- 保证消息不丢失,可靠抵达,可使用事务消息,性能下降250倍,为此引入确认机制
- publisher confirmCallback确认模式
- publisher returnCallback未投递到queue退回模式
- consumer ack机制

保证消息的百分百投递成功。
1 Producer 的可靠性投递
1.1 要求
- 保证消息的成功发出
- 保证MQ节点的成功接收
- 发送端收到MQ节点(Broker) 确认应答
- 完善的消息补偿机制
在实际生产中,很难保障前三点完全可靠。在极端环境,生产者发送消息失败,发送端在接受确认应答时突然发生网络闪断等,很难保障可靠性投递,所以就需第四点完善的消息补偿机制。
1.2 解决方案
方案一:消息信心落库,对消息状态进行打标(常见方案)
将消息持久化到DB并设置状态值,收到Consumer的应答就改变当前记录的状态.
再轮询重新发送没接收到应答的消息,注意这里要设置重试次数.
方案流程图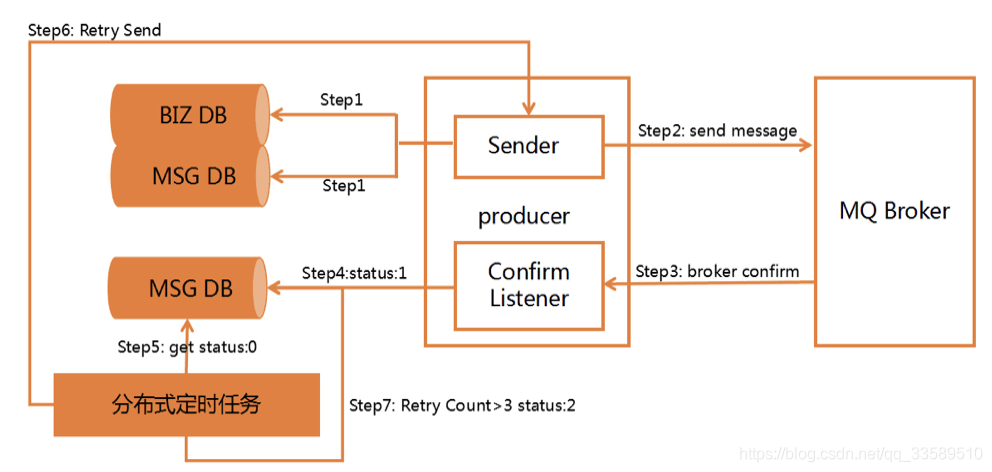
方案实现流程
比如我下单成功
step1 - 对订单数据入BIZ DB订单库,并对因此生成的业务消息入MSG DB消息库
此处由于采用了两个数据库,需要两次持久化操作,为了保证数据的一致性,有人可能就想着采用分布式事务,但在大厂实践中,基本都是采用补偿机制!
这里一定要保证step1 中消息都存储成功了,没有出现任何异常情况,然后生产端再进行消息发送。如果失败了就进行快速失败机制
对业务数据和消息入库完毕就进入
setp2 - 发送消息到 MQ 服务上,如果一切正常无误消费者监听到该消息,进入
step3 - 生产端有一个Confirm Listener,异步监听Broker回送的响应,从而判断消息是否投递成功
- step4 - 如果成功,去数据库查询该消息,并将消息状态更新为1
- step5 - 如果出现意外情况,消费者未接收到或者 Listener 接收确认时发生网络闪断,导致生产端的Listener就永远收不到这条消息的confirm应答了,也就是说这条消息的状态就一直为0了,这时候就需要用到我们的分布式定时任务来从 MSG 数据库抓取那些超时了还未被消费的消息,重新发送一遍
此时我们需要设置一个规则,比如说消息在入库时候设置一个临界值timeout,5分钟之后如果还是0的状态那就需要把消息抽取出来。这里我们使用的是分布式定时任务,去定时抓取DB中距离消息创建时间超过5分钟的且状态为0的消息。
step6 - 把抓取出来的消息进行重新投递(Retry Send),也就是从第二步开始继续往下走
step7 - 当然有些消息可能就是由于一些实际的问题无法路由到Broker,比如routingKey设置不对,对应的队列被误删除了,那么这种消息即使重试多次也仍然无法投递成功,所以需要对重试次数做限制,比如限制3次,如果投递次数大于三次,那么就将消息状态更新为2,表示这个消息最终投递失败,然后通过补偿机制,人工去处理。实际生产中,这种情况还是比较少的,但是你不能没有这个补偿机制,要不然就做不到可靠性了。
思考:该方案在高并发的场景下是否合适
对于第一种方案,我们需要做两次数据库的持久化操作,在高并发场景下显然数据库存在着性能瓶颈.
其实在我们的核心链路中只需要对业务进行入库就可以了,消息就没必要先入库了,我们可以做消息的延迟投递,做二次确认,回调检查。下面然我们看方案二
2.1.2.2 消息延迟投递,两次确认,回调检查(大规模海量数据方案)
大厂经典实现方案
当然这种方案不一定能保障百分百投递成功,但是基本上可以保障大概99.9%的消息是OK的,有些特别极端的情况只能是人工去做补偿了,或者使用定时任务.
主要就是为了减少DB操作
方案流程图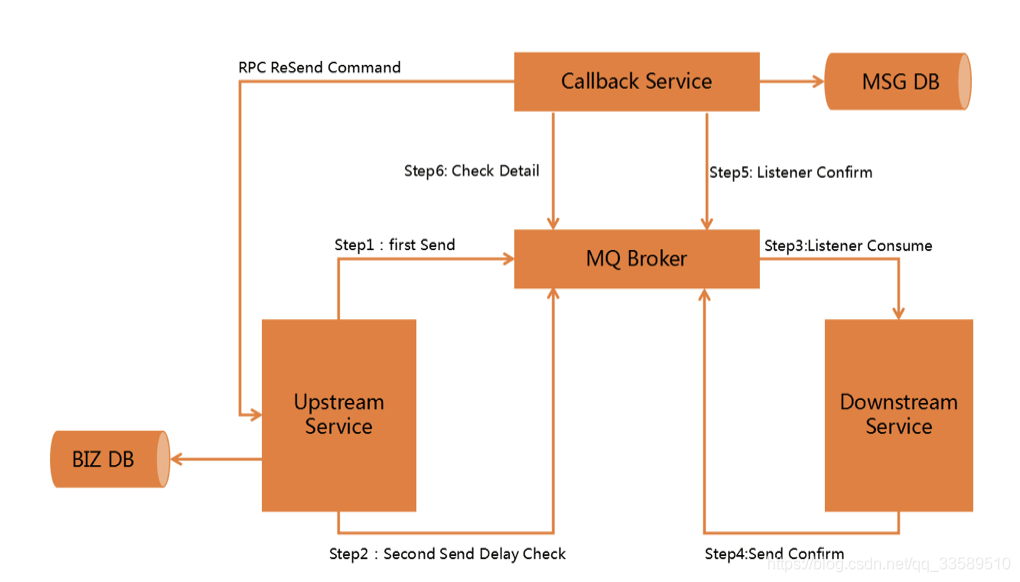
- Upstream Service
上游服务,即生产端 - Downstream service
下游服务,即消费端 - Callback service
回调服务
方案实现流程
- step1 一定要先将业务消息入库,然后Pro再发出消息,顺序不能错!
- step2 在发送消息之后,紧接着Pro再发送一条消息(Second Send Delay Check),即延迟消息投递检查,这里需要设置一个延迟时间,比如5分钟之后进行投递.
- step3 Con监听指定的队列,处理收到的消息.
- step4 处理完成之后,发送一个confirm消息,也就是回送响应,但是其不是普通的ACK,而是重新生成一条消息,投递到MQ,表示处理成功.
- Callback service是一个单独的服务,它扮演MSG DB角色,它通过MQ监听下游服务发送的confirm消息,如果监听到confirm消息,那么就对其持久化到MSG DB.
- step6 5分钟之后延迟消息发送到MQ,然后Callback service还是去监听延迟消息所对应的队列,收到Check消息后去检查DB中是否存在消息,如果存在,则不需要做任何处理,如果不存在或者消费失败了,那么Callback service就需要主动发起RPC通信给上游服务,告诉它延迟检查的这条消息我没有找到,你需要重新发送,生产端收到信息后就会重新查询BIZ DB然后将消息发送出去.
设计目的
少做一次DB的存储,在高并发场景下,最关心的不是消息百分百投递成功,而是一定要保证性能,保证能抗得住这么大的并发量。所以能节省数据库的操作就尽量节省,异步地进行补偿.
其实在主流程里面是没有Callback service的,它属于一个补偿的服务,整个核心链路就是生产端入库业务消息,发送消息到MQ,消费端监听队列,消费消息。其他的步骤都是一个补偿机制。
小结
这两种方案都可行。
需要根据实际业务来进行选择,方案二也是互联网大厂更为经典和主流的解决方案.但是若对性能要求不是那么高,方案一要更简单.