前言
上一节介绍了有关rabbitmq里面常用了几种命令,以及交换机的路由规则等,生产端以及消费端之间的伪代码来介绍了各种路由规则下的消费情况,从管控台的设置,数据分析,了解到如何手动设置vhost下的交换机以及用户,队列等。这节开始就rabbitmq的高级特性进行详细的介绍,比如TTL,死信队列,限流,ACK以及失败转移等生产中常用到的特性。这里贴上一篇分析rabbitmq源码的博文供读者有余力的话来自行修行,另外在CSDN另外一端有提及到rabbitmq专题的更详细介绍,读者也可前往深入研究。
消息如何保障100%的投递成功?
这里投递成功的意思是生产端生产消息到broker,然后broker如何对生产端进行回应接收到的过程,这里就需要采取一定的消息补偿机制, 比如可以采用对消息进行入库状态的标志,如果成功返回应答消息的进行状态的变更,否则就对消息进行轮询的发送处理,直到发送消息在努力尝试的次数内得到最大的成功几率,这个还是需要看并发量,以及数据量,这个目前在笔者的项目中领导是要求达到并发量是200万左右,这个就就需要用到消息的可靠投递的处理。
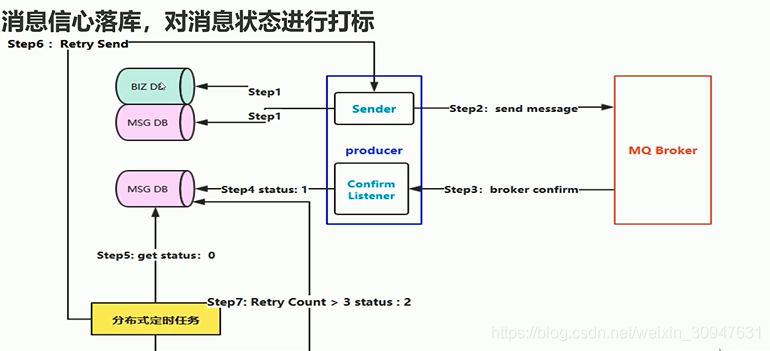
这里是对消息可靠处理的一种方案,首先消息先入库的操作然后再进行发送的环节,step1是数据入库,这里的入库包括业务类型入库,以及发送的消息入库,这里没有事务异常的持久化到磁盘后就进行step2发送消息到broker,step3是broker的应答过程,这里可以通过定时任务来设置,消息如果没有在规定的时间内发送回来应答就快速失败。step4就开始异步的监听ACK,从这里开始就对库里面的消息的状态进行处理,如果broker收到就更改消息发送状态。而最重要的一步是step5-6,针对消息的状态进行重试投递尝试,这里可能会出现一种情况是刚刚发送消息而broker没来得及应答,这里就开始尝试重试发送,所以这里就需要对消息超时的容忍做为过滤条件,再做step6就会比较合适,而step7是对重试的限制,留给人工处理的补偿,来解决极端问题,比如网络问题,业务问题等等。
架构图出来之后,这里就需要在高并发场景下又如何处理?数据库能否承受得这种频繁的入库操作?显然,这样的设计还是存在瓶颈。于是有了下面的架构方案来处理。
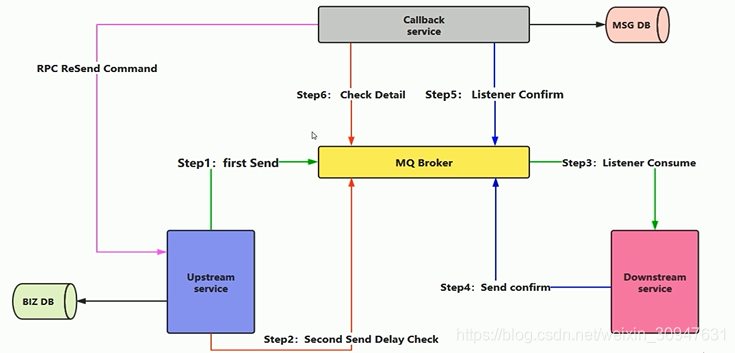
从下图的这个方案,大致可以分为三个过程,第一个过程,蓝色的方框,是处理订单业务入库的操作,这时候,有业务请求,先做持久化,记录下ID,然后再发送消息,发送了消息之后,消费端通过监听mq集群q1,处理订单业务,处理完了之后就发送消息给mq集群的队列q2,提示订单完成了,第二个过程是最上方的灰色做一个回调的监听,监听到粉色的消费端消费的信息,然后马上做持久化入库的操作,把业务订单入库,第三个过程是蓝色的订单服务发送延时检查消息消费情况(可以设置5分钟或者30分钟,高峰时期可以根据实际数据量来自定义延时查询时间)的请求到mq集群q3,灰色的回调服务监听到延时的检查请求消息,马上从数据库查询ID的订单的消费状态,如果没有查询到ID的订单信息或者该订单消费失败,就通过RPC的方式进行调用订单服务重新发送消息,进行补偿。这样的三个过程就可以减少了数据库的操作,消息得到可靠的同时,性能得到提高
总结
在实际的生产里面,是需要结合很多nosql数据库进行处理,比如这里的订单服务的入库操作可以使用redis集群来处理,这样的效率更高,而RPC的调用也有可能出现网络问题而导致请求重发失败的情况,虽然这种情况还是极少数的,但是以防万一,所以后面的还是需要人工补偿来处理这个问题,比如这里的延时申请,怎样才能确保消息已经消费入库,如果消息被消费端消费了,但是这个灰色的回调入库异常的情况?如果消息没有消费,需要补偿的话,出现网络问题导致RPC请求失败的情况?有兴趣的读者可以发表你的见解。