在对数据进行建模的过程中,为了评估模型预测准确性。需要将原始数据划分成训练集和测试集两部分(若数据量足够大,也可以划分为训练集,验证集和测试集三部分)。其中训练集用于训练模型(学习器),测试集用于评估模型优劣性。本文总结了几种数据分割的方法,供大家交流学习。
测试集与训练集的比例没有统一规定,一般视样本量的多少训练集与测试集划分比例为3:1-4:1。
这里我按数据类型是否包含因子类型分成两种类型讨论。这是因为含有因子变量的数据需要分层抽样才能保证训练集和测试集中都含有该因子的所有水平。如果训练集中含有某水平,测试集中不含有该水平,那么预测的时候就会出错。
1.纯数值型数据类型的分割-随机采样
纯数值型数据类型分割时可以采用随机抽样进行分割。这里我们采用R自带的iris数据集。
#加载数据
data(iris)
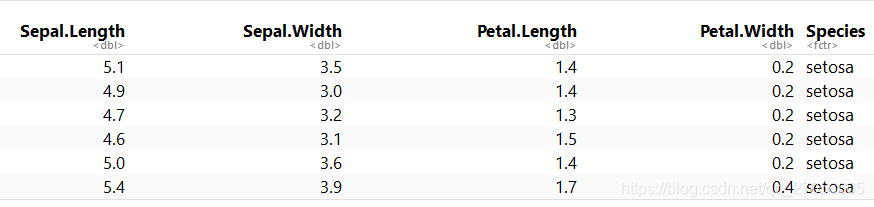
head(iris)
#去掉Species项,因为该项为因子型
iris.removeSpecies=iris[,!names(iris)%in%c("Species")]
此图为了展示iris部分全貌,没有去掉Species项,不要弄错了。
方法一:
#有放回的从x中(即1和2)选择size个数据,选择1的概率为0.8,选择2的概率为0.2,
#并返回由1,2组成的向量
ince=sample(x=2,size=nrow(iris.removeSpecies),replace=TRUE,prob=c(0.8,0.2))
table(ince)
trainset=iris.removeSpecies[ince==1,]
testset=iris.removeSpecies[ince==2,]
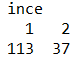
方法二:
set.seed(1234)#这句可以不要,只是保证大家得到的数据跟我的一致
num=nrow(iris.removeSpecies)
#从1:num中无放回随机选择size个数,然后将这几个数返回
ince=sample(x=1:num,size=num*0.8,replace=FALSE)
head(ince)
trainset=iris.removeSpecies[ince,]
testset=iris.removeSpecies[-ince,]

方法三:
set.seed(1234)
num=nrow(iris.removeSpecies)
#将数据集划分成breaks份,并返回一个向量
ince=cut(x=1:num,breaks=4,labels=FALSE)
ince
trainset=iris.removeSpecies[ince!=1,]
testset=iris.removeSpecies[ince==1,]

2.含有因子类型数据的分割-分层采样
这里我们不再去掉Species列,由于该项为因子变量,为了保证分割后训练集和测试集都包含该列所有的水平,我们以该列为分割依据。
方法一:
library(caret)
set.seed(1234)
#参数y指定划分的列依据,p指定训练集的比例,list为FALSE指定返回值为向量,而非列表
ince=createDataPartition(y=iris$Species,p=0.8,list=FALSE)
table(iris$Species)
trainset=iris[ince,]
testset=iris[-ince,]
table(trainset$Species)

从输出结果中可以看出,createDataPartition函数实现了分层采样,也就是说对于每个水平,训练集和测试集都会得到相应比例的水平值。这样就避免可能因为有些水平数目过少而不会出现在测试集的情况。
方法二:
#这个包可能通过RStudio直接无法下载,需要在官网上找到zip文件,本地安装。原因你懂的。
library(caTools)
set.seed(1234)
ince=sample.split(Y=iris$Species,SplitRatio = 0.8)
table(iris$Species)
trainset=iris[ince,]
testset=iris[-ince,]
table(trainset$Species)

和上面的结果一样,不再赘述。
3.仍然存在的问题
对于有些数据集,有多列因子变量,即使选中某列作为分割列,也可能导致其他因子列某些水平不能被划分到测试集,使预测失败。这些原因多是因为那些列的因子水平过多,或者某些水平数量过少。这样的数据组合不合理,实际上可以删掉一些水平数量太少水平。除了这个方法,我还没找到解决的办法,希望大家能够提供更好的办法。
欢迎关注个人微信公众号:moisiets。数据小丸子。
源代码获取可加QQ群:962096290。
