全的拟合了样本数据,但对于b中的测试数据分类准确度很差。而c虽然没有完全拟合样本数据,但在d中对于测试数据的分类准确度却很高。过拟合问题往往是由于训练数据少等原因造成的。
解决方法:
(1)在神经网络模型中,可使用权值衰减的方法,即每次迭代过程中以某个小因子降低每个权值。
(2)选取合适的停止训练标准,使对机器的训练在合适的程度;
(3)保留验证数据集,对训练成果进行验证;
(4)获取额外数据进行交叉验证;
(5)正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
过拟合验证->交叉验证:

- 将数据分成训练组、验证组、最终测试组
- 用训练组找出模型
- 用验证组测试模型表现,挑选模型与超参数
- 最终测试组检查模型效果
分类问题(随机森林)
利用多棵树对样本进行训练并预测的一种分类器

要说随机森林,必须先讲决策树。决策树是一种基本的分类器,一般是将特征分为两类(决策树也可以用来回归,不过本文中暂且不表)。构建好的决策树呈树形结构,可以认为是if-then规则的集合,主要优点是模型具有可读性,分类速度快。
一个决策树的构建,逻辑可以用下图表示:
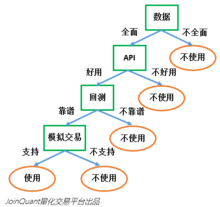
决策树的主要工作,就是选取特征对数据集进行划分,最后把数据贴上两类不同的标签。如何选取最好的特征呢?还用上面选择量化工具的例子:假设现在市场上有100个量化工具作为训练数据集,这些量化工具已经被贴上了“可用”和“不可用”的标签。
随机森林构建
决策树相当于一个大师,通过自己在数据集中学到的知识对于新的数据进行分类。但是俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
那随机森林具体如何构建呢?有两个方面:数据的随机性选取,以及待选特征的随机选取。
那随机森林具体如何构建呢?有两个方面:数据的随机性选取,以及待选特征的随机选取。
1、数据的随机选取:

首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。如下图,假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A类
2、待选特征的随机选取
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
1.分裂:在决策树的训练过程中,需要一次次的将训练数据集分裂成两个子数据集,这个过程就叫做分裂。
2.特征:在分类问题中,输入到分类器中的数据叫做特征。以上面的股票涨跌预测问题为例,特征就是前一天的交易量和收盘价。
3.待选特征:在决策树的构建过程中,需要按照一定的次序从全部的特征中选取特征。待选特征就是在目前的步骤之前还没有被选择的特征的集合。例如,全部的特征是 ABCDE,第一步的时候,待选特征就是ABCDE,第一步选择了C,那么第二步的时候,待选特征就是ABDE。
4.分裂特征:接待选特征的定义,每一次选取的特征就是分裂特征,例如,在上面的例子中,第一步的分裂特征就是C。因为选出的这些特征将数据集分成了一个个不相交的部分,所以叫它们分裂特征。
下图中,蓝色的方块代表所有可以被选择的特征,也就是目前的待选特征。黄色的方块是分裂特征。左边是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征,完成分裂。下图是一个随机森林中的子树的特征选取过程。

上面一大堆东西看起来也挺烦的,总的分为三点:
1、搞一颗随机的树
2、搞很多…
3、取平均/投票
2、标记(结果):
- 成功
- 失败
关于机器学习基础还有一部分内容,下次有空再说…
- 无监督学习
1、主值分解(PCA)
2、聚类算法 - 神经网络
- AlphaGo算法(比较新)